
A practical comparison of Rail-Only, Rail-Optimised Fat-Tree and traditional Clos network topologies for AI backend (East/West) Networks
Modern AI infrastructure conversations are dominated by headline numbers.
How many GPUs? How much HBM? How many terabits of bandwidth? How many tokens per second?
Those figures matter, but they do not tell the whole story.
For an AI Factory decision maker, topology is not simply a network engineering choice. It influences how effectively expensive GPUs are utilised, how quickly the platform can scale, how much switching and optical infrastructure must be purchased, and how much operational risk the organisation carries. A cheaper initial fabric may become expensive if growth requires redesign and re-cabling, while an oversized fabric can consume capital and power without delivering a corresponding business benefit.
A 2% reduction in GPU utilisation across a thousand Blackwell GPUs represents millions of pounds of compute capacity sitting idle. That is why topology has become a board level infrastructure decision rather than simply a networking exercise.
Topology determines whether the organisation extracts maximum value from one of its most expensive capital investments.
As GPU clusters grow from a handful of servers into systems containing hundreds, thousands or even tens of thousands of accelerators, the topology connecting those GPUs becomes a critical architectural decision. It determines how traffic moves through the fabric, how effectively available bandwidth can be used, how the cluster scales and how difficult the environment will be to operate.
A network can have enormous aggregate bandwidth and still perform poorly if the topology does not align with the communication patterns of the workload.
Distributed AI training is particularly demanding. GPUs repeatedly exchange large volumes of data through collective operations such as AllReduce, AllGather and ReduceScatter. The performance of these operations depends not only on link speed, but also on locality, path length, congestion, oversubscription and the relationship between each GPU and its Host Channel Adapter, or HCA.
This is why several apparently similar InfiniBand fabrics can behave very differently.
A small Rail-Only fabric may provide exceptional performance, low latency and operational simplicity. Adding a spine tier can extend that architecture, but introduces additional cost and network hops. A Rail-Optimised Fat-Tree can scale much further and use the wider fabric more efficiently, although it requires more careful design. A traditional Leaf/Spine topology remains flexible and familiar, but does not inherently exploit GPU and HCA affinity in the same way.
The fact is, there is no universally correct topology.
The right choice depends on the size of the cluster, expected growth, workload communication patterns, switch radix, resilience requirements, operational model and the importance of alignment with a vendor reference architecture.
This blog post compares four topology options:
- Rail-Only Single-Tier
- Rail-Only Two-Tier
- Rail-Optimised Leaf/Spine Fat-Tree
- Traditional Rack-Based Leaf/Spine Clos
The objective is not simply to identify which topology is “best”. It is to understand the compromises each design makes and why an architecture that is ideal for one AI cluster may be completely inappropriate for another.
Executive Summary
The following scorecard provides an at-a-glance comparison of the four topologies. The detailed sections that follow explain the assumptions and trade-offs behind each rating.
