
I was recently asked to investigate an issue which on the face of it sounded very odd.
We had installed a fairly large FlexPod environment running VMware NSX across a couple of datacentres
During pre-handover testing the environment suffered a complete loss of service to the vSphere and NSX management cluster.
When I asked if anything had been done immediately prior to the outage, the only thing they could think off was that a UCS admin (to protect his identity let’s call him “Donald”) had renamed an unused VLAN, which had no VM’s in it, so was almost certainly not the cause and just a coincidence.
Hmmmm I’ve never really been one to believe in coincidences, and armed with this information, I had a pretty good hunch where to start looking.
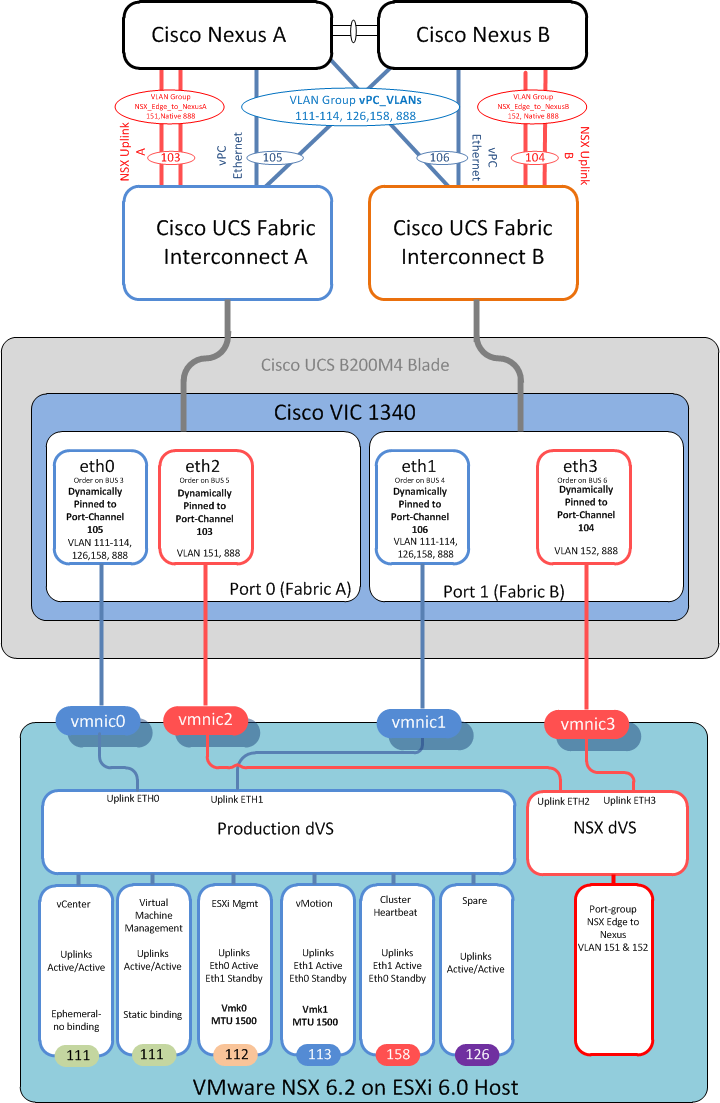
As I suspected both production vNICs (eth0 & eth1) of all 3 hosts in the management cluster were now showing as down/unpinned in UCS manager.
This was obviously why the complete vSphere production and VMware NSX management environment were unreachable, as all the Management VM’s including vCenter, NSX manager along with an NSX Edge Services Gateway (ESG) that protected the management VLAN resided on these hosts, all of which had effectively just had their networking cables pulled out.
So what had happened?
