![]()
Another great Cisco Live Europe this year, as usual as the week progresses the dummer I feel, as I see there is still so many topics I don’t know enough about. But as always I come away wiser and with a huge list of topics to research further, as well as ideas for labs to stand up and play with.
I will be delving deeper into some of the below topics in future posts, but in the meantime here’s a high level list of topics I found interesting.
The running theme of many of the tech sessions that I attended was Anywhere. The flexibility to run workloads or extend policy anywhere you need to regardless of whether that be within a data center, on the edge, across data centers out to a branch or into a public cloud or multiclouds while maintaining a consistent policy model. And managing it all from a unified UI that abstracts the different underlying technologies.
Cisco ACI Anywhere
Cisco announced ACI Anywhere which essentially means being able to deploy or extend your policy and security requirements anywhere they are needed, whether on premises or in an public cloud (AWS or Azure). Most of the setup requirements for this are automated with the results being a central user interface Multisite Orchestrator (MSO) from which you can then create your policy and select the site or sites that you wish to deploy the policy to. All ACI to public cloud construct mappings are handled automatically with no knowledge of AWS or Azure required. I see this being of real interest to customers, and should accelerate the adoption of Cisco ACI. Cisco also have a “Cloud First” use case for ACI Anywhere, where there is no on premises location at all, just Cisco ACI deployed into the public cloud or clouds, normalising policy between them.
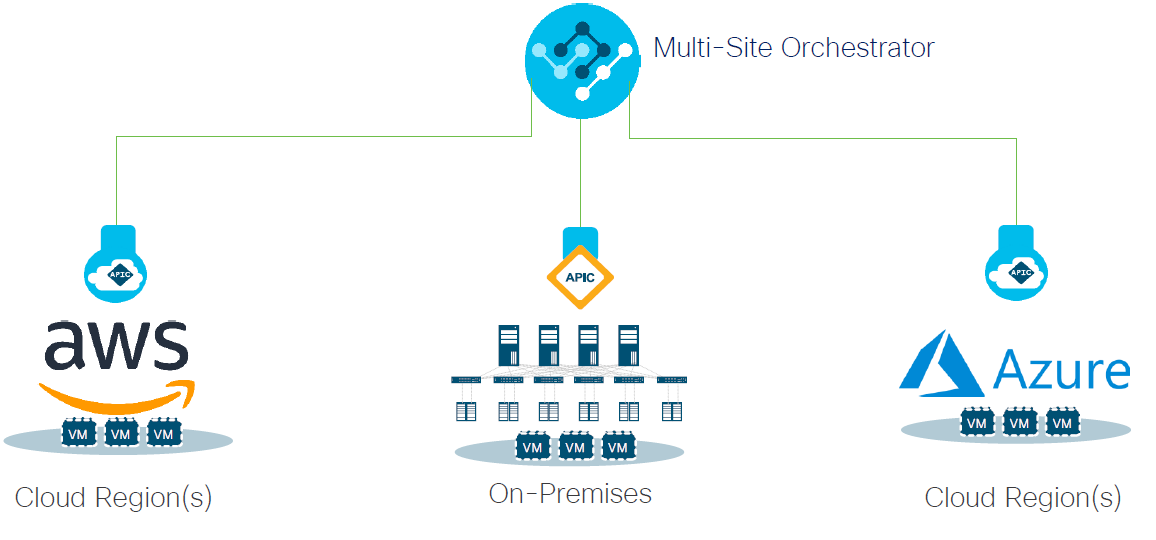
Additional enablers for ACI Anywhere are:
Remote Leaf: Allows extending the ACI fabric out to a remote location or Co-Lo without having to also deploy ACI Spines or APICs there. This being a physical pair of leaf switches bare-metal and virtual workloads are supported.

Remote Leaf
Virtual Pod: vPod is similar to remote leaf however it is a software only solution. vPod is made up of virtual spines (vSpines), virtual leafs (vLeafs) and ACI Virtual Edges (AVEs) that are deployed on a hyper-visor infrastructure, thus designed for a virtual environment.
When I first saw vPod I did wonder whether this could be the first step of being able to run Cisco ACI on non Cisco hardware. When I asked this question, the answer was “It’s theoretically possible”