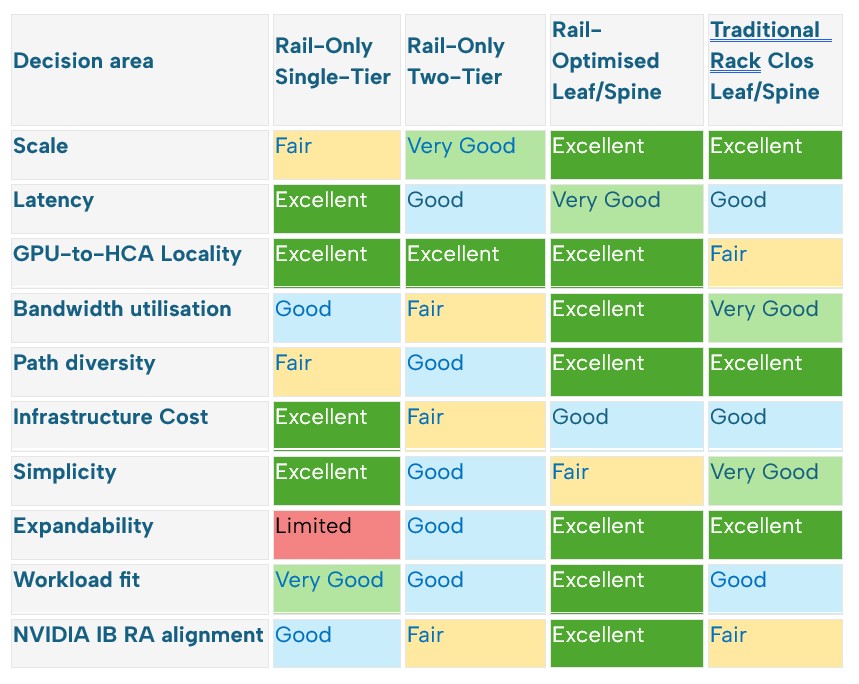
Ratings are comparative and assume a distributed AI training context. “Excellent” represents the most favourable outcome for each criterion, so an Excellent Cost rating means lower relative infrastructure cost, while an Excellent Simplicity rating means easier design and operation. Actual results depend on switch radix, tier count, oversubscription, routing, endpoint placement and workload behaviour.
Before Comparing Topologies: What Is a Rail?
Before looking at the individual designs, it is important to clarify what the term rail means.
A rail is formed by mapping a corresponding HCA from each compute node to a common portion of the network fabric.
In a simplified four-GPU example:
- GPU 1 and HCA 1 are associated with Rail 1
- GPU 2 and HCA 2 are associated with Rail 2
- GPU 3 and HCA 3 are associated with Rail 3
- GPU 4 and HCA 4 are associated with Rail 4
The exact relationship depends on the server architecture. In modern GPU systems, NVLink and NVSwitch provide high-bandwidth communication within the local GPU domain, while ConnectX HCAs provide scale-out connectivity between systems.
The objective of rail-aware design is to preserve communication locality wherever possible. Rather than moving data through unnecessary network stages, collective communication libraries such as NCCL can favour the HCA and network path closest to the relevant GPU.
This distinction is central to the comparison:
Rail-Only designs enforce rail separation, while Rail-Optimised designs preserve rail affinity but allow communication through the wider shared fabric.
A conventional Clos network, by contrast, is generally organised around physical switch placement and endpoint connectivity rather than GPU to HCA locality.
With that foundation in place, let’s start with the simplest topology and build from there.
Rail Only Single-Tier Topology
The simplest and most cost-effective option for smaller GPU clusters that fit within the endpoint capacity of a single switch per rail.
For example, four NVIDIA Q3400 switches, each providing 144 ports of 800 Gb/s connectivity, could form four independent rails serving 144 four-GPU nodes. This would support a 576 GPU cluster without requiring a spine layer, assuming one corresponding 800 Gb/s HCA endpoint per GPU.