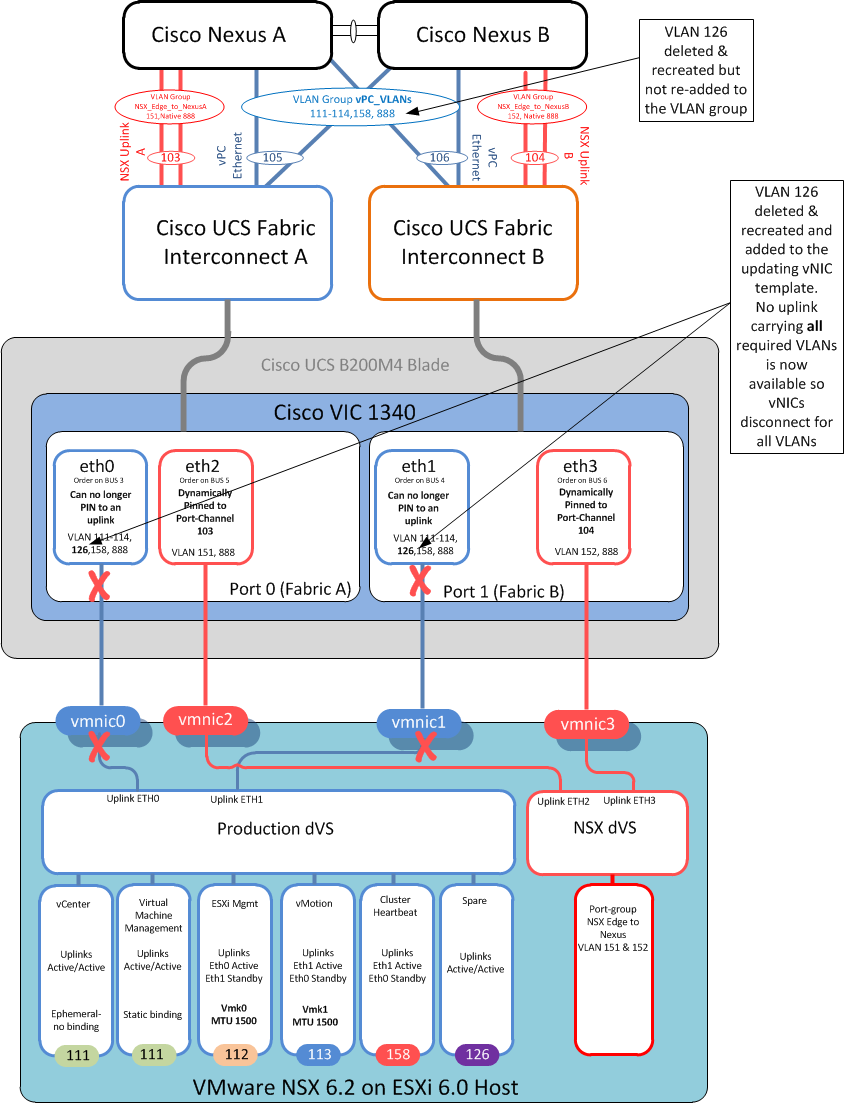
As you may know you cannot rename a VLAN in Cisco UCS so Donald had deleted VLAN 126 and recreated it with the same VLAN ID but a different name (“spare” in this case). This wasn’t perceived as anything important as there were not yet any VM’s in the port-group for VLAN 126.
Donald then went into the updating vNIC template to which the 3 vSphere management hosts were bound and added in the recreated VLAN 126.
And that is when all management connectivity was lost.
The issue was, as per best practice when using vPC’s on Cisco UCS with NSX, there were two port-channels northbound from each Fabric Interconnect one for all the production VLANs connected to a pair of Nexus switches running virtual port-channels vPC and the other a point to point port-channel to carry the VLAN used for the layer 3 OSPF adjacency between the Nexus switches and the virtual NSX Edge Services Gateways (ESG’s) as it is not supported to run a dynamic routing adjacency over a vPC.
So obviously VLAN groups have to be used to tell UCS which uplinks carry which VLANs (just like a disjointed L2 setup)
Cisco UCS then compares the VLANs on each vNIC to those tagged on the uplinks and thus knows which uplink to pin the vNIC to.
Unfortunately as Donald found out this is an “All or nothing” deal, unless ALL of the VLANs on a vNIC exist on a single uplink that entire vNIC and ALL its associated VLANs will not come up. Or as in this case will just shut down.
So when VLAN 126 was deleted and recreated with a new name, this new VLAN did not exist on the main vPC UCS uplinks (105 & 106) hence all hosts bound to that updating vNIC template immediately shut down all their production vNICs (eth0 & eth1) as there was no longer an uplink carrying ALL their required VLANs to which to Pin to. (Cisco UCS 101 really)
As soon as I added the recreated VLAN to the vPC uplink VLAN group, all vNICs re pinned, came up and connectivity was restored. (I could have also just removed this new VLAN from the vNIC template) either way the “All or nothing” rule was now happy.
As per best practice all the clients user workloads and supporting vSphere and NSX infrastructure were located on different vSphere clusters and thus were unaffected by this outage.
