Leave your question in the comments section.
Before this section was added many questions were left in the About section above, so why not also check there to see if your question has already been asked.
Leave your question in the comments section.
Before this section was added many questions were left in the About section above, so why not also check there to see if your question has already been asked.

Hi Colin,
I might be asking a stupid question & I might need to do a little more research before asking this question, but, this post of yours is enticing me into asking this question. I had been thinking UCS can do a per packet/flow based load-balancing by doing an active-active NIC teaming between the two vNIC’s created for the same H/W server. Is it not?
I just cane across a PDF which says “Per flow/packet load balancing at the host level, is not allowed on UCS B-Series”.
If the above is true it means I can have one h/w server using FI-A (FI-B for failover) & other h/w server using FI-B (FI-A for failover) but I can’t have the same h/w server using both FI-A & FI-B at the same time which I earlier thought was possible using 2vNIC’s on the same h/w server one using FI-A another using FI-B & teaming them together for both b/w & HA.
-Regards
-Tarun Lohumi
Hi Tarun
Again the answer is it depends, if you are using a Hyper-Visor like VMware you can select the hash algorithm to use and if you would like to active/active load balance as you suggest you would need to specify Port-Group based load balancing, this will ensure that each VM gets consistently mapped to the same UCS vNIC so VM 1 may go fabric A and VM 2 may go out Fabric B. This is fine and provides good balance.
I think the issue arises when you use a per packet / flow algorithm as the upstream LAN will see the host on Fabric A one minute then fabric B the next and the host will “flap” between the two.
With regards to a bare metal install there is now a M81KR (Palo) NIC teaming driver for W2K8R2 available, which I have found works really well.
the Windows teaming driver supports the below:
Supported teaming modes:
• Active-Backup (with or without failback)
• Active-Active (outbound load balancing only)
• 802.3ad LACP (only supported on C-Series (P81E)) Currently
Supported load balancing methods:
• TCP connection
• Source and destination MAC address
• MAC address and IP address
Supported hashing options for load balancing:
• XOR hash
• CRC hash
A pleasure as always.
Colin
Thanks for clarifying Colin. Appreciate your speedy responses.
-Regards,
-Tarun Lohumi
Here’s my recommendation when teaching UCS: Load sharing is usually done to a) scale bandwidth and b) provide redundancy in case a link fails. For hypervisors and UCS, I typically recommend using virtual Port ID as the load sharing mechanism. Some VMs will get pinned to the A interface, and some will get pinned to the B interface. Since we’re dealing with 20 to 80 Gbits per second per server, you don’t need to spread load across multiple links for scaling. For redundancy, VMware does a great job of handling link failure scenarios, or alternatively you can use Fabric Failover, which will turn an A-connected vNIC into a B-connected vNIC (or vice-versa) in case of failure. So either VMware
Thanks for the input Tony and completeley agree, Port ID load sharing is the way to go for ESX Hosts for dual uplinked vSwicthes / DvS.
And Fabric Failover for single uplinked vSwitches if you want to keep east/west traffic within the FI (like vMotion)
Colin
What is the best practice (and why) regarding network load balancing within vSphere when using UCS? Maybe, expand that to a networking best practice for UCS (NIOC, shares, QOS, etc)?
Thanks!
GS
Hi GS
Thanks for the great question, and one (as you might expect) with potentially several answers depending on the implementation, i.e. whether using Standard vSwitches / vDS, Nexus 1000V or VM-FEX. Lets take the most common implementation I tend to do which is vSphere using standard vSwitches.
Ok, Thats narrowed us down but still a lengthy topic, so I’ll concentrate on the Cisco UCS specific aspects and not so much on the standard VMware config, I/O control etc.. which is equally relevant whatever platform is used and I’m sure you are familiar with.
So the first question I tend to address with customers is how do they want their hosts networking to look. What I mean by that is, the client may well have a Networking Standard for their ESXi hosts or want to use their standard host templates, which is fine. But Cisco UCS does have some nice features which could greatly simplify the Hosts networking. Features that you may well already be aware of like Hardware Fabric Failover, where you can present a single vNIC to the OS / Hyper-visor and that vNIC is backed by Hardware fabric failover, i.e. if there is any break in the traffic path on the primary fabric that the vNIC is mapped to then UCS Manager will immediately switch the data path to the other fabric, without the OS ever seeing the vNIC go down. This as you may have guessed could potentially half the number of Network interfaces in your hosts (i.e. you could potentially leave out all the Uplink interfaces which are purely there for redundancy, and you can salt and pepper the remaining single vNICs to be mapped primarily to Fabric A and Fabric B to provide load balancing across both Fabrics.
The Potential situation to be aware of here though is if a VM which has its active traffic flow via an Uplink mapped to fabric A is communicating with a VM whose traffic flow is mapped via Fabric B then that flow has to be forwarded to beyond the Fabric Interconnects to the upstream LAN switches to be switched at Layer 2 between fabrics even if both VM’s are on the same VLAN.
So what I tend to do is use a mixture of both single vNICs backed by hardware fabric failover and dual teamed vNICs for vSwitch uplinks which I would like to load balance across both fabrics.
But lets assume the customer wants to retain their Physical Host Networking standard so vSphere admins have a consistent view and config for all hosts whatever platform they are hosted on.
So a typical ESXi Host would look something like:
2 x Teamed vNICs for Management vSwitch
eth 0 mapped to fabric A
eth 1 mapped to fabric B
1 x vNIC for VMware user PortGroups uplinking to a dVS
eth 2 mapped to fabric A
1 x vNIC with Fabric Failover enabled for vMotion
eth 3 mapped to fabric B
Of course you can add other vNICs if you have more networking requirements or require more than a simple port-group (802.1q tag) separation. i.e. an add in an iSCSI vSwitch, Backup vSwitch etc..
So the setup would look something like this

The reason I go with a single fabric failover vNIC for vMotion is for the potential “issue” pointed out above, which if I have 2 vNIC uplinks to my vMotion vSwitch and were using them in an Active/Active team for redundancy and load balancing I would map one to fabric A and one to fabric B, that could mean that vMotion traffic is potentially taking a very suboptimal route across the network i.e having to go via the upstream swicthes. so by using only 1 vNIC and mapping it so a single fabric all my East/West vMotion traffic will be locally switched within the Fabric Interconnect and not have to be sent to the upstream LAN at all. And if in the event we had a failure within the primary fabric path UCS would switch this traffic transparently from the ESXi host to the other fabric which would again locally switch all vMotion traffic.
Also important to note when teaming the vNICs within vSphere to use Port-ID as the hash, this is to prevent hosts “flapping” between fabrics in the eyes of the upstream LAN switches.
OK once the above its setup you do have the option of mapping UCS QoS policies to each of the above vNICs within UCS Manager (by default all traffic is placed in a “best effort” policy)
As a standard I generally set a 1Gbs reservation for the vMotion vNICs and leave the others as default. Bearing in mind that these are multiple 10Gbs links and the QoS would only kick in in the event of congestion.
NB) FCoE traffic is inherently prioritised within the 802.1Qbb – Priority-based Flow Control standard a sub component of the Data Center Bridging (DCB) standard which Cisco UCS inherently uses. between the Mez Card on the blade and the Fabric Interconnect.
Ok, so with reagrds to Northbound load balancing, as you may know when you create the vNIC within the Mez card what you are actually creating is a Veth port within the Fabric Interconnect, as the Mez card (Cisco VIC) is an adapter Fabric Extender.
So when you create your teamed pair of vNICs within vSphere that will only get your load balanced traffic to the fabric Interconnects. Now assuming you are running your fabric Interconnects in the default end host mode (Where the FI’s appear to the upstream LAN as a Big Server, The FI’s obviously need load balancing uplinks into the LAN.
Now for redundancy you will likely have a pair of LAN switches hopefully capable of running a Multi-Chassis Ethernet service live Nexus vPC or Catalyst VSS. If thats the case you just size your uplinks to what you want and dual connect your FI’s to the upsteam switch pair and channel them at both ends (Standard LACP).
As shown below

The end to end result is that load balancing is done safely and optimally and East/West traffic is maintained within the UCS Infrastructure as much as possible.
Hope that answers your question, if not fire back at me, after all us Guru’s need to stick together 🙂
Regards
Colin
whre did you get the vmware icons like portgroup and vswitch?
Hi Arjan
Most likley from one of the Visio Cafes or perhaps VMware.
I have a few Visio stencils and Powerpoint slide Icons. I have zipped them up and posted them here
Regards
Colin
Great article (and website!), thanks for the useful info. One thing I’m not clear on is the 2 connections for management (I am using vSphere). Are they active-active or active-passive? For east-west traffic you suggest one vNIC to ensure traffic is locally switched on one FI. Are you happy to use 2 for Management as the traffic is north-south? Would 1 Management vNIC be sufficient?
Would you ever recommend having all traffic go through one fabric (except FC) and hardware failover box ticked for the vNIC?
Hi Andy
Thanks for the question.
My preference is to use a single vNIC and vSwitch for vMotion with hardware fabric fault tolerance enabled. This way all vMotion traffic will be locally switched in the FI.
Now you could do the above for management however vSphere complains if it does not think you have redundancy for you management uplink. vSphere would obviously be unaware that this was being provided at hardware level.
While you can suppress these vSphere complaints I generally just keep it happy by giving it another vNIC mapped to the other fabric and configuring then as active/standby. Active/Active would cause issues as you can’t port-channel across different fabrics.
Then if I was using a vDS I would just have 2 vNICs mapped to different fabrics! And teamed in ESXi using Port-ID as the hash. This way you get active/active load balancing with no MAC address flapping in the upstream LAN switches.
The only time I have ever sent all traffic through a single fabric, is when a customer insisted they did not want any reduction in bandwidth in the event of a fabric failure. Which meant that either they would have to ensure that they only ever went to 50% capacity on each fabric, or they just use one active fabric and know that if that fabric failed they would get identical performance on the other one. But not something I would do generally.
Hope that clears things up.
Regards
Colin
Hi, i have an C200M2 With 2 CPU E5620, 28 gb RAM, 1 HDD SATA 500gb 7.2k -no raid, lastest firmware (1.4.3) to CIMC and BIOS, Vmware ESXi 4.1, disable LRO, deploy using an OVA template to install CUCM 8.5 for 1000 Users, single nic one vlan, vSwitch without Traffic Shapping disabled, Vmware tools installed, but the appliance is too slow, what feature recommend to resolve this issue??
Regards.
Hi Albert
Sounds like there are alot of variables in there, I guess its going to come down to where your bottle neck currently is, I doubt you are CPU Constrained which leaves Disk, memory and I/O as possible “culprits” assuming that is that the VM’s and backend are all working OK.
VMware is generally pretty good at telling you if you have memory or CPU bottle necks, I guess you’ve checked the util of the mem/cpu ?. and the IOPs of the disk. Obviously a single SATA isn’t going to give you much performance and has no redundantcy. Also check the Util of the switch port to which your server connects to to check for high everage utilisation or packets drops/runts/giants etc.. which could indicate a speed/duplex issue.
Does your HW meet the recomended spec for a 1000 User CUCM deployment
Also what are you comparing it to?
Did it used to run fine and has slowed up recently
Does it “slow down” at particular times of the day or is it always slow?
All good questions to ask and explore, probably not the right forum here, but more for your own support teams and the escalate to TAC if issues cannot be identified.
Theres a good presentation on CUCM on UCS here which details sizing and optimisation.