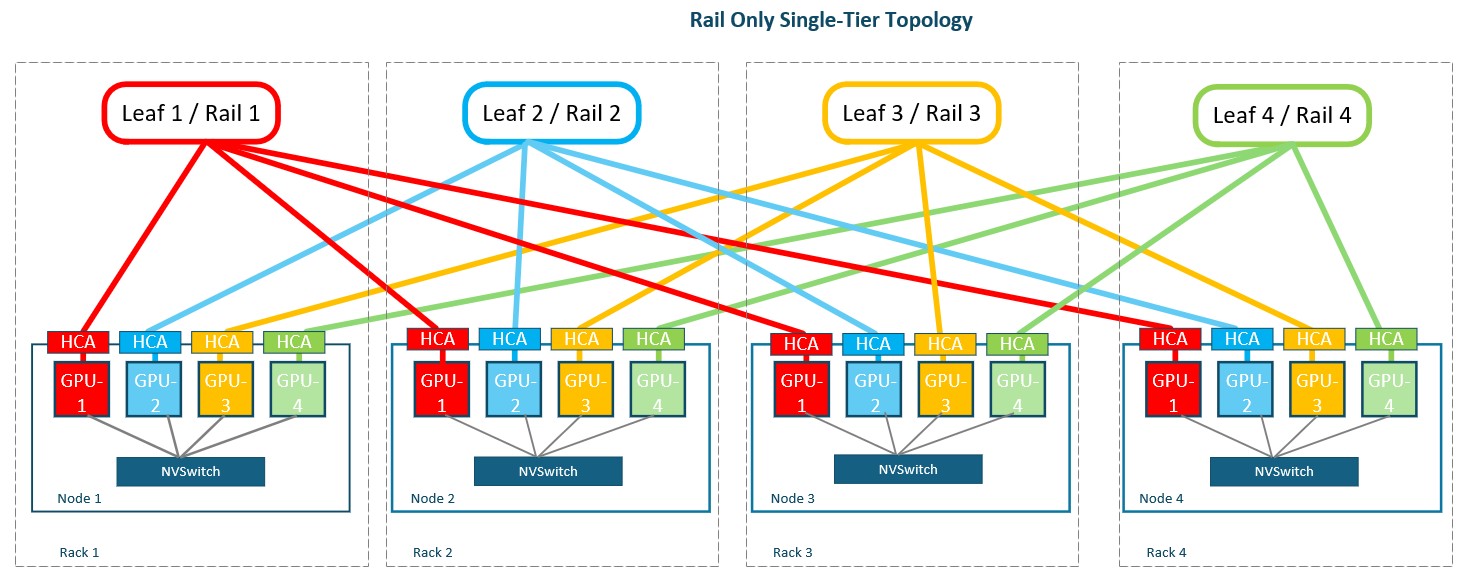
Design: Each corresponding HCA connects to a dedicated, isolated rail switch; no spine layer is required.
Purpose: Delivers a simple, low-cost fabric for clusters that fit within a single switch per rail.
Strengths: Shortest network path and lowest fabric latency, strong GPU-to-HCA locality and minimal switches, optics and cabling.
Limitations: Scale is constrained by switch radix, with limited path diversity and no sharing of capacity between rails.
Business Impact: This avoids paying for a spine tier that the cluster may never need, but requires confidence in the expected growth ceiling.
Best fit: Small to medium, cost-sensitive AI clusters with predictable scale and well-balanced rail utilisation.
When Would You Choose Rail-Only?
Choose Rail-Only Single-Tier when the cluster fits comfortably within one switch per rail and simplicity, latency and cost are more important than future expandability.
Rail Only Two-Tier Topology (Uncommon)
Some people assume that a Rail-Only fabric must be a spineless, single-tier topology. This is not the case. A Rail-Only fabric can use leaf and spine switches, provided that each rail remains an independent fabric with no network-level connectivity between rails.
However, this would be an uncommon choice for a new backend network. Adding a dedicated spine layer to every rail increases the number of switches, optics and cables, reducing many of the original cost and simplicity benefits of Rail-Only. If the required scale is known from the outset, a Rail-Optimised Fat-Tree would generally provide better path diversity and more efficient use of the overall fabric.
A more likely use case is the expansion of an existing Rail-Only Single-Tier fabric that was not originally expected to grow. Adding dedicated spines to each rail allows the fabric to scale beyond the port capacity of the original rail switches while preserving the existing host connections and avoiding extensive re-cabling.
