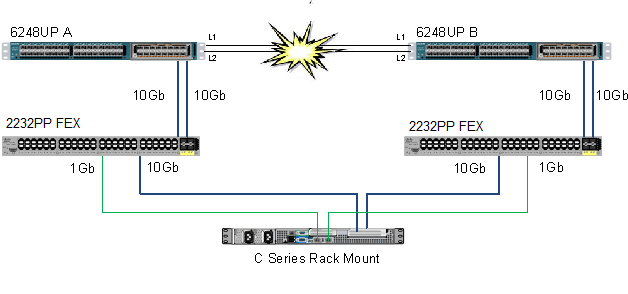
Hi All
As you all know I have been a Cisco UCS Specialist for the past 3 years, but I have recently also been made the Subject Matter Expert (SME) for Software Defined Networking (SDN) Now don’t worry I am still SME for Cisco UCS, so I’ll carry on blogging about that, but as this site says “Cisco UCS And Complimentary Technologies” I thought I would dump down my initial thoughts on SDN.
Just to Clarify in the 24 years I have been in IT I have been a Server Specialist, a Storage Specialist, a Virtualization Specialist and a Network Specialist, so have pretty much covered all of the bases within the Datacenter. All this experience gave me a great background for Cisco UCS and equally now for working on what SDN and Network Virtualization can bring to the Enterprise Datacenter.
Unlike Cisco UCS, SDN is a topic I am certainly no expert in (yet) but I have a huge passion for it, and find it really interesting. As such at present this is just my take on it, and how it may benefit the majority of my Customer base (The Enterprise Datacenter)
SDN, What you need to know about it (At the moment)
OK So I’m sure you have all heard of Software Defined Networking (SDN) by now, and if you haven’t you need to be aware of it, We all at least should have an opinion on it.
I have been following the evolution of SDN for about 18months now, and I’ve always felt it will have a major impact on how we design, build and manage networks, but I (like most) thought that the realities of SDN were probably still a good 5 years away, recent events and acquisitions have dramatically altered my view, and SDN (or variations of it) are already changing our industry.
In short if you believe the hype “The Iron Age” may soon be over
What I hope to do with this “Primer” is cut through the ever growing hype and misinformation around SDN and answer the simple questions that few seem to be asking or answering, mainly what will SDN Actually do for the Enterprise Datacenter?.
So What is SDN?
Simply put SDN is the separation of the Data Plane (packet forwarding) and the Control Plane (Inteligence) of the Network with dynamic programmability provided by a central controller. Basically an intelligent dynamically programmable Network.
What Problems is SDN Trying to solve
Moving packets from one point to another quickly and efficiently does not need addressing; The Networks as we know them today do this really well.
Moving them intelliently and adapting to dynamic changes in the Network on the other hand, can be a complexity nightmare or at least a big challenge, i.e. splitting flows by sending voice or trading events down the lowest latentcy path and data down another path, or secure tenant seperation in a dynamic multi-tenant environment, these are just some of the current challenges SDN could help with.
But the current main pain points around networking, is the flexibility, agility and management of the Network. In essence the Network is now perceived as “In the Way” as it has not evolved to provide the dynamic requirements of today’s virtualized workloads.
VLANs, VRFs, NAT, ACLs, QoS at present are quite manual tasks, which need to be configured across multiple devices usually by CLI.
So at present if a user wants an Application / server stood up; Through Virtualization we can do this within minutes, however the Connectivity, QoS, Security, Loadbalacing etc.. that the workload needs then becomes the bottleneck, as these are presently quite complex manual tasks which can take weeks to implement and sometimes requiring several specialists to implement. And if that workload wants or needs to move to another location or Datacenter, Oh Man that’s another big headache.
Sure we can use expensive proprietary solutions to address some of these issues, but if we could do this simply, cheaply, dynamically and safely using a software overlay, well now that’s the promise of SDN and Network Virtualisation.
I certainly get what SDN brings to the party in areas I don’t really get too involved in i.e. the Service Provider and Hyper Scale Datacenter arenas, many of these companies are already using SDN or a derivative of it, and several created their own versions or helped define the current SDN standards, when they found that they had outgrown the capabilities of many current technologies, but there are compelling use cases for my particular sweet spot, The Enterprise Datacenter.
Particularly around Datacenter Interconnection (DCI) and Enterprise Network Virtualization. Now Network Virtualization by strict definition is not SDN as there is no central controller involved, but it is where the revolution of our industry will start.
Having been heavily involved in all aspects of the Datacenter, I can certainly see the end to end picture and why Network Virtualization has so much potential.
VMware as I’m sure you all know, developed ESX which has revolutionized how quickly Servers can be provisioned, deployed and dynamically moved within the environment.
During this time the Network has remained almost static with regards to its ability to adapt to this huge change and flexibility in the compute layer.
Just like with ESX where vCPUs, vDISK, vRAM and vNICS can be combined to present a logical X86 Environment for a Virtual Machine to consume. Within NSX a Virtual Network can be defined, this Virtual Network can contain, VLANs, vSwiches, vRouters, vLoadBalancers etc…
NSX is a new product announced by VMware due for launch later this year, which combines the best elements from Nicira (acquisition last year) and VMware. The main components of each which form the core of NSX are:
Nicira: Distributed Controller Cluster (Layer 2 – 4 Programmable vSwitch)
VMware: VMware vCloud Networking and Security (VCNS) Portfolio (vLoadBalances, vFirewalls VPN, VXLAN etc..)
While NSX is a VMware product it is Vendor, Hardware and Hypervisor independent!
As mentioned NSX is a software OVERLAY which relies on having a “Dumb” low latency IP network beneath it, with all the intelligence defined in software.
I for one did not study my butt off to be an “UNDERLAY Fitter” so am obviously interested in how this progresses to ensure I am always where the Fun is!
This is not “pie in the sky” in my view VMware with NSX has the serious potential to revolutionize the Network in the same way it has the Server Industry with ESX.
Anyway managed to dump down my thoughts, at present which may well change once I get more knowledgeable on the subject and offerings.
If you have a view or disagree with mine, please leave a comment.
Regards
Colin