Click to access CNSF2011-Planning-and-Designing-Virtual-UC-Solutions-on-UCS-Platform-Joseph-Bassaly.pdf
Regards
Colin
we are testing mapping EMC Luns from UCS, have created service profile and assigned it to a blade . but we are not able to see the vHBA WWWPN numbers , only one wwpn number is visible in the storage zone. Not sure what is the issue, Need help/ suggestions
Hi thanks for the question.
The first thing I would check is that all your vHBA’s have WWNN/WWPNs assigned either manually or from a pool, check this by expanding the vHBAs in the service profile.
Assuming they have their addresses check the vHBA’s are in the correct VSAN (if no default VSANs are being used)
If you are booting from SAN confirm your SAN Boot Policy has the correct WWPNs for the correct targets on the correct fabric.
(At this stage you can just use dummy WWPN of the targets, the vHBA’s will still flogi into the fabric)
If above checks out. ssh into the FI’s directly, connect NXOS, and check whether your WWPNs are in the flogi database of your FI’s “sh NPV flogi database” from NXOS mode.
If they are confirm the correct WWPN is showing on the correct Fabric Interconnect, if thats good,check your fibre channel uplinks between your FI’s and your SAN switches, make sure they are in the correct VSAN and are connected to the correct fabric.
If thats good check the flogi database of your SAN switches, and confirm they have NPIV enabled.
Also turn off quiet boot in the default BIOS settings and have a look during boot as to whether your vHBAs are seeing the targets you expect.
Thats the order I would do it in and you should rapidly work out where the issue is or isn’t.
Good luck, feel free to come back to me with any other questions.
Regards
Colin
Hi UCS Guru. Long time reader, first time poster. Something that has been bugging me. A 6120 Fabric Interconnect has two physical management ports, mgmt0 and mgmt1. The gui and CLI will only allow you to configure one mgmt ip (mgmt0) it seems. Can you configure the second management port? I have tried researching and came up empty.
Hi Jim
Thanks for reading and getting involved
The reason there are 2 MGMT ports on the 6100 series controllers will no doubt come as a real anti-climax to you.
Its simply because the 6100 series uses the same tin as the Nexus 5000 series (6120 = 5010, 6140 = 5020) Theres no great technical answer I’m affraid.
So the 2nd MGMT port on an FI is not used.
The Gen 2 FI’s similarly are Nexus 5500’s painted a different colour and running readonly NXOS with all the UCS goodies ontop.
6248UP = Nexus 5548UP, 6296UP = Nexus 5596UP. You will notice that all these models now only have a single MGMT Port.
Makes sense really why should Cisco re-invent the wheel if they already have a great product that fits the bill nicely.
You may have noticed that the UCS products and features trials the Nexus BU by approx 6 months, so whatever products / features get released for Nexus you could expect to see them in UCS within 6 months or so.
So hope that puts you out of your misery.
Look forward to your future posts.
Regards
Colin
Hi Colin, we have a wwn presentation problem from a UCS 5100 series with 2 FI 2208XP connected to 2 nxk5. Right now we managed to make the networking funcional, but the fiber channel part doesn’t work as we don’t see any wwn on the nexus. What do we need to be able to use the fc part of fcoe interfaces? Do we need NPV feauture enabled? Also we see fc port on nexus as “initializing”.
Thanks in advance
SGT
Hi SGT
Thanks for the comment.
No your upstream Nexus should not be in NPV mode, your 6248UP are however in NPV mode by default. What you will need to do is enable “Feature NPIV” on your Nexus 5500’s this will allow multiple fabric logins over the same F Port on the Nexus.
Are you sure you have configured some of your Nexus ports as native fibre channel? You need to split your 5500’s into an ethernet side and a native fc side using the below commands:
Slot 1
port 1-24 type ethernet
port 25-32 type fc
if your using some ports on the expansion module for fc just the above commands but choose slot 2 instead.
You may also want to ensure you have a storage licence on the N5ks which covers the number of fc ports you have.
If the above is all ok, I would confirm you can see the WWPN in the Fabric Interconnects, by dropping to the UCS CLI and doing a:
Connect NXOS
Sh NPV Flogi database
This should show that your servers have a least logged in to the FI’s, which from the servers point of view are fc swicthes (NPV mode just means that the FI’s are switches to the UCS servers but appear as hosts to the upstream SAN switches in your case the N5500’s)
Once the WWPN’s of your servers are visable in the local FI’s flogi database ensure that your VSAN ID on your FI FC uplinks matches the VSAN on the port on the Nexus you are connecting to (by default 1 on both ends) Also as mentioned that “Feature NPIV” is enabled on the Nexus switches.
Going through the above you should rapidly sort your issues out.
Regards
Colin
Hi Colin,
Thanks for this great page, now we have a definitive place to find answers to our questions. A small & might be dumb question I had, but I would still post it to you.
The UCS system is designed to operate in multi-tenant & cloud computing kind of environments. Keeping this in mind, what happens if there are two customer’s both using vlan 10 & both of them are terminating on the same FI’s? How would the FI handle traffic from two different customer but the same VLAN terminating on them?
-Regards,
-Tarun
Hi Tarun
You are right that UCS can work well in multi-tenant situations and I have set many up.
Things to remember that The administration of UCS is still not all that suitable for multi-tenant environments what I mean by that is is its currently not possible to negate the view privilidge in UCSM so if you wanted your tenants actually logging into UCS or KVM Launcher etc.. they would have read only privilages to the other Tenants Orgs and Locales etc..
That said Tenants should not need access to UCSM Manager anyway just the virtual estate that has been provisioned for them.
So going back to your question about VLAN overlap, You are right UCS is only a layer 2 device with no concept of VDC (or even vrfs from a usable perspective) as such VLAN 10 is VLAN 10 globally and should only be given to a single tenant, Tenants could of course share a common VLAN and be seperated by a context based gateway like VSG which can filter on much more than just IP’s for example all VMs prefixed by TenantAxxxxx cannot talk to any VMs prefixed by TenantB etc.. etc..
Still as a provider you should be the one in control of the VLANs not the tenant, this would only come into play if you are uplinking to multiple tenants own networks which is not really a likley scenario and even then you could bridge between different VLAN ID’s with untagged uplinks.
So in Summary if I were going multi tenant on UCS I would give unique blocks of VLANs to each tenant, create UCS Organisations’s for each to control resourses and certainly be using N1KV and VSG (No excuses now N1KV Essential Edition will be free and VSG is bundled with the Advanced Edition 🙂
A pleasure as always
Colin
Hi Colin,
As of today, is it still the case that you cannot negate the minimum Read-Only privileges for those that can log into UCSM? I can understand when clients are a bit wary of letting anyone with Active Directory credentials log into UCSM, even if it’s just with Read-Only privileges.
Thanks,
Mike
Hi Colin, thanks for answering – but i’m still missing something. We would like to use fcoe, meaning we want ethernet and fc on the same interface on nx5k. We don’t want to connect trought fc uplink ports directly. Is it possible?
Thanks
SGT
Ah Think I’m with you now.
If you are after going FCoE between the Fabric Interconnects and the Nexus 5500 this is not currently possible, this is due for inclusion with the next major UCSM update v2.1 (Still can’t talk too much about it 😦 )
I have drawn how you need to connect this up today along with how it should be in UCSM 2.1
Hope that clears things up for you.
Nice info about the 2.1 release.
Great blog!
What is the difference between a “full state” and “all configuration” backup? From the description in UCS, “all configuration” pretty much sounds like everything….so what is “full state” backing up that “all configuration” isn’t and why would I choose one or the other?
Thanks!
Hi Nick
As the name might suggest the full state backup as well as the complete UCS config also backs up the current STATE of the system, i.e. which Service Profiles are associated to which blades etc..
Another big difference is that the full state backup is a binary file which is not easily read. Also the only way of restoring this file is via a full system restore after defaulting the Fabric Interconnects. So as last resort if you have to use it.
The All_Config Backup is an XML file, which is just the entire config of the system. it can re restored on a running system and will warn if the restore conflicts with a current setting and gives you a couple of options to overwrite, merge configs or ignore etc…. You can also open and read this file in any txt, xml or web browser viewer.
I always take both periodically especially before doing any major work. Like upgrades etc.
The other backup options are partial All_Config backups which I don’t really tend to use much if at all.
Hope that clears things up.
Thanks for getting involved.
Regards
Colin
Why doesn’t the ucs support community VLANs – technical reason? Also while using isolated VLANs in combination with the 1000v, the configuration is very convoluted (mark them isolated on the UCS server uplinks, configure the pvlan uplink port-profile trunk with the primary vlan as a native VLAN). Can you help explain the encapsulation/decapsulation within 6140s.
Hi Ajay
Another great question, I have wondered that too 🙂 the NXOS on top on which UCSM sits certainly do support community VLANs, so perhaps a restriction in UCSM.
Luckily whenever I have setup PVLANs nativly in UCS Isolation VLANs was all I was after.
You mention you also have Nexus 1000v, so I would suggest you pass all VLANs as regular VLANs to the VEM’s and configure the PVLANs on the N1kv only they do support community VLANs so hopefully that work for you.
Re encap/decap, if were still talking about PVLANs there is no encapsulation involved the traffic flow is based on VLAN tags.
Regards
Colin
http://www.cisco.com/en/US/docs/switches/datacenter/nexus1000/sw/4_0_4_s_v_1_3/port_profile/configuration/guide/n1000v_portprof_6pvlan.html
Great Blog!
My question is about mobility of profiles between a B200-M2 with an M81KR, and a B200-M3 with a vic 1240. I believe we can create a service profile with host firmware package and management firmware package that has both adapter and bios packages for both blade types (True?). What I am wondering about is how would ESX 5.0 handle booting up on an M3 with a vic 1240, when it was installed on a B200-M2 with an M81KR.
Hi Duane
Correct, You can have a single firmware policy specifying every type of hardware in your environment if you wished. i.e. just a a single Host Firmware Package and call it 2.0(4a)_Update for example, and tick all of your boxes for B200M2 and B200M3 along with the boxes for the M81KR and VIC1240. Then whenever that SP is assocaited with either Model blade they would be up/down graded to that version prior to association.
From an OS point of view the driver is the same for the M81KR and VIC 1240/1280 so there will be no issues there.
The only time you have to think about moving service profiles between servers with different Mezzanines is if you were using a non VIC; M7xKR, or an Ethernet only Mezz, but the system would fail the association if the resource requirements of the SP are not met by the hardware.
The only instance I have found when using Cisco VICs is when moving a service profile from a half width blade to a full width blade with two mezzanine adapters. UCS tries to be clever and will rightly distribute your Virtual Adapters across both mezzanines. i.e. vNIC0 on Mezz 1 and vNIC1 on Mezz 2, this can cause your ethernet adapters to get re-ordered each time the SP is moved between them. Of course you can just quickly KVM into the host, select the correct vNIC MAC address as your management NICs and your back up and running again, but thats when you could also use a “placement policy” to try and keep the adapters consistant from an OS point of view.
Hope that helped
PS Am Jealous (still waiting on my M3’s for my Lab)
Regards
Colin
Regards
Colin
Hi Colin,
Thanks for all the previous answers. I am back to bug you with a couple of more questions.
1. When defining static server to FI uplink pinning using a pin group, once I define a FI port as part of a pin group for a specific vNIC configuration, can I use the same port (which was earlier used in the pin group) for some other pin group? I guess the answer to that is Yes. Please correct me if I am wrong. Also, is that port (already used in a pin group) available to other servers which do not have any static pin group defined for dynamic uplink pinning?
2. If using dynamic or static pinning on the FI uplink some servers are pinned to FI A uplinks under normal operations, howerver, because of the uplink failure on FI-A get pinned to FI-B uplinks. Would they failback on restoration of the FI-A uplink automatically? If not, is there a way I can do that manually?