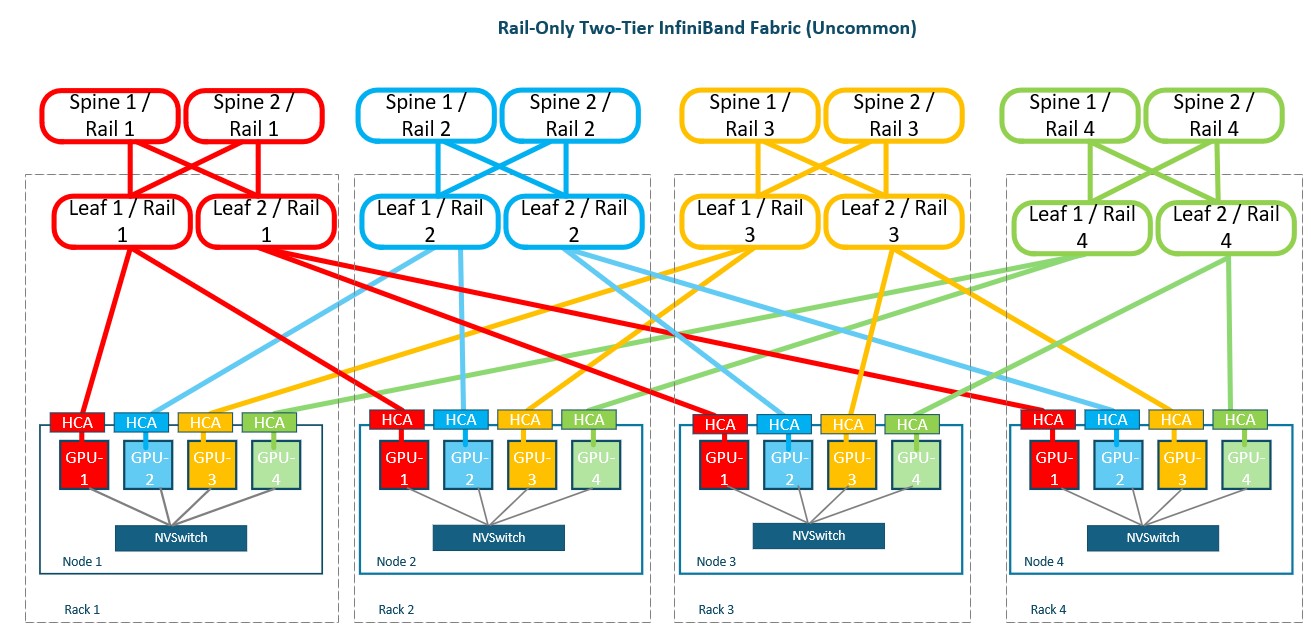
Design: Each HCA connects to a dedicated rail, with separate leaf and spine switches maintained for every isolated rail.
Purpose: Extends a Rail-Only fabric beyond the port capacity of a single leaf switch while preserving strict rail separation.
Strengths: Greater scale, predictable traffic domains and strong GPU-to-HCA locality, with multiple spine paths available within each rail.
Limitations: Requires more switches, optics and cabling; capacity remains isolated between rails and uneven rail utilisation can strand bandwidth.
Business Impact: This protects an existing cabling investment, although it may not be the most efficient greenfield design.
Best fit: Expanding an existing Rail-Only deployment where preserving its HCA mapping, rail isolation and host cabling is preferred over adopting a shared fabric.
When Would You Choose Rail-Only Two-Tier?
Choose Rail-Only Two-Tier when an existing Rail-Only fabric must grow beyond one leaf per rail, and preserving rail isolation and the existing host connectivity is more important than achieving maximum fabric efficiency.
Rail-Optimised Leaf/Spine Fabric
The most commonly adopted topology for large scale NVIDIA InfiniBand AI fabrics is the Rail Optimised Leaf/Spine design. It offers a strong balance of performance, predictability, scalability and fabric efficiency.
Modern InfiniBand fabrics can further improve utilisation using Adaptive Routing, but topology still determines the available path diversity.
This approach aligns with NVIDIA’s large-scale InfiniBand reference architectures, where it is commonly described as a Rail-Optimised Fat-Tree.
Rail-Optimised means that corresponding GPU facing HCAs are deliberately mapped to rail aligned leaf switches. Communication remains local to the leaf wherever possible, avoiding unnecessary spine traversal, while the wider fabric remains available when endpoints are attached to different leaves.
