I was designing a Datacentre migration for one of our clients, they have two DC’s 10km apart connected with some dark fibre.
Both DC’s were in the south of England but the client needed to vacate the current buildings and move both Datacentres up north (Circa 300 miles / 500km away) as ever this migration had to be done with minimal disruption, and at no point should the client be without DR. Meaning we couldn’t simply turn 1 off, load it in a truck and drive it up north, then repeat for the other one.
The client also had the requirement to maintain 75% service in the event of a single DC going offline. Their current DC’s were active/active but could support 50% of the load of the other DC if required, meeting this 75% service availability SLA.
Anyway cutting a long story short I proposed that we located a pair of Cisco ASR 1000’s in one of the southern DC’s and a pair in each of the northern DC’s and use Cisco’s Overlay Transport Virtualisation (OTV) to extend the necessary VLANs between all 4 locations for the period of the migration.
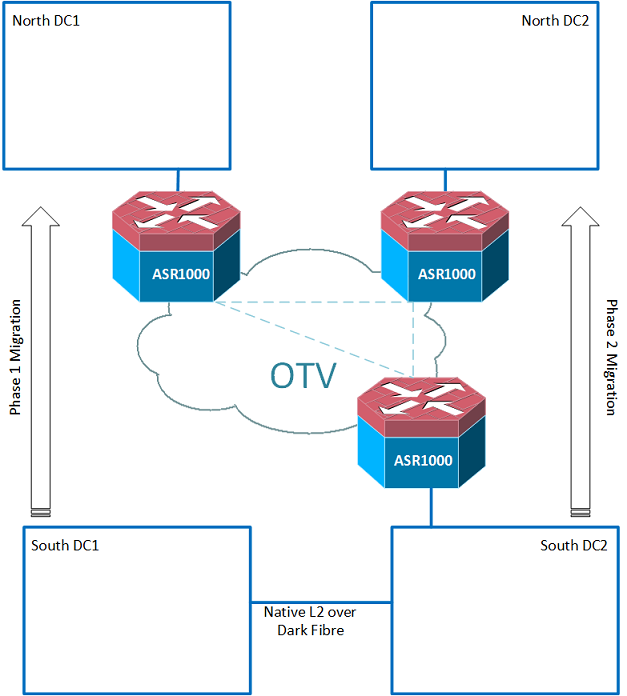
As would be expected at this distance, the latency across the MPLS cloud connecting the Southern and Northern data centres (circa 20ms) was too great to vMotion the workloads, but the VMs could be powered off, cold migrated and powered back up again in the north. And doing this intelligently DR could be maintained.
The major challenge was that there were dozens of applications and services within these DC’s some of which were latently sensitive financial applications, along with all the internal fire walling and load balancing that comes along with them.
The client being still pretty much being a Cisco Catalyst house were unfamiliar with newer concepts like Nexus and OTV but immediately saw the benefit to this approach, as it allowed a staged migration and great flexibility, while protecting them from a lot of the issues they were historically vulnerable to, as they had traditionally extended layer 2 natively across the dark fibre between their two southern Data Centres.
Being a new technology to them, the client understandably had concerns about OTV, in particular around the potential for suboptimal traffic flows, which could cause their latency sensitive traffic going on unnecessary “field trips” up and down the country, during the migrationary time period that the North and South DC’s were connected.
I was repeatedly asked to re-assure the client about the maturity of OTV and lost count on how many times I had to whiteboard out the intricacies around how it works, and topics like First Hop Redundancy Protocol isolation and how broadcast and multi-Cast works over OTV.
My main message though being, “forget about OTV, it’s a means to an end. It’s does what it does, and it does it very effectively, however it does not replace your brain, there are lots of other considerations to take into account, all your concerns would be just as valid, if not more so, if I just ran a 500km length of fibre up the country and extended L2 natively, as the client was already doing, already comfortable with, and had accepted the risks associated with doing so.
This concept got the client thinking along the right lines, that while OTV certainly facilitated the migration approach, careful consideration as to what, when, how and the order in which workloads and services were migrated, would be the crucial factor, which actually had nothing to do with OTV at all.
The point being that an intelligent and responsible use of the technology was the critical factor, and not the technology itself.
So just remember OTV doesn’t kill people, people kill people.
Stay safe out there.
Colin

Hi thanks for postting this