3. On IOM to FI link failure happens, there can be different behaviors depending on the fact that I ack the chassis or DO NOT ack the chassis. I know what are the pros & cons of ack & no-ack. What I want to know is since, everything is in favor of not acking, what would be the scenario under which one would ack after failure of an uplink from the IOM to the FI?
-Regards,
-Tarun
Hi Tarun
1) I don’t tend to use static PIN groups very often (if at all) unless in very specific use cases where I need to guarentee dedicated uplink bandwidth to a particular work load. But in answer to your question yes you can use the same uplinks ports (Targets) in different PIN Groups (Just tested it)
2) If a vNIC was statically pinned to an uplink and that uplink failed then that vNIC would NOT be dymanically pinned to another uplink, When the uplink target on Fabric Interconnect A goes down, the corresponding failover mechanism of the vNIC goes into effect, and traffic is redirected to the target port on Fabric Interconnect B.
3) Thing to bear in mind is that Re-ACK’ing a Chassis will cause approx 15 seconds of downtime to all blades in that chassis as all FI -IOM ports are reset. A failed link once re-established will come back without a Re-ACK. The only time you would need to Re-ACK the chassis is if you were reducing / increasing the number of FI to IOM links which of course you can plan in a maintainence window.
As I side note I have seen a Chassis Re-Ack take out an entire exterprise for over an hour!. Hoever that was down to a “Perfect Storm” of misconfigurations and poor practices. but I’ll share it with you.
We had a Chassis was Re-Ack’d and rather than the 30 or so seconds of expected outage we lost all VM’s and vCenter. What had happened was that there were two ESXi hosts in the same chassis which were clustered, they had a keepalive timeout of 30 secs, they were only referecing each others IP, and were set to power down all VM’s in case of being isolated. So you can see where this is going. So after an hours work of KVM’ing into ESXi hosts, disabling lockdown mode (as vCenter was a VM) powering up SQL servers, then AD then vCenter then all VM’s etc etc.. was a real pain.
Hence the best practice to reference default gateways in clusters, spread hosts across chassis, minimum of 3 hosts per cluster yada, yada , yada any one of which would have prevented this issue.
Absolutley no relevance to your question, but a real world scenario of how a Re-Ack can “Cause” or be the Catalyst for unforeseen issues.
Regards
Colin
For B440s with dual vnics can mezz 1 A path be used for 1 vmnic, and mezz 2 B path be used for the other vmnic, say if the function is for the mgmt port?
Hi Fred
Thanks for the question. And the answer to your question is Yes, Cisco UCS will actually do this for you autmatically. If you want to influence which Mezzanine a particular vNIC/vHBA is placed on then you can use a “Placement Policy”.
Each Mezzanine card is represented as a Virtual Connection *vCon” in UCS Manager so a Half Width blade would have all of it’s vNICS and vHBA’s on vCon1 Mezz 1, you using a B440 with 2 Mezzanine Adapters will have vCon1 (Mezz 1) and vCon2 (Mezz 2) as available options. So you can use a “placement policy” to distribute your vNICs and vHBA’s as you wish.
When setting up your placement policy you will likley see other vCons available 3 and 4 perhaps, these are are the New M3 Blades which have LAN on Mother board mLOM and for C Series that can have multiple PCI adapters bo don’t worry about them.
Hope that helps.
Regards
Colin
Hi Colin,
Thanks again for some excellent answers to my questions. Your blog is like a wish come true for me where I can get answers to all my questions 🙂
1. From my previous post, if a FI uplink port is already being used in a pin group, would it still be used for dynamic pinning. If Yes, then how does the server for which we define static pin group get dedicated bandwidth which is the primary purpose of static pin groups.
2. When using VN-link in HW in either PTS or Hypervisor bypass modes, can I bundle more than one vNIC’s to a single VM. If Yes, can you help me understand how (may be you can point me to a document if it exists, or create one which you are expert in doing)?
3. Chassis Discovery Policy – Is it per IOM, or per chassis? I know what it does, but, in what case would I use it to be more than 1 link. May be in circumstances where I want to guarantee that is a chassis is online it has 4 links connected per IOM or it should not come online. What do you think?
4. Power cap on individual servers – this option was included after the initial release of UCS – what is its primary use case? Is there any whitepaper or document that mentions which features would be disabled if power is not available or something like that?
5. I have repeatedly seen this question in most of my trainings – HP VC(virtual connect) allows you to hard partition a 10G NIC into 4 NIC’s each with different bandwidth like NIC1 – 2G, NIC2 – 4, NIC3 – 3G, NIC4 – 1G, however, in UCS even if I have 4 vNIC’s all of them share the same 10G(active/standby), 20G(active/active) pipe in the background & there is no way to hard partition except for partition based on QoS. How do I effectively answer this question?
Once again, a very big heart felt thank you for taking all the pain to answer my endless queries 🙂
-Regards,
-Tarun
Hi Tarun
1) No, if an uplink port is the target in a static pin group it will not be used for dynamic pinning. Thats the point of Static pinning to give a vNIC or group of vNICs exclusivle use of the uplink(s).
2) Yes you can, just add however many Network adpaters you want to your VM in vSphere and select the VM-FEX port group you want them in. Simples!
3) Chassis Discovery Policy is SYSTEM WIDE, And your correct, if your company policy is to have a minimum of 2,4 links then you can enforce it with the CDP. (3 links is supported in port-channel mode) or any number upto 8 with the 2208XP
4) It is very common in the ral world that Data Centres has a per rack power constraint, in my experience usually between 3 and 7 kW, a single UCS Chassis running hot could easily draw 5kW so you would use the power capping to keep the chassis within your constraints (you may be paying a host copy per Kw for example and this is a good way you could stay within your SLA.
Re power capping on a server basis, you can use power cap policies within Service Profiles. Each service profile can be assigned a power cap policy that defines the relative power priority of a physical server that is associated with that power profile, and the power capping group to which the server belongs. When there is adequate power for all servers, the priorities do not come onto play. In the event that the servers in a given power cap group begin to exceed their group allocation, power is allocated according to the priorities defined in the attached power cap group policy, ensuring that critical loads are throttled last. Additionally, there is an option to designate a server as having no power cap, for workloads whose performance cannot be compromised even to the minor extent that power capping entails.
The WP that covers this can be found at:
http://www.cisco.com/en/US/solutions/collateral/ns340/ns517/ns224/ns944/white_paper_c11-627731.html
5) You did very well at answering your own question, QoS is exactly how you would do it, you could do presicley what you mentioned i.e. “Chop up the 10Gbs CNA into 1 1Gbs, 3Gbs pipes for particular traffic (by vNIC) with the added benefit that if there is no congestion east vNIC can use the full bandwidth anyway.
I’ve got a follow-up question to number 1) above that I think I know the answer to, but I thought I would post it to make sure. Assuming you have one static pinned uplink and two dynamically pinned uplinks (in a port channel). I realize that the traffic to the static uplink would only see that which is in the pin group. Everything else would crowd out the dynamic ports. What happens if both of the dynamically pinned uplinks go down? I assume the traffic will use the only uplink left… the static pinned uplink. Any port in a storm I guess. Is that correct?
Hi Troy
Sounds great in Theory but I am pretty sure the if all dynamicly pinnable uplinks go down, all vNICs that are NOT a member of the remaining static uplink will go down, then rely on fabric failover or teaming to retain connectivity.
The remaining Static target uplink will not suddenly get maobbed with dynamically pinned vNICs.
Regards
Colin
Hello Colin,
In the first place thanks for the page. It really clears many questions I have. I have a very simple question here. What is wire 1,2 and 4 when we talk about the chassis and blades. Why is 3 not a number to be used when we discuss about wire in UCS?
Regards
Dhruva S Kolli
Hi Dhruva
Thanks for the question. Historically Cisco UCS as you rightly say only supported 1,2 & 4 links this was due to the pinning relationshup between the blade slots and the IOM Network ports. i.e. if you have a single link between the IOM and the FI all blades obviously have to use that single link. If you have 2 links the odd blade slots pin to link 1 and even blade slots to link 2. 3 Links was not supported, and if 4 links were used slots 1&5 use link 1, 2&6 use link 2, 3&7 use link 3 and 4&8 use link 4.
Now while 3 links was not a supported startup configuration, it is a supported running configuration. What I mean by that is; if you had 4 links and 1 link failed, the server slots using that link would failover to the other fabric, and the remaining servers would continue on the 3 remaining links. (however if you then re-acknowledged the chassis, the system would revert to 2 links.
Now the above assumes you are in whats called “Discrete Pinning Mode” which is the default. However now we have mezzanine cards which can drive upto 40Gbs of I/O per fabric, so having a server pinned to a single 10Gbs link obviously is an immediate potential bottle kneck.
To address this since UCSM v2.0 you have been able to port-channel all links between the IOM and the FI to give all servers access to the entire bandwidth between the IOM and FI (80Gbs with the 2208XP).
In port-channel mode 3 links is supported (in fact any number of links if using the 2208XP).
Hope that clears things up.
Regards
Colin
Hello Colin,
Thanks a lot. That helps.. Can you explain about the hybrid view of the port-channel mode with 3 links? I am a bit confused here.
Regards
Dhruva
Hi Dhruva
Basically in Port-Channel Mode any number of FEX to FI connections is permisable. (As it is just a LACP port-channel)
If you are using any VICs with greater than 10Gbs per fabric connectivity (VIC1240 / VIC1280) then you should be port-channeling between the FEX.
and FI.
Regards
Colin
Colin,
Thanks for the reply on my question regarding port channel. I’ve got one more question here. Lets say I have 5 UCS blades spread across 2 chassis (say two blades in one chassis and three in the other)and we have 8 uplink ports on each Chassis. So how does the pinning of servers to these blades behave.On each chassis is this how the blades are pinned.?
Blade slots 1,5 pin to uplink port1, Blade Slot 2 pins to uplink port2, blade slot 3 uses uplink port3
If this is not the case then request you to please explain the pinning in this scenario with and without port-channel
Regards
Dhruva
Hi Dhruva
Yep you got it.
In Disrete pinning mode its slots 1,5 use Link 1, 2,6 Use Link 2, 3,7 use Link 3 and slots 4 and 8 use link 4, as shown below
I would like to know if you can connect multiple 6100 FI to each other to limit the uplink connections to a 7K? For instance: there are 4 6100 FI and 2 UCS systems connecting to 2-7K. I would like to connect 6100-1 to 6100-3 to enable L2 switching between the FI. Can this be done via switch mode and is vPC supported between the FI?
Thanks, Steve
Hi Steve
Not 100% sure what you are trying to achieve with that setup and thats certainly not the way Cisco UCS is designed ot intended to work.
There are now very few if any valid reasons to put the FI’s in switch mode.
The FI’s although they look like a Nexus 5k thats been strategically painted a different colour, do not act like them (even in switch mode) they do not have the same rich L3 features (like vPC) and I’d certainly not remcommend this setup.
As to world it work, likley yes without vPC etc.. you cannot configure STP priorites etc.. so to prevent your FI’s becoming the Root bridge over your 7k’s you need to reduce the priorites on all your other switches.
In summary with the kit and functionality these days, there will always be a far better solution using End Host mode, than switch mode.
Regards
Colin
I would like know if inside UCS manager is possible check ther power consumer in AMP. Another question is how much power one fabric 6140xp more 8 blades m1 consume ? I am using the ucs power calculator, but i cant put the information in AMP, so, i have 32A is enough to me put one fabric 6140 with fc module, more 8 blades m1? im using 4 power units. thanks
Hi Thanks for the question.