Fat-Tree is a hierarchical network topology in which bandwidth is distributed through successive switch tiers. It can be non-blocking or oversubscribed depending on the ratio of host-facing to spine-facing bandwidth.
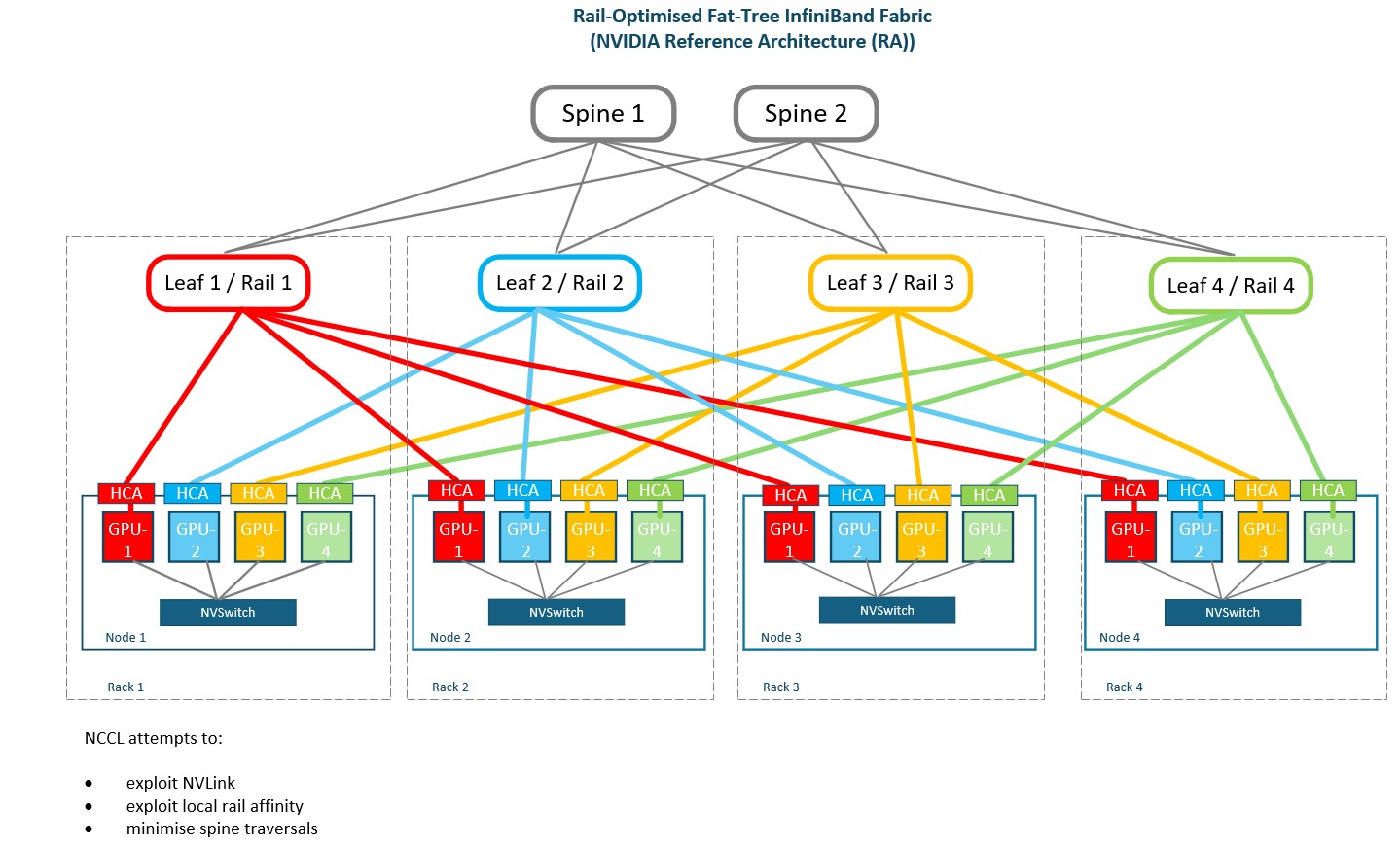
Design: Rail-aware GPU-to-HCA affinity is maintained at the leaf layer, while a shared spine layer provides connectivity across the wider fabric.