vPod
Cisco Hyperflex Anywhere
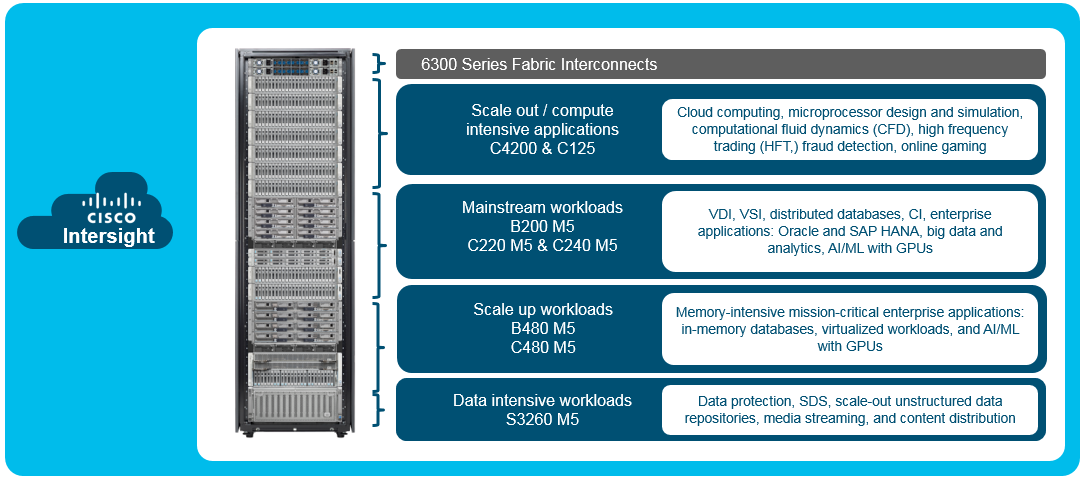
Cisco also announced numerous new updates in the soon to be released 4.0 code for its UCS based hyper-converged offering, Cisco Hyperflex (Cisco HX). Hyperflex Anywhere gives the ability to deploy workloads on an HX cluster anywhere they are required whether that be in the DC or out at the edge. Many customers have the requirement of moving the data closer to the users, the fact is the data center is no longer the center for data! Hyperflex edge allows a 2 – 4 node cluster to be deployed, with no Fabric Interconnects required and the flexibility of 1 or 10Gbs connectivity. And I know what you are thinking, a 2 node cluster? how would consensus work there to prevent a split brain scenario, well Cisco have thought about that, and use a virtual cloud VM as part of Cisco Intersight to act as a cloud witness, …clever!
This setup would give customers a significant cost saving by minimising the equipment required at the edge or remote location while providing a consistent platform and centralised management.
The deployment of a Hyperflex edge cluster can also be automated from Cisco Intersight to allow for zero touch provisioning (ZTP) from the factory to these remote locations, including incorporating SD-WAN virtual appliances if required.
The other significant updates announced with Cisco HX 4.0 were performance related.
All NVMe Node:
Cisco have partnered closely with Intel to develop the HX220c M5 All NVMe node untilising Intel Optane caching and all NVMe capacity drives. As we know compared to SSDs, NVMe is crazy fast, which has the potential to move the age old choke point in any system from the drives to the I/O bus, requiring I/O evolution or DIMM form factors.

HX NVMe
HyperFlex Acceleration Engine:
The HyperFlex Acceleration Engine is an optional PCIe I/O card which off loads the always on compression from the CPU, freeing up more of those valuable CPU cycles for workloads.
Cisco Intersight

Intersight is Cisco’s SaaS management portal for UCS Servers and HX clusters. It automates monitoring, logging of TAC cases and collecting and uploading logs. There are 2 licence options available Basics and Essentials. Basics is free and gives you monitoring, automated call logging of all your UCS and HX servers. In addition Essentials gives the capability to KVM Servers, deploy and monitor the hypervisor OS and version check drivers against the vendors HCL. There is also an on prem Virtual Intersight appliance option for clients that for whatever reason cannot use the SaaS offering.
In many of the chats I had at Cisco Live it was repeatably mentioned that there is a huge amount of R&D going in to Intersight with much more functionality planned especially around orchestration and automation. So well worth setting your self up a free Intersight account and adding your Cisco UCS or Hyperflex Clusters to it. You could even add UCS Platform Emulator instances to it if you just want a play for now.
Evolution of the Network Engineering role.
Over the last several years the role of the network engineer has been rapidly evolving, moving from CLI to API configuration methods, and focusing on network programmability and automation of repetitive or tedious tasks. Cisco are certainly enabling this evolution with the myriad of classroom sessions and labs available around automating and orchestrating the network and have a huge amount of free training offerings at DevNet developer.cisco.com
As in previous years Cisco again raised the bar with the quality of the DevNet sessions at Cisco live, and giving some great real world examples of where automation can make such a difference.
Automating the network does not change the what it changes the how, so you still need to understand networking, automation just gives you more tools to get the same job done, but in a smarter more efficient and deterministic way. It must be said, there is no single or magic recipe to automate the network, it requires consultation with the client, to determine their requirements, current skill set and tooling preferences.
Concepts that the Network Engineer would greatly benefit from include:
- Understanding the requirements for a cloud native environment
- Understanding automation tools like Ansible or Terraform
- Understanding basic coding
- Understanding version control (eg. GIT)
So that’s what I got up to last week, a great week in all, and Save the Date for Cisco Live Europe 2020, back in Barcelona. January 27-31! Hope to see you there!