I’m pretty sure that new Cisco UCS power calculator does provide the consumption in Amps (I’ll check)
https://express.salire.com/Modules/Analyses/Edit/Analysis.aspx
In the meantime there are plenty of kW to Amps calculators like the one below.
http://www.rapidtables.com/calc/electric/kW_to_Amp_Calculator.htm
Regards
Colin
Full disclosure – I’m the Cisco PM for these tools.
The correct URL for the current version of the UCS Power Calculator is http://express.salire.com/Go/Cisco/Cisco-UCS-Power-Calculator.aspx. The URL above is actually a generic redirect URL generated by the vendor’s framework depending upon which tool you use (they also host the Public UCS TCO/ROI Calculator (http://express.salire.com/Go/Cisco/Cisco-UCS-TCO-ROI-Advisor.aspx)).
Hope this helps and saves some confusion.
Thanks Bill
I’ll get the link updated.
Regards Colin
Hi Colin,
I’ve installed Windows 2008 Enterprise on Bare-metal UCS B-200 M2 server with VIC M81KR Mezannine card. UCS Manager version is 1.3(c).
The Problem that I have is that I cannot define VLANs on the NIC adapter inside Windows. is this a problem with the NIC driver ?
( Other NIC cards in other machine for example, have Advnaced Tab in the network configuration where we can define VLANs ).
( in this situation, Windows is un-aware of the VLANs so all the traffic going out will be untagged and FI sending it to the native VLAN on the network).
Thanks in advance,
Mohammad
Hi Mohammad
I’ll check this out on the kit I have in the lab next week.
First couple of things are using the latest M81KR Drivers and utilities?
Click to access b_Cisco_VIC_Drivers_for_Windows_Installation_Guide.pdf
Also as a side note perhaps to start thinking about a Upgrade to 2.0x as your missing out on lots of cool features.
Colin
Hi UCSGuru:
What is the best method to capture Flow or nbar information from nexus 6296 or nexus 5596 switches?
Hi Thomas
We are talking about two different boxes here, neither of which inhrently support NBAR.
With the Fabric Interconnects (6100/6200) setup a SPAN/ERSPAN session and either capture the out put or forward to an NBAR capable device like the Network Analysis Module (NAM)
Best doc detailing this is:
http://www.cisco.com/en/US/docs/unified_computing/ucs/sw/gui/config/guide/141/UCSM_GUI_Configuration_Guide_141_chapter45.html
A similar setup is required for the Nexus 5500 which is detailed in the below link.
Click to access b_cisco_n5k_system_mgmt_cg_rel_503_n1_1_chapter_01111.pdf
Regards
Colin
Hi Colin,
I have a question that seems very hard to find an answer too…
Is it possible to vmotion a virtual machine that is configured to use VM-FEX across UCS management domains?
Thanks
Tom
Hi Tom
If you mean vMotion between two different USM Domains when using VM-FEX affraid not as the Ports which the VM’s connect to are assigned by UCS Manager and need to remain consistant post the vMotion (Hense why all policies and interface statistics are maintained).
You can however vMotion between any blades in any chassis within a Cisco UCS Domain if using VM-FEX even if using VM-FEX in VMDirectPath Mode.
If being able to vMotion between UCS Domains is a requirement you need, then go for Nexus 1000v or just use standard VMware vDS.
Regards
Colin
That’s cool, I thought as much, I couldn’t find that info anywhere, but it makes sense.
Looks I’ll my ESXi hosts that utilize VM-FEX need to stay in the same UCS management domain.
Thanks for your response
Tom
I am not able to see WWN in MDS 9500 while I can see FC uplink ports WWN but blade server virtual WWN assigned by pool are not appear in Cisco MDS FLogi.
Hi Faisal
There was a identical question to yours asked in the “About” page of this site. (One of the main reasons I created an “Ask a question” category’ was to keep all the questions in one place) Anyway have a look, I gave quite a detailed answer with all the required troubleshooting steps.
The first thing I would check is that all your vHBA’s have WWNN/WWPNs assigned either manually or from a pool, check this by expanding the vHBAs in the service profile.
Assuming they have their addresses check the vHBA’s are in the correct VSAN (if no default VSANs are being used)
If you are booting from SAN confirm your SAN Boot Policy has the correct WWPNs for the correct targets on the correct fabric.
(At this stage you can just use dummy WWPN of the targets, the vHBA’s will still flogi into the fabric)
If above checks out. ssh into the FI’s directly, connect NXOS, and check whether your WWPNs are in the flogi database of your FI’s “sh NPV flogi database” from NXOS mode.
If they are confirm the correct WWPN is showing on the correct Fabric Interconnect, if thats good,check your fibre channel uplinks between your FI’s and your SAN switches, make sure they are in the correct VSAN and are connected to the correct fabric. The FI uplinks need to be in or carrying the VSAN you put you vHBAs in.
If thats good check the flogi database of your SAN switches, and confirm the switches have NPIV enabled. And that the correct VSANs have been created on them and the MDS ports that connect to the FI’s are in the correct VSAN. (Or carrying the correct VSANs if trunking VSANs)
Also turn off quiet boot in the default BIOS settings and have a look during boot as to whether your vHBAs are seeing the targets you expect.
Thats the order I would do it in and you should rapidly work out where the issue is or isn’t.
Come back to me if you still have issues.
Regards
Colin
Hi Colin,
I didn’t get the answer of my question. I have created SP’s, now WWN are assigned to blade servers, I have configured 2 ports 31 & 32 on FI as FC uplink ports. Now on MDS 9500, I can see 2 WWN of port 31 & 32 but can’t see the WWN of blade servers which were delivered from WWN pool. Is there some step required more.
Hi Faisal
Completeley understand what you have done and where you are, and have seen your issue many times, it will be that you have not created the VSAN on the MDS (if using any other VSAN than 1) or have not put your MDS ports in the same VSAN that your vHBA’s are in.
If you go through the troubleshooting steps below you will find and rectify your issue.
Also confirm you have NPIV enabled on your MDS swicthes.
switch(config)# npiv enable
Regards
Colin
Hi Colin,
In MDS they are using VSAN1 which is default and I am using Default VSAN as well in SP. On MDS they are using MPIV mode so that FC uplink ports are up on FI. But still I am not able to see Blade servers WWN on MDS while I can see FI physical port WWN on MDS. Do I need to do any connectivity with FI FC uplink ports (31 & 32) with blade FC ports.
SAN team is saying to enable MPIV mode at FI as well. But I can’t see MPIV is enabled or not.
Hi Faisal
Ok if your using default VSAN on the FI’s and VSAN 1 on the MDS that should be fine.
You would know if NPIV was not enabled on the SAN swicthes as you get a very helpful message in UCS manager that NPIV is not enabled on the upstream SAN switch if it is not. (and the fc FI uplink will not come up)
Your issue most likely is then that your servers are not trying to flogi into the fabric.
Are you booting from SAN? Have your created your boot policy to boot of your vHBA’s? (interface name must match in boot policy and SP i.e. fc0/fc1)
have you put some WWPN’s in as boot targets to initiate the flogi, have you turned quiet boot off so you can watch the vHBA’s initialise and discover the targets. Have you checked that you can see your WWPN’s in the flogi database of your FI’s?
Again can’t think of another way to word this but if you step through the steps in my first response you should quickly resovle your issue.
Regards
Colin
I have several fc-node ‘named policy unresolved’ faults. I have no vHBAs configured but do have WWPN/WWNN default pools configured. 2.04a code. Any ideas how to clear? thanks.
Fred
Hi Fred
That error usually means you are referencing a pool in a policy that is not / no longer there.
In my experience this is usually a default pool that has been deleted but is still being referenced in a Service Profile somewhere.
To be sure have a look at the fault description and code
e.g.
effected object (This will be the pool in question)
code: F4525239
description: Policy reference identPoolName does not resolve to named policy
Have also seen this after an upgrade or if your pools are in child Orgs other than root.
As a test try re-selecting the pool in question under your effected SP/SP Templates and see if that cures it.
If not try creating a pool of the same name under root if its not already there.
If all else fails give TAC a call.
Good Luck
Colin
You nailed it. created ‘node-default’ pool (empty) under WWNN. Faults cleared. thanks for your help.
Hi Colin,
Which settings of services profile requires a reboot of a blade?
Where do I find a full list of the same?
Hi
There is no list (as far as I am aware), and there are far too many to list here.
But essentially if its a change that modifies the hardware i.e. BIOS, Adding a vNIC/vHBA etc.. then a planned reboot would be required.
If it is a soft change like adding/removing a VLAN to a vNIC etc.. then no reboot is required.
Why not start a list and share it with the Cisco UCS Community?
Regards
Colin
We are thinking about purchasing a new UCS infrastructure but have had mixes reviews around reliability and bugs. Please can you let me know if the system is reliable enough for a highly available production environment?
Hi Barry
Thanks for the comment, I don’t really hear these sort of concerns these days (2 years ago was a totally different matter) No most customers know the many benefits that Cisco UCS gives them, even if they have not adopted the technology yet.
The “endorsement” if you will that Cisco UCS is certainly stable in production environments, comes from the customer bases in which I have been deploying it in to. 2 Years ago it was all the trendy, early adopter type clients, but in the last 12 Months I have designed and deployed Cisco UCS in extreamly risk averse financial institutions and major Banks.
I would certainly recommend you try and get a PoC setup and have a play and see for yourself. The main thing I would suggest is that you have an UCS engineer give you a good overview of the tech and walk you through the setup. While not complicated it is a different mindset to what you are likley used to.
UCSguru.com is always here to give you impartial advice and assistance.
Good luck and have fun on your journey to convergence.
Regards
Colin
Hi,
I am doing Boot from SAN. UCS blade B200M3 has been started and I have done VMWARE 5.1 installation after completing the installation it reboot, When it reboot after scaning the SAN disk, it showing black screen and cursor is blinking. VMWARE installation is complete and I can see Symatrix DMX3 disks as well. But in my all servers I had same problem. What could be the reason.
Hi, I am still now able to do boot from SAN. I had the following in FI,
adapter 1/2/1 (fls):3# lunlist
vnic : 16 lifid: 5
– FLOGI State : flogi est (fc_id 0xe81a08)
– PLOGI Sessions
– WWNN 50:06:04:8c:52:a6:69:49 WWPN 50:06:04:8c:52:a6:69:49 fc_id 0x34002b
– LUN’s configured (SCSI Type, Version, Vendor, Serial No.)
LUN ID : 0x0000000000000000 (0x0, 0x4, EMC , 101669060000)
– REPORT LUNs Query Response
LUN ID : 0x0000000000000000
LUN ID : 0x0031000000000000
– Nameserver Query Response
– WWPN : 50:06:04:8c:52:a6:69:49
Is it correct. I can do installation of ESXi 5.1 but can’t boot it. Urgent support required.
Hi Faisal
As you need urgent support, the best thing to do is open a Service Request with Cisco.
REgards
Colin
Is there a way from the UCS side to tell it the Upstream VLANS are configured on the Port-Channel Trunks, say coming from a Nexus 5k?
Hi Allen
Not as such, there are things you can do to help test it i.e. put a VM into that VLAN and see if you can PING the default gateway on or beyond the upstream switch, if your sure you are carrying the VLAN on the vNIC and the FI uplink and there is no connectivity chances are the VLAN is not enabled on the upstream switch port(s).
But to be sure you would have to check the upstream switch.
Regards
Colin
We are trying to benefit from Microsoft Server 2012 Hyper-V 3.0 “Virtual Fibre Channel adapters”.