Purpose: Scales the fabric across large, multi-rack AI clusters while minimising unnecessary spine traversal and allowing capacity to be used more effectively across the shared fabric.
Strengths: Excellent scalability, GPU/HCA locality, path diversity and fabric utilisation, aligned with NVIDIA’s reference architecture.
Limitations: Requires more switches, optics and cabling, plus careful affinity mapping, routing and congestion management.
Business Impact: The additional network investment is justified by better scalability, stronger reference architecture alignment and reduced risk of the fabric constraining high value GPU resources.
Best fit: Large scale AI training clusters and multi-rack AI factories where performance, scalability and fabric efficiency are the primary priorities.
When Would You Choose Rail-Optimised?
Choose Rail-Optimised Fat-Tree when building a large, scalable AI fabric where rail locality should be preserved, but traffic must also be able to use the wider shared fabric for greater path diversity and bandwidth efficiency.
Traditional Rack-Based Leaf/Spine Clos
Last but not least we have the familiar Leaf/Spine or ‘Clos’ topology where all devices in a rack are connected to the Leaf switches within that rack.
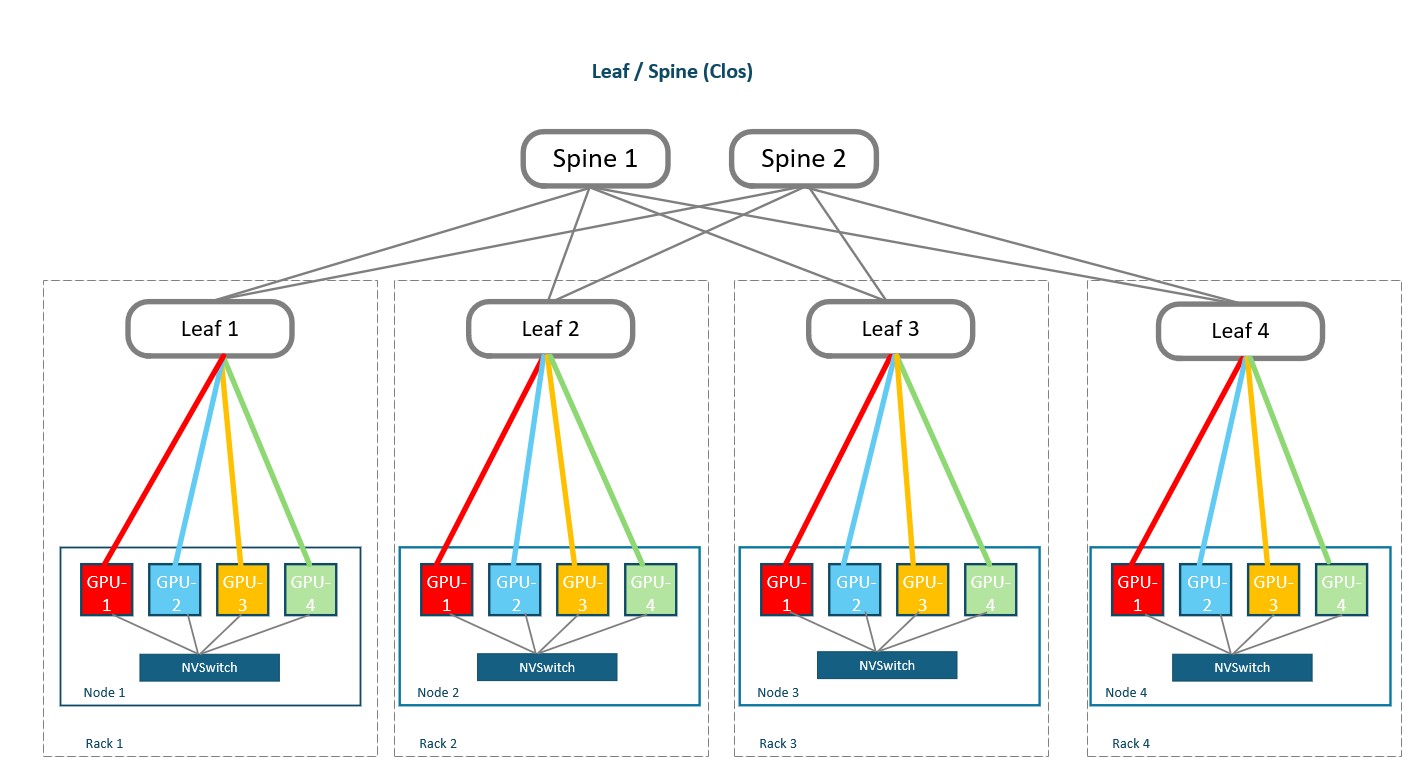
Design: Nodes connect to their local rack leaf switch, while every leaf connects to every spine; traffic between different leaves traverses the spine layer.