There are numerous ways to avoid the above issue, for example you could take out the vPC element and just have a singular homed port-channel carrying all VLANs from FI A to Nexus A and the same from FI B to Nexus B.
Or as was done in this case, the run book was updated and everyone informed that in this environment VLAN groups are in use, thus ensure that a newly created VLAN is added to the relevant VLAN group, before it is added to the vNIC template.
I would like to see a feature added to UCS that changes this behaviour to perhaps only isolate the individual VLAN(s) rather than the whole vNIC, but I can think of a few technical reasons as to why it likely is how it is. Or at least a warning added, if the action will result in a vNIC unpinning.
In a previous post UCS Fear the Power? I quoted Spider-man that “with great power comes great responsibility”
This was certainly true in this case, that seemingly minor changes can have major effects if the full ramifications of those changes are not completely understood.
And before, anyone comments. No I am not Donald :-), but I have done this myself in the past so knew of this potential “Gotcha”
But if this post saves just one UCS Admin from a RGE (Résumé Generating Event) then it was worthwhile!
Don’t be a Donald! and look after that datacentre of yours!
Colin
Click on the Images to enlarge.

I have created an enhancement request to use VLAN groups to map VLANs to vNICs. In this situation it would be very handy feature as there is no way you can add VLAN to vNIC without mapping to correct VLAN group first that is assigned to uplink. Also, when you add VLAN that is not mapped to uplink there should have been assessment done by UCS Manager with a warning which vNICs will be shutdown as a result of this action.
Exactly. I think this and nested VLAN groups would be great. It’s just Switchport Trunk allowed vlans. More often than not you are matching a vNIC to a L2 disjoint uplink uplink 🙂 and when you are not you should be able to nest VLAN groups, even overlapping VLANs in groups 🙂
If VLAN126 wasn’t specifically mapped to Po105/106 when it was recreated, would UCS not have added it on ALL uplinks by default? That is what the LAN Uplink Manager warns about. Or does this work differently when using VLAN Groups?
Indeed Kevin, if you do not use VLAN groups mapped to different uplinks, by default all VLANs are mapped to all uplinks, so this is not something you usually need to consider.
This was really only ever used in a disjointed layer 2 scenario, when up linking to separate networks.But in this world of SDN and Overlays the requirement to use VLAN groups is becoming more of a requirement if you want to maintain vPC northbound while passing through a L3 adjacency between the upstream LAN and Virtual routers.
Colin
Hi Colin,
I think the warning in the VLAN Manager GUI is somewhat misleading. It reads “A VLAN with no Uplink Interfaces or Port Channels will terminate in all Uplink Interfaces and Port Channels”.
But if that truly was the case, and to Kevin’s point, then VLAN126 (which initially had no uplink) should have terminated in ALL uplinks *including* Po105/106 and ENM pinning should not have failed (things like ARP and multicast may not have worked properly in that VLAN but it would not have taken down every vNICs).
But it looks like because Po105/106 is linked to a VLAN *group*, then it somehow gets treated differently and only carries the VLANs in that group and no other (not-assigned-to-any-uplink) VLAN.
The documentation (http://bit.ly/1igZhY1) does hint at this:
“When you configure the uplink port for a VLAN group, that uplink port will only support all the VLANs in that group.”
But the GUI should really read “A VLAN with no Uplink Interfaces or Port Channels will terminate in all Uplink Interfaces and Port Channels not already added to a VLAN group” – although that would probably add to the confusion rather that clear it up!
Manu.
That’s what I meant. Would have expected VLAN126 to be on all uplinks by default, ie. 103/104 AND 105/106. Instead, your saying it wasn’t on any uplink because they were assigned to vlan groups?
Easiest solution would be to allow renaming of VLANs. Simple functionality that is missing.
Hi Colin, would this also affect the vHBAs and affect *all* blades in *all* chassis connected to the FI? We’ve just had this happen to us
On this line I have a question which I tried to search in the internet with little success. I am familiar with the situation where adding or removing vlans to an uplink port channel in UCS the system verifies if that vlan is “allowed” in the network stack and if the vlan is not allowed it shuts down the vnic thats using the vlan. Does UCS also verifies if a vlan group is part of this process, I have not seen UCS marking a nic down even if all of the vlans specified in the vlan group is not allowed in the uplink network stack. So i wonder this validation is not done if vlan groups are involved?
Thanks for a great reaad