When we wanted to build a HA-cluster within VMs we needed to use iSCSI for this, but I assume we should be able to use FC as well now.
UCS should be the ideal solution for this and the Cisco VIC FCoE Storport drivers version 2.2.0.9 seemed to support this.
Unfortunatly that gave me NPIV errors and from what I understood I needed to wait for the official UCS 2.1 realease.
It’s there and it’s up and running, but using the latest drivers (2.2.0.17) it says “the device or driver does not support virtual Fibre Channel”.
We’re using a NetApp SAN directly connected to our Interconnects using FC (Swith mode).
Is it possible (and if so, how) to benefit from these Virtual Fibre Channel adapters?
Hi Peter
Thanks for the question,
I have also been in the situation of requiring vHBA passthrough from a Cisco VIC to a VM (Tape libary access etc..), and you are right this was not supported. and did not work, if for example trying to use VMware’s VM DirectPath I/O on a vHBA.
What is needed is either a VM-FEX type setup for vHBA’s or supporting passthru of the vHBA of the host.
I know that SR-IOV enhancements in the Hypervisors should make this possible, but have not had any time to play around with this as yet.
I don’t have a huge amount of experience on the Hyper-V side (but am getting more interest in it these days) Rather than me lab up your environment, I would suggest you talk to Cisco TAC.
Sorry not to be able to advise more on this one.
Regards
Colin
Hi Colin,
Greetings of the day!
I am here with another simple, yet difficult question because I am not sure of the correct answer ( or may be I am! :))
I would try to explain that using an example.
Step 1 – Lets say I create a Service Profile Template by the name Oracle_RAC_Template. Within this service profile template I define a boot policy for SAN boot which has primary/secondary boot target WWPN’s & a boot LUN (‘0’ most of the times).
Step 2 – I create 5 Service Profiles using the above template Oracle_RAC1 through Oracle_RAC5.
Now my question is, since all the 5 service profiles are created using the same template, all of them would have the same primary/secondary boot target WWPN & the same boot LUN for SAN boot. Which in turn means they boot from the same place in the SAN storage box which does not makes sense as each physical server should see a separate boot area on the SAN box.
So, as I see there are 2 options here as follows:
1. I manually change the primary/secondary boot targets for all 5 service profiles which I created out of the same template initially, which would kind of defy the very purpose of using templates for rapid deployment of SP’s.
2. I do some magic on my storage side with zoning & masking which allows all of the 5 service profiles to use the same primary/secondary boot targets & the same LUN number, but, still depending on the source WWPN take it to the correct SAN boot area.
I am kind of inclined more towards option 2 being correct (may be because of my SAN ignorance), but, I would love to be corrected !!
Thanks again for spending so much time in reading & answering all the questions.
-Regards,
-Tarun
Hi Colin,
Looks like you missed this one 😦
-Regards,
-Tarun
Hi Tarun
Thanks for picking me up on missing this one, in my defence I was on Holiday as well as it being the day before my Birthday 🙂
OK
So Your Step 2 is not quite right. You are right that if you had a common ‘Boot from SAN’ policy for all of your service profiles they would try the WWPN of the targets in the same order and potentially all hit the same WWPN of the array at boot time.
The Boot LUN, as you say should indeed be 0, however this does not mean that all LUN 0’s on the target WWPN is the same LUN. You will have a separate small boot LUN for each host, these LUNs will have a unique Array Logical Unit (ALU) but then also have a Host Logical Unit (HLU) which you can assign, in this case 0 for all boot LUNs. So what you end up with is many LUNs all with unique ALU’s from the Arrays point of view, but in the case of Boot LUNs all presented to the hosts as LUN 0’s. So how do we ensure the host boots of its correct LUN?, thats where Masking on the Array comes in.
We use Zoning on the SAN Switches to only allow the Host HBA WWPN’s access to the Target WWPN’s we want but as I have shown above the Host would potentially see all of the LUNs on the array, even the ones that are not relevant to that host.
So to prevent this we “Mask” at the array, which is basically create a group (usually called the Servers Hostname) and then put both the LUN and the WWPN of the Host (Initiator) in this group. That way each host can only see the LUNs that have been masked to it. In Networking terms you can think of a Zone like a VLAN and a Mask like an Access Control list (ACL)
So Host A booting from LUN0, will be booting from a completely different LUN than Host B booting from LUN 0 even if using the same Target WWPN (Like in a Boot Policy)
OK, All that said, in larger environments you may want to spread the server boot I/O load across multiple Array WWPN’s and the only way to do this is to use multiple boot policies with the target WWPN’s in different orders. (I generally don’t as I prefer a single boot policy and most servers do not tend to get rebooted that often)
The scenario when I would definatley consider this is in VDI environments when all Virtual Desktops for a company all get booted at 09:00 in the morning, which could potentially cause a “Boot Storm” which causes intense concentrated storage I/O that can easily overwhelm a storage subsystem.
This could make the brand new VDI Solution you just installed slow and potentially unusable, not a good place to be.
A typical desktop VM running Windows 7 will generate from 50-100 IOPS while is it booting; but this drops to about 5-10 once booted and running normal workloads.
There are numerous design options to prevent issues from Boot Storms, with the most common being intelligent use of SSD or Flash drives for the boot image(s).
Once again I’ve gone a bit off topic but all good relevant info.
Regards
Colin
Thanks a ton Colin! As usual amazing depth.
-Regards,
-Tarun
Hi Colin,
I have a question regarding connecting a standalone server (for example C series server or any other non Cisco server) directly to Fabric Interconnects. Is this setup supported?
Can I connect the C Series rack server redundantly to Fabric Interconnects without FEX? I understand that the UCS Manager would not be able to manage devices in that scenario.
Thanks for your time.
Best Regards,
Adi
Hi Adi
The quick answer to your question would be No, the correct way of attaching Cisco UCS C Series servers would be via the 2232PP FEX as I’m sure you are aware.
Prior to version 2.0.2 you could connect the C Series Data ports directly to the FI’s and the management was via a pair of 2248’s FEX’s but with version 2.0.2 and above this is no longer supported and only 2232PP FEX’s are supported
Re Connecting 3rd Party Servers directly to the FI’s
You could put your FI’s into switch mode and connect servers directly to the FI’s, but this would not be a overwhelming reason to put the FI’s into switch mode in my opinion, far better to just buy an upstream LAN switch.
You could leave the FI’s in End Host Most and connect a Server into an Appliance port (Designed for NAS direct attach), but this again this is not ideal as you cannot prune VLAN’s off an appliance port, so the server would recieve lots of unwanted broadcast traffic fromm other VLANs, and while it would work (Appliance ports Learn MAC addresses) I wouldn’t recommend it and that setup is likley not supported.
In short wouldn’t recommend directly attaching any servers to the FI’s at least in a production environment.
Regards
Colin
Thank you for the detailed reply. I appreciate it.
Regards,
Adi
Hi, Colin,
Do you know if it’s possible to connect a 5108 (w/2208XP) to 2232PPs hanging off some 6296 FIs ? Or do they _have_ to connect directly to the 6296s ? I’m guessing this sort of FE “stacking” can’t be done, but I thought I’d double check. 🙂
Cheers
Also, is it possible to have C-Series UCSM integration with _only_ 1GbE available ? Eg: 2248s hanging off 6248s, but then only 1GbE copper to the servers themselves ?
Hi
The 2248’s are no longer supported as from UCSM version 2.0(2x) so if you have any you will either need to replace them with 2232PP’s or do not upgrade beyond UCSM 2.0(2), If you do upgrade UCSM to 2.0(2) or beyond your 2248’s will no longer be recognised.
All supported options for C Series integration require 10Gbs connections for the Data Path, if you only have a C Series with 1Gbs ports the integration with UCS Manager is not an option. You need a 10Gbs Expansion Card P81E / VIC1225 etc..
You can of course use a 1Gbs C series in stand-a-lone mode.
All Supported C Series Intergration options can be found here
Regards
Colin
Hi Thanks for the question, and you are right you cannot “Daisey Chain” Nexus 2000’s (The N2232 and UCS IOM are both Nexus 2000’s in essence)
The FEX Standard (802.1BR, Bridge Port Extension) does however allow for hierarchical port extenders, ala VMFEX and Adapter FEX, in which the Nexus 2000 (the IOM in the case of UCS) acts like a passthrough between the UCS Mezzanine card, which in itself if a FEX (Port Extender) and the Fabric Interconnect which is the Controlling Bridge.
Regards
Colin
Thanks, that sort of answers the question but raises another.
Basically, would it be possible to connect 6296 -> 2232PP -> 2208/5108, or does it have to be 6296 -> 2208/5108 ?
Cheers
Hi
The only supported options for the components you mention are:
6296 -> 2208/5108
6296 -> 2232PP -> C Series (single wire option with UCSM 2.1)
Regards
Colin
Can you help me understand why, when using SAN switches, each Fabric Interconnect (FI) must be connected in the following manner:
FI-A –> SANSwitchA
FI-B –> SANSwitchB
(each SAN switch has a connection to the “A” and “B” side of the storage array)
Why can’t I hook FI-A to SANSwitchA and B? So that a single switch failure doesn’t take out all storage connections through a single FI? I undertand that you can design the service profiles so that traffic goes out each FI, but don’t understand why Cisco doesn’t want you to do this or why you can’t use the same vSAN on both FI.
Thanks.
-Bill
Hi Bill
Thanks for the great question, and one I find myself explaining to customer’s allot.
Historically Storage Networks have always been 2 separate networks, SAN A and SAN B, this as I’m sure you are aware is to provide two distinctly separate paths for the storage traffic in order to provide full resiliency.
These two separate networks obviously provide multiple paths between the Host (Initiator / Server) and the Array containing the logical disk (Target), and all these paths can be intelligently used by multipathing aware drivers (MPIO, EMC PowerPath etc..)
OK so back to your question about why don’t we dual attach the Fabric Interconnects to the SAN Switches like we do the Array Controllers.
Well as you may know in the default N Port virtualization (NPV) mode the Fabric Interconnects act like an Initiator (N Port) as far as the upstream SAN Switches are concerned.
So as with any initiator it is best practice to have one HBA to SAN A and a Separate HBA to SAN B, so you can think of the Fabric Interconnects as HBA’s. So that answers your first question.
Your second question around, if the point is to have two completely separate SAN Networks why are the Array Controllers often dual attached to both fabrics.
This actually provides several benefits the main one being around fail over.
As you may know whenever you create a LUN on an array, that LUN is active on a single Storage Processor (SP), if the active SP ever failed then the secondary SP would take ownership of that LUN.
However imagine the scenario in the above diagram if Fabric Interconnect A or SAN Switch A failed. If the Blade was using a LUN which was being owned by SP A and SP A was only attached to SAN Switch A, the server would now be isolated from its LUN, as all paths to SP A would be broken.
Now depending what failed and what array you have this at best would cause the LUN to failover to the other SP which while works well is a “Moving Part” in the failover process that should be avoided as a best practice.
Hence the best practice to dual attach the SP’s in the Array to both fabrics, as this enables the Host to have a path to its LUNs across both fabrics regardless to the SP that owns them.
I mentioned this also has other benefits; the one I capitalise on most is when performing a migration of a host from one SAN to another or even a SAN replacement.
For example a few weeks back I moved a client from a Brocade SAN to a Nexus SAN and had to move all their Servers and Arrays to the new Nexus Fabric with no downtime.
This was a fairly easy task as all the Arrays (VNX and Clariion in this case) were dual attached to both fabrics. So it was a case of, install the Nexus Fabric, configure all the aliasing and zoning etc..