Purpose: Provides a scalable, cable-efficient and general-purpose fabric without requiring rail-aware endpoint placement or affinity design.
Strengths: Familiar architecture, strong path diversity, flexible endpoint placement and straightforward expansion within the planned switch capacity.
Limitations: Does not inherently exploit GPU-to-HCA rail affinity, typically increasing reliance on the spine layer and potentially reducing distributed training efficiency compared with an equivalent rail optimised design.
Business Impact: This may reduce operational change and support mixed use cases, but a general-purpose design should be validated carefully against the communication demands of large distributed training jobs.
Best fit: Enterprise AI and mixed-workload environments where flexibility, multi-vendor interoperability and operational familiarity are prioritised over rail optimisation. Traditional leaf/spine is a natural fit for standards-based Ethernet backends using RoCEv2 or Ultra Ethernet. However, Ethernet backend fabrics can also use rail-aware endpoint placement where the platform and workload benefit from it.
When Would You Choose Leaf/Spine
Choose traditional Leaf/Spine when you need a flexible, scalable and operationally familiar fabric for mixed or general purpose workloads, and rail aware optimisation is not a primary design requirement.
The Best Topology Is the One That Matches the Growth Plan
So, what is the best topology? The answer is straightforward: the one that best aligns with the workload, operational model and realistic growth plan.
Every topology is an optimisation. Some optimise for latency, some for scale, some for operational simplicity, and some for investment protection. Choosing the right one is less about finding the “best” topology and more about matching the network to the organisation’s growth strategy and AI workloads.
Rail-Only Single-Tier offers a compelling combination of low latency, simplicity and cost efficiency when the final cluster fits comfortably within one switch per rail. Rail-Only Two-Tier provides a pragmatic expansion path when an existing fabric unexpectedly outgrows that boundary, although it would rarely be the preferred greenfield design.
For large-scale NVIDIA AI clusters, a Rail-Optimised Leaf/Spine fabric provides the strongest balance of locality, scalability, path diversity and bandwidth utilisation. Traditional Clos remains highly relevant where flexibility, operational familiarity, mixed workloads or an Ethernet backend are more important than strict rail optimisation.
The design decision should therefore begin with the workload and growth model, not the topology label.
Ask:
- How many endpoints must the fabric support now?
- How far is the cluster realistically expected to grow?
- How tightly coupled are the workloads?
- How important is reference architecture alignment?
- Is the platform dedicated to distributed AI training or shared across mixed workloads?
- What are the cost and operational consequences of redesigning the network later?
The objective is not to build the largest or most sophisticated fabric possible. It is to build a fabric that keeps the GPU estate productive, supports the required growth and avoids paying for complexity that the business does not need.
At scale, the topology is not the network diagram. It is the performance model for the entire AI Factory.