Then move each host and array off the Brocade SAN A and onto the Nexus SAN A. This obviously breaks SAN A but as long as all paths across both fabrics were active this will not cause the Host to lose connectivity to its LUNs (Regardless of which SP own s them)
Then once done confirm all is well and all paths are back up and then do the same for SAN B.
Appreciate we got a bit off topic, but thought it was a good opportunity provide some context and examples around the topic for other readers.
Regards
Colin
I would like to clarify on this answer a bit more off your diagram above.
We are running 2.1.1a using FCoE. Our SAN shows “Partially Connected” after the migration from directly connected to using a SAN Switch. We do not use VSAN 1 and do not have it configured. We use VSAN 11 for Fabric A and VSAN 12 for Fabric B. Are questions are as follows (Any help would be greatly appreciated):
VSAN Configuration on the SAN Switches
1. Should each Fabric -> SAN Switch follow a separate VSAN. i.e. Fab A (VSAN 11) to SAN Switch A (VSAN 11), and Fab B (VSAN 12) to SAN Switch B (VSAN 12).
VSAN Configuration inside UCSM
2. Should we just have 2 vHBA (vHBA 1 configured for Fabric A VSAN 11 (Cloud) and vHBA 2 configured for Fabric VSAN 12 (Cloud).
Hi Todd
The answers to your questions are as follows:
1) Yes Each Fabric should have a unique VSAN ID or IDs (if multiple VSANs per fabric) and if using FCoE only trunk the FCoE VLANs to the correct Fabric. i.e in your example if you use VLAN 3011 for VSAN 11 (Fabric A) and VLAN 3012 for VSAN 12 (Fabric B) then VLAN 3011 should only be mapped to the direct link or Portchannel between FIA and FCoE Switch A and VLAN 3012 should only be mapped to the direct link / port channel between FIB and FCoE Switch B.
2) Yes thats correct, I only tend to add additional vHBA’s when using multiple VSANs within a single Fabric (Rather than relying on upstream Inter VSAN Routing (IVR))
Regards
Colin
Hi Colin ,
Does the same apply when using direct attached SAN. Is it still best practises to connect SPA/SPB to Fabric Interconnect A and B ?
Hi Craig
My view would be yes, as the FI’s then become the fc switch and if you lost an FI your host would still have a path to both SP’s. So no failover of the SP’s within the array would be required.
Colin
Your original post went a long way to answering my questions.
Just a couple of quick questions.
Situation – UCS connected to existing SAN A and B (Brocade Switches). Upgrading to new Brocade switches. All connections follow your diagram above.
My understanding of the Brocade tech is that the existing configs can be imported via ISL links to the new switches. Then the connections can be moved. We are going to have to upgrade the code on the existing switches to make this happen. Appears to be about 4 upgrades/reboots each switch.
1 – When the existing switches are upgraded and rebooted, will there be a noticable outage to the ESX hosts/VMs? Everything I’ve read seems to say no… just not explicitly. Past experience with UCS firmware upgrades and FI reboots seems to also confirm this.
2- When the old and new switches are connected vis ISL and we migrate connections over, should we consider creating new connections from FI to the new switches OR should we just move the existing connection from old to new?
Thanks in advance for your reply
Hi Jay
1) First confirm that your hosts can see their LUNs over both Fabrics, then you should be fine to upgrade/reboot one fabric at a time (Make sure all paths are re-established fully before moving on to the next fabric)
2) I would just move the connections from the Old switches to the New (Again do one fabric first, confirm you see all the UCS WWPN behind the FI in the Flogi database on the New Switch, and confirm the host can see its storage over that fabric, before moving the links to the other Fabric)
Good Luck
Colin
Hello Colin,
I know I have asked you this question earlier But would be great if you could bear with me for one more time. I would like to clear my doubts on the Discrete Pinning Mode and Port-Channel Mode?
Here is a scenario, we have a mezzanine card for our blades, two 5108 Chassis, two 6248UP FIC, and 5 blades. First three blades are in Slot 1,2 and 3 respectively in Chassis 1 and Blades 4 and 5 on slots 1&2 on Chassis 2.
I have 4 ports going from each Chassis to the FI’s. (2 connections from FEX A to FI A and 2 connections from FEX B to FI B. This is done on each of the Chassis)
So how does the connectivity from Blade to FEX to FI work?
Regards
Dhruva
Hello Colin I just wanted to understand how the port channeling can be done. thats it… In the discrete mode I understand the whole connectivity when we have all the blades connected and all the fex’s connected. I just wanted to understand the connectivity in the scenario I described above in Discrete Mode.
Port Channles Mode I guess that would completely depend on the configuration that we do.
Hi Dhruva
I generally use port-channel mode in most cases, as if you are using a VIC 1240 / 1280 they provide 20 and 40Gbs per fabric respectivley, so if you left your FI’s in discrete pinning mode, each blade would only have access to the 10Gbs link it was pinned to, which as you see would be an immediate bottle kneck.
Hence port-channel all the IO Module to FI links to give any server access to the full bandwidth of the port-channel (80Gbs if using the 2208XP) which eliminates this potential bottle kneck.
The only time I leave an FI in Discrete pinning mode when using a Gen 2 VIC, is where a customer wants deterministic and consistant failover.
i.e. if a link failed in a port-channel no failover occurs, infact if in the highly unlikley event you lost 7 of your 8 IOM to FI links still no failover would occur as the port-channel would still be up. So you would now have all of your vNICs mapped to that fabric contesting for the single remaining 10Gbs link.
If the FI was left in Discrete Pinning mode then failover would occur in the event of a single link failure (for vNICS with fabric failover enabled, for the Servers pinned to that particular failed link) This would provide a more deterministic failure pattern. But I would still prefer going down the port-channel route unless this deterministic failover was paramount to a customers requirement as other wise you would never get the full use of the additional bandwidth that the Gen 2 VICs are capable of due to the server only having access to the single 10Gbs link.
Regards
Colin
Hi Dhruva
If you are using Discrete Pinning Mode (Default) with 2 Links per IO Module all odd Blade slots (1,3,5,7) will pin to Link 1 and all even Blade Slots (2,4,6,8) will pin to Link 2.
Then its just a case of which Fabric you have mapped each vNIC to to see which FI they are using.
You can also get all this info from having a look at the VIF paths under each service profile. (see one of my previous posts “Understanding VIF Paths”)
Hope that clears this up for you.
Regards
Colin
Thanks a lot Colin..
I think the following link has explained me the whole stuff clearly… Thanks colin… I dint want you to concentrate much on the question i asked.
http://www.definethecloud.net/tag/ucs
Thanks & Regards
Dhruva S Kolli
Glad Joe cleared that up for you.
Regards
Colin
Hey Colin-
What is the max number of VM’s I should be able to run via VM-FEX on each ESX host assuming the following:
6296 FI’s
4x uplinks per 2208XP IOM in port channel
5x B200 M3 running vSphere 5.1
All gear running UCS 2.1 (1a)
I have everything setup and running great in high-performance mode with up to 23-24 VM’s per blade, however, once I add an additional VM to the blade it’s not reachable. It seems I’m incurring a limitation somewhere. I’ve tried disabling high-performance mode on the port profiles, but that didn’t work either. Currently open TAC case, but haven’t gotten to the bottom of it yet 😦
I guess I should also mention my vNIC configuration:
2x vNIC for management
2x vNIC for NFS storage
2x vNIC for UCS DVS uplink
50x dynamic vNIC
Hi Jeff
Assuming you are using the VIC 1280, these can support 256 virtual interfaces, the 6200 FI’s support 63 Virtual Interfaces per downlink so in your setup with 4 downlinks would support 252 Virtual Interfaces on you VIC 1280. Subtract the number of static Virtual Interfaces you have (6) leaves you a maximum of 246 Dynamic Virtual Interfaces available for VM-FEX.
So you should be fine with your 50x Dynamic vNICS.
But I’m sure you are aware of all this and how it works on paper.
But as we all know whats fine in theory can be quite different is practice, thats where things like this blog and the Cisco Support Community really add value.
So not sure what would be causing your issue. But I would be very interested to find out.
So once hopfully TAC work with you to resolve the issue, please post the solution back to this thread.
Good Luck
Regards
Colin
Hi Colin-
Just got off the phone with TAC and have a resolution. The problem in my configuration was as follows – I hadn’t configured any UCS DVS static vNIC uplinks on my second physical adapter in my blades. Basically, the 2x vNIC for UCS DVS uplink that I had configured were both assigned to adapter 1 (VIC 1240 in the B200 M3). Since my dynamic vNIC policy had created about 25 dynamic vNICs on each adapter 1 and adapter 2, once my VMs had utilized all 25 on the first adapter, VMs couldn’t connect to the dynamic vNICs on the second adapter. Kind of hard to explain… All I had to do to fix this was create 2 additional static vNICs for DVS uplinks and assign them to be on adapter 2 (VIC 1280 in the B200 M3). Then, on the ESX host configuration, add all 4 static vNICs as uplinks. This allowed me to utilize the dynamic vNICs that were created on both adapter 1 and adapter 2. Whew.
Thanks,
-Jeff
Great news Jeff
And a great real world gotcha for everyone to be aware of.
Makes sense when you think about it as they are seperate adapters, I doubt you would have had the issue if you had used the Port Expander with the VIC 1240 as all of your Dynamic vNICs would be on your VIC 1240.
Makes more sense when you look at the diagrams below.
In some respect I’m really envious of the guys in TAC and Cisco, all the great people and info they have at their disposal 🙂
I’d be like a “Kid in a Candy Store” there 🙂
Regards
Colin
Hi Colin,
I want asking something. Usually between chassis and FI, have connectivity like this. Fex slot 1 (left) to FI A, fex slot 2 (rigth) to FI B.
what if fex slot 1 ( left- seen from rear chassis) connected to FI B and then fex slot 2(rigth) connect to FI A with 4uplink port channel. Is it will causing any problems?
Waiting for your answer soon.
Thanks and have a good day.
Hi ZT
The short answer to your question is Yes it would work.
Nothing at all stops you from having your FEX A in the IOM 2 (Middle) position and FEX B in IOM Slot 1.
My question would be why would you want to do that, there is a huge ammount to be said for best practice and the best practice is to have FI A connected to FEX 1 (The left of the chassis from the back) and FI B to FEX 2 (middle slot)
It would wind me up if I was was called in to trouble shoot an issue and had to spend time deciphering the topology before I got stuck in.
This job can be tough enough as it is, without us adding to it voluntarily 🙂 so lets all try and keep to the defacto standards and best practices 🙂
I have attached a quick cheat sheet for you below.
Regards
Colin
Hello Colin,
Back with another simple question I guess… Well it is regarding the Management Port on the FI’s.
While configuring the FI’s we give a cluster Ip as well as an Individual IP to each of the FI’s? Why do we need these management ports? Is it for a fall back? And did we have any such situations of the cluster IP failing once configured?
So to access this mgmt port, do we need to have it connected to the Layer 3 switch directly? In case we do not want to connect it directly to a Layer3 switch , we need to have a layer2 in that connects to layer3,. Here again there is more usage of equipment right?
So the mngmt port?
Hi Dhruva
The Management ports on the FI’s are the physical port in the Management vrf to which you assign the physical IP’s of the FI’s MGMT0 Interface. The same as in the Nexus swicthes if that helps.
If you did not connect the MGMT interfaces you would not be able to manage or even PING the FI’s.
These are Layer 2 Interfaces and as such should be connected to a layer 2 port (So either any port on a Layer 2 switch or a layer 2 (switchport) on a Layer 3 switch. This is because the MGMT 0 port on an FI obviously has to be in the same VLAN as the MGMT Port of the other FI.
The cluster address is shared between them and is owned by which ever FI is acting as the primary FI.
Also remember that your KVM access to all the CIMC adapters in the blades go through these MGMT 0 Ports, so also remember to have a UCS Management subnet large enough for your 3 FI cluster addresses and then enough for each blade (Mandatory) and each Service Profile (Optional)
Re your question about failure of cluster IP addresses, the IP addresses themselves do not fail, but in the 100 or so Cisco UCS Upgrades I have done I have had 4 Occasions when unplanned outages occured. This was outages to UCS Manager during the UCS Manager upgrade NOT to the Forwarding of traffic, which would be more serious. One of the reasons I always do UCS Upgrades (or any upgrades for that matter) within a planned outage window, even if no outage is anticipated, for as we all know sometimes Sh*t just happens.
Regards
Colin
Thanks a lot Cloin, Another question I have is, the planning of vnics on esx. We have got two FI’s, Two 3750 switch, two MDS switch and two chassis with 5 blades (3 blades in one and two blades in the other). We do not use a nexus switch in our environment.
Here comes the question of deciding on how many vNICs, vHBA’s we need on every Blade? Please guide me on this and also request you to share pre-req’s to consider on designing this.
Hope your 3750’s are connected to your FI’s via 10Gb other wise you may have a bit of a bottleneck even if using a port-group of multiple 1Gb links.
Re: how to present your vNICs and vHBA’s to your ESX Server you have many options but it’s pretty much up to your preference.
Some like to mirror the ESX servers in their physical environment for example 2 vNICs for Management, 2 for vMotion, 2 for VM Traffic. etc..
Some like to simplify their environment as much as possible by just having 2 vNICs (One Fabric A and One Fabric B) Team them and then just seperate traffic by Port-Groups in a DvS or Nexus 1000v. (Cisco have a white paper on UCS with ESX and recommend this method)
My Preference is a bit of both, I like to use seperate vNICs for Management and vMotion as its very easy to define QoS to a seperate vNIC.
I use a single vNIC on a seperate vSwitch with a guarentee of 1Gbs for vMotion (I enable fabric failover on this vNIC this means that vMotion traffic is always locally switched within the Fabric interconnect)
I use 2 x vNICs for Management on a seperate vSwitch, As I have had issues in the past of locking myself out of the Management of my ESX sever by making config errors on the N1kv. (1 fabric A one Fabric B and Team them) as ESXi complains if it thinks you have no redundantcy for your management links, and while these messages can be suppressed I just “Humour” ESX with 2 x vNICs.
Then I have a Teamed pair of vNICs (1 Fab A and 1 Fab B) as the uplinks for my DvS (Usually Nexus 1000v, especially now the essentials bundle is free).
I wrote a alot more about this in a previous response to a question by GS, so may have a look through all the Q&A above and have a read.
Regards
Colin.
Hello Colin,
I keep getting the following error when configuring the boot from SAN option on a blade.
Affected Object: sys/chassis-1/blade-2/fabric-A/path-1/vc-875
Description: ether VIF 1 / 2 A-875 down, reason: Bound Physical Interface Down.
ID: 141549
Code: F0283
Original Severity: Major
I guess this is because of some configuration error on the MDS switch after zoning and masking. Please guide me on this. Let me know any inputs you would need to proceed further to explain.
Also what is vc-875 in this message.
Regards
Dhruva
Hello Colin,
I have a question regarding the SAN supported configuration on the UCS. We have a need to create Hyper-V Virtual Fibre Channel (http://technet.microsoft.com/en-us/library/hh831413.aspx) so guest mssql server could have a direct link to storage to share a cluster disk. We already have directly connected storage (UCSM version 2.1 running) connected to FIs in FC switching mode. I see that “feature npiv” is running but when we try to create a virtual san switch inside HyperV host we get an error that hba firmware does not support this feature. Is this supported on the UCS system. Mezzanine cards are VIC1240.
Thanks in advance
Best Regards,
Adi
Hi Adri,
From version 2.1.2 and up this should be supported. It was intended for version 2.1.1 but was removed last minute. 2.1.2. is scheduldes for March 2013 if i’m correct.
Kind regards,
Peter
Thats for picking that one up Peter!
Regards
Colin
Thank you
Regards,
Adi
Hello
I am confused over how much bandwidth each blade has and how much bandwidth go out on the FIs. I have 2, 10GB links per iom on each chassis. So that makes it 40GB? Also I have B200 M2 servers with the 1280 vic card. how much total bandwidth does each blade get then?
Also, after installing esxi, I see that each vnic has 40000. Where is the 40GB coming from?
And
Do you see any advantage of going with less or more vnics on esxi networking?
since I think the maximum vnics is 256.
should I go with something like this
2 vnics for mgmt
2 vnics for vmotion
2 vnics for vm data
2 vnics for iscsi
2 vnics for FT
2 vnics for MSCS clustering
or
2 vnics for mgmt and vmotion (use vlan tagging on port groups)
2 vnics for vmdata
2 vnics for iscsi
Is 1 vnic of 40GB and 8 vnics of 40GB each still going to be the same since any vnic traffic is going through that 1280vic of 40GB max?
kinda confused
thanks
Hi Tony
If you have a B200M2 with a VIC 1280 then each blade will have a potential of 80Gb (40Gb Fabric A and 40Gb Fabric B)
But you also need to consider your IO Module as there are a differing number of traces to each blade slot depending on the model.
So giving your setup a B200 M2 with a VIC 1280
with a 2104XP IO Module (which has 1 x 10Gb trace per blade slot will give you 20Gb total to your blade (10Gb A and 10Gb B)
If you use a 2204XP you’ll get double as it has 2 x 10Gb traces per blade
And if you use the 2208XP you will get to use the full bandwidth of your VIC1280 (40Gb Fabric A and 40Gb Fabric B) as it has 4 x 10Gb Ports per blade which marry up with all 4 Ports on the VIC1280 giving you your 80Gb total per blade total.
I get asked different bandwidth combinations allot so think my next post will be all the different combinations and what bandwidth you get.
Although Cisco do a great job, covering all the different permutations for the B200M3 in the below paper in Network Connectivity section
Click to access B200M3_SpecSheet.pdf
You also mention you have 2 x 10Gb connections from each IOM, which is obviously shared between all of your blades in that chassis. so you just have to work out your contention ratios i.e if you have 8 blades each with 40Gb of I/O per fabric (320Gb) with your 2 links you will have a 16:1 maximum contention ratio. Now that assumes that all of your servers are running at full line rate at the same time (Never gonna happen) I just suggest you monitor your IOM to FI links and ensure they are not a bottle neck for you.
You should also consider your FI to Upstream LAN / SAN switches and work out your full end to end contention rates.
Example below. (I try and keep full end to end contention rate under 15:1)
I have covered “Best Practice” for how many vNICs to create on an ESX Host in this QA section a couple to times
see the question from Dhruva above (December 16, 2012 at 10:49 am) or GS Khalsa August 9, 2012 at 5:49 pm.
And you are right aggregated bandwidth is not a valid reason for creating multiple vNICs (unless you map them to different fabrics and load balance) the main reason for creating separate vNICs is to define different QoS or Policies per vNIC as well as increase the separation of traffic VNTAG rather VLAN TAGs (Port Group separation)
Hope that clarifies things for you.
Regards
Colin
Thank you for your response. Can you explain how you came about to those ratios 16:1 etc..
I do have 2208 XP IOMs on the chassis.
From the FI to the nexus 7k, its 4 links per FI.
FRom IOM to FI its 2 links
Thanks
Hi Tony
Ratios in diagram:
8x Blades with VIC1280 used with 2208XP = (8 x 40Gb) = 320Gb per fabric
2 x Links from IO Module to FI = 20Gb
This gives you a 16:1 Ratio or contention rate between the chassis and the FI.
The Contention Ratio just between the FI and the upsteam LAN is worked out by dividing your downlinks by your uplinks. Normally you would have multiple chassis, however for simplicity I have only shown and calculated based on a single chassis hense the inverse ratio. There are 2 Downlinks to the chassis and 6 uplinks to the LAN (1 downlink for every 3 Uplinks) Hense 1:3
But as mentioned in the previous answer you need to consider your full end to end contention ratios i.e server to core. which is where the last contention ratio of 5.3:1 comes in.
Total potential Bandwidth south of FI = 320Gb in this case, divided by the Bandwidth between the FI and the LAN, in this case 60Gb so 320/60 = 5.3
But as I’m sure you know, the likleyhood of all servers pushing line rate 40Gb at the same time is not a likley scenario, added to the fact that not all traffic will be North/South (A good design will try and keep alot of the East/West Layer 2 traffic like vMotion and between servers within the vSwitch / Nexus 1000v and withinn the Fabric Interconnect.
But still having a diagram like the above in your design not only shows you have considered this but can also sometimes blatently point out a potential bottle neck.
Regards
Colin
So to be super clear in regards to multiple vNICs… Can you theoretically provision vNIC0 on Fabric A and vNIC1 on Fabric B (B200M3/2208/VIC1280/6200/4 or 8 links per fex) and be able to take advantage of the full 80Gb per blade or will you need to create more vNICs. Also do you need to port channel your FEX links to to the FIs? I hope this question makes sense.
Hi Frank
Yes with the kit you list you will get up to 80Gb per blade. You will definatley need to port-channel your FEX to FI links otherwise your blades bandwidth would be limited by the single 10Gb link they would be pinned to.
Regards Colin
Hi Colin,
Thanks for being a great resource! My question seems simple… (maybe not)
I have a UCS currently configured to connect to my access switches (4506’s) over two 10 gig connections to move all my traffic back to the core. I’m trying to connect direct to the core (3750x stack) with 2 new 10g uplinks. Uplinks seem to be functional as the 6120’s sees the 3750x’s and vice versa. I’ve set a unused vlan on the new uplinks, and it seems fine. The tricky part. When I add the unused vlan to the trunk vnic, it drops traffic over the old uplink for existing vlans and does not appear to move it over the new uplink. If I add the unused vlan to it’s own vnic, and put it on a host, it works fine, over the new link. Shouldn’t I be able to move vlans from uplink to uplink assuming the vlan is available on the uplink? Am I missing an obvious way to do this with minimum downtime?
Jerry
Hi Jerry
Think I understand what you are trying to do and you can do it, You must ensure you are using at least UCSM version 2.0 and ensure that within UCSM you map your correct VLANs to the correct uplinks.
If your links between the 4506’s and the 3750 Core are Layer 3 then that will be causing the isssues as you require L2 Adancency if you are using the SAME VLAN Id’s on the UCS FI’s , less of an issue if you are trunking all the required VLANs between your 4506’s and your Core 3750’s.
If your links are L3 then you will have to take the VLANs off the uplink to the 4506’s as you move them to the uplinks up to the 3750 Core.
Regards
Colin
Colin
Also can you explain this
>>And if you use the 2208XP you will get to use the full bandwidth of your VIC1280 (40Gb Fabric >>A and 40Gb Fabric B) as it has 4 x 10Gb Ports per blade which marry up with all 4 Ports on the >>VIC1280 giving you your 80Gb total per blade total.
I only have 2 physical links (10GB Each?) on each 2208XP IOM to the FI, where is the 40GB coming from?
So the VIC 1280 is 80GB max (40GB FAb A) (40GB FAB B). But how much I get going to the FI depends on how many ports I use from the IOM to the FI right?
so its 40GB going from the 1280VIC to the IOM and then to the FI? HOw many physical links from the IOM to the FI will I get 40GB? I got 8 physical ports on the 2208 XP but 2 are used only.
The IOM has 2 sides to it the Network Interfaces (NIFs) and the Host Interfaces (HIFs) The 2208XP is just a Nexus 2232 in a different form factor (If your are familiar with the the Nexus Portfolio)
This means it has 8 Uplinks to the Controlling Bridge (The Fabric Interconnect in our case) and 32 Downlinks to the servers (4 x 10Gb Ports to each of the 8 Server slots)
The VIC1280 has 4 x 10Gb Traces per Fabric, Hence with a VIC1280 the 4 x 10Gb Traces all match up to the 4 x 10Gb HIFs on the 2208XP Giving you your 40Gb per server per fabric.
As you rightly point out you have 2 x 10Gb Links between your IOM and your FI (Shared by all blades) so this will obviuosly be the limiting factor. Assuming you are running your IOM to FI links in portchannel mode any server could push 20Gb of I/O but has the potential to run at 40Gb if you just added 2 more IOM – FI Links.
Hope that clears that up for you.
Regards
Colin
Hi Guru,
I am new to ucs. I have given a task to build a new server in UCS blade. How to manage a server which is in UCS blade? (Like ILO, DRAC) IP, USername, password has been provided to me. I donno how to start. Can you please help me in this?
Hi Thajj
There are numerous ways to KVM onto a UCS Blade or Service Profile (The logical server that can move between blades)
Each Cisco UCS Blade has a Cisco Integrated Management Controller (CIMC) into which out of band KVM connections can be made, and virtual media mounted and installed etc..
The easiest way is just web browse to the Fabric Interconnect cluster IP address and click KVM Launcher, Login with the details you have been given, then just select the Service Profile name you want to KVM into. All the various methods are futher explained in this link.
Merry Christmas.
Regards
Colin
Thank you very much Colin
Hi All,
Happy Holidays. I have started my new year already 🙂 early.
I have been lately started working with UCS and it lot to learn. I have a question/clarity that I am still trying to figure out what it actually means.
Can someone explain me what is the actual difference between a Service Profile(creating one) and a Service Profile Template (creating one). I basically understand that if we have templates we can re-use them to create different Service Profiles. But If I am starting from zero config, then I create pools, then policies and then after that should I create a “Service Profile” or a “Service Profile Template”.
Thanks in advance for your help.
Warm Regards
Sandeep
Hi Sandeep
Welcome to the world of Cisco UCS, I’ll think you’ll really enjoy it.
Service Profile Templates are really useful and can be hugely powerful and I use them in most designs and installations.
The first thing to decide is whether you want to use an Initial Template or an Updating Template.
SP’s created from an Initial Template are “on their own” once created and are individually editable.
SP’s created from an Updating Template on the other hand remain bound to the template and cannot be edited after creation (Unless they are unbound from the template)
I mentioned Templates can be hugely powerful; imagine updating the firmware of all the servers in your entire estate in a single action or adding a Ethernet adapter to all of your ESXi Servers in a couple of clicks. Such things are possible with Updating Templates.
And with UCSM 2.1 all service profiles created from Templates can now be freely renamed (I usually just call them the same as the hostname of the server)
I have attached a link to the UCSM 2.1 Config Guide, which covers Templates as well as all other aspects of Cisco UCS Configuration.
Regards
Colin
Hi Colin,
Thank you for the response. I actually had the config guide, just was little lazy to ponder through the guide 😉
Will study through it and will fiddle around the UCSPE to get some initial hands-on before a real lab environment.
Appreciate all your posts in this blog, it is very informative.
I am really enjoying Cisco UCS, my long term plan is towards CCIE DC. Lots of learning and I am thrilled. Wanted to know if I this blog also includes Nexus topics as well.
Cheers,
Sandeep
Hi Sandeep
Yes I tend to deal with Nexus as far as Connectivity to UCS Goes.
But I’ve been thinking of having a Catergory dedicated to CCIE Data Center Preperation, that would contain broader Nexus info as well as UCS, MDS, ACE, N1kV
But then again Tony Bourke already has a great section on it at Datacenter Overlords.
Regards
Colin
Hi Colin,
Thank you. That sounds great and Datacenter Overloads is a wonderful blog.
As of now trying to figure out things on UCSPE which seems to be very effective for initial learning and hands-on on the UCS manager.
I have UCSPE as a VM on an ESX server and load it across the network from firefox, and it works well. Was wondering if there is a limit for the number of users it can handle. I can launch the UCS manager and key in any combination of user and password and it takes me in. But not sure is there a limit of number of users into it, as all the users are considered as admin (according to release notes http://developer.cisco.com/documents/2048839/ba79fb92-a536-4de6-855b-65dcf49dbfc0)
Warm Regards,
Sandeep.
Hi Colin,
Happy Christmas and Happy New Year,
Can you help me for solving this warning message?
I have this warnings at all blade servers.
Code:F0283
Description:fc VIF 1 / 2 B-958 down, reason: Vlan not FCoE Enabled.
I’m using FC swicthing mode, and only have VSAN default. Default zoning enabled and in the properties FCoE vlan ID set to 4048. The SAN storage directly connect to FI use FCoE storage ports. This warning never appear before. Can you explain to me and how to solve this warning?
Thank you so much before
Regards,
Jacky
Hi Jacky
When you say this “Warning has never appeared before” I am guessing you have just done an upgrade or somthing and now this message is showing up.
VLAN 4048 is used as the default FCoE VLAN from UCSM 2.0 and as such is “reserved” I have seen messages appear for FCoE VLANs after un upgrade (Commonly around overlapping VSAN and VLAN ID’s, which were permitted in UCSM 1.x but give warning messages in UCSM 2.0 and up)
The default FCoE VLAN varies according to the type of VSAN and whether Cisco UCS is a fresh installation or an upgrade, as follows:
After an upgrade to Cisco UCS, release 2.0: The FCoE storage port native VLAN uses VLAN 4048 by default. If the default FCoE VSAN was set to use VLAN 1 before the upgrade, you must change it to a VLAN ID that is not used or reserved. For example, consider changing the default to 4049 if that VLAN ID is not in use.
After a fresh install of Cisco UCS, release 2.0: The FCoE VLAN for the default VSAN uses VLAN 4048 by default. The FCoE storage port native VLAN uses VLAN 4049.
I usually prefix all my VSAN ID’s with 30 for the FCoE VLAN ID. i.e. if I use VSAN 10 I use VLAN 3010 as the FCoE VLAN etc..
I would suggest to try and use a different VLAN ID for your FCoE VLAN 4049 for example, and see if that clears the message.
This should be non disruptive change ( I have done this on the fly many times) but as ever if you want to be 100% sure and if this is a Prodution Environment best shut down any hosts using the VSAN or at least confirm you have active paths via the other FI.
Regards
Colin
Under the equipment policy, can you help me understand the chassis discovery policy and the link grouping preference? Does the “link” have to match the exact number of links from each chassis to fabric interconnect, or can it be less (since it’s only for discovery)? In addition, what benefits does selecting “port channel” give me?
Thanks!
Tom
Hi Tom
The Chassis discovery policy allows you to set a minimum number of links a chassis must have (per fabric) in order to be discovered, just a way of enforcing a standard within your org. By default the Chassis Discovery Policy is set to 1 link, which means a chassis with at least 1 link will be discovered. Then a Chassis Acknowledgment is required to activate any additional links.
I generally leave it at 1 as the Chassis view shows you a nice diagram of the number of links anyway. But the option is there if you want to enforce a certain number of links in your setup.
With 1.x Code if you tried adding a Chassis with a lower number of links than the policy specified, the Chassis would still be discovered but UCSM would alert with a message saying the Chassis did not conform to the Policy. From UCSM version 2.x Chassis with a lower link count than the policy are no longer even discovered.
Benefits of Port-Channel between IOM and FI
In version UCSM 2.x Code the option was introduced to be able to port-channel the IOM to FI links. This is to take advange of the additional bandwidth available on the Gen 2 VIC 1240’s and VIC 1280’s.
If you did not use port-channel mode and instead used the default (Discrete Pinning) Then each blade slot would be pinned to a particular IOM cable thus no server having access to more than a single 10Gb cable, which for a 40Gb per Fabric Adapter is an immediate bottle kneck. (you obviously need to use the 2208XP IOM to get the Max bandwidth)
I always port-channel these days, the only reason not too would be if you wanted a very deterministic ammount of bandwidth in the event of a link failure, But even then I’m clutching at straws to advise it.
I have gone into more detail and provided diagrams in a previous question on this page so well worth having a look back through previous questions.
Hope that clears things up for you.
Regards
Colin
Hi Colin,
I have a 40Gb uplink port channel (2 port channels with 2x10Gb links). In terms of capacity management , do you think this current setup of ours would suffice in the long run if we currently have more than 5 chassis with around 3 servers each which have 4 nics (Cisco UCS M81KR)? Or would adding links to let’s say 80Gb uplink port channel would do?
Thanks in advance.
Hi Marie
The answer to your question I’m affraid is “It Depends”
There are numerous elements envolved amount of traffic from blades, and how much of that traffic will be North/South or East/West but inter Fabric or VLAN (Basically the ammount of traffic that needs to go via the Uplink ports).
I answered a question Submitted on 2012/12/24 at 10:26 am In reply to Tony, I which I show you how to work out your end to end contention ratios so have a look at that post.
In real terms I think 40Gb from each FI to your LAN should be ample for you, but if you want to proove it you can monitor your uplinks or even configure a threshold alert on your port-channels if they reach a certain level.
Vallard Benincosa talks you through how to set this up here and here
Regards
Colin
hi
I have 2 brocade dcx switches that is onnected to my 2 FIs. dcx1 is connected to FI-A, dcx2 is connected to FI-B.
Then I have a servicce profile template that has 2 vhbas. one is on fabric A and one is on fabB.
But now some servers when they are doing a initial boot from san, the wwpns for fabric A is showing up on the dcx2 switch and vice versa. It does not happen for every server. All the servers are using the same template.
I have vsanA for fabric A and vsanB for fabric B. So the wwpns for B should not be showing up on the other brocade switch.
any ideas?
thanks
Hi Tony
So as I am sure you know you must have a cross in your fabrics somewhere. If all your servers are using the same template and thus should all have consistent VSAN and Fabric assignments this should not be the cause.
As this is only happening for a subset of your servers, it sounds to me that you must likely have a link from FIA to DCX2 and thus any servers that have vHBA’s pinned to that link are ending up on the wrong fabric. So suggest double checking your patching.
To be sure ssh into the FI’s directly, connect NXOS, and check whether your WWPNs are in the flogi database of your FI’s “sh NPV flogi database” from NXOS mode.
If you see all the A’s on FI A and all the B’s on FI B then you know the at the config south of the FI’s is fine, and that you have a cross connection from the fc uplinks on FI A to dcx2 somewhere. Have a look which F-Port on dcx2 the WWPNs from Fabric A are being learned on and trace back and ensure it goes back to FI B.
If you are still seeing WWPNs from Fabric A’s in the NPV flogi database of FI B then you know the issue IS south of the FI most likely some vHBA’s are bound to the wrong Fabric (although unlikely if all your SP’s are referencing the same template, but worth checking each SP to be sure.
Anyway follow the above and you should rapidly find what’s causing your issue.
Regards
Colin
Thank you Colin. You are right. There was a problem with one of the FI links going to the second brocade. That explains why I was seeing wwpn B pool addresses on the 1st brocade switch.
What is the vnic/vhba placement policy for? I onl have B200 m2 half height blades with the vic 1280. So its single mezzanine card. Does it make an sense to use this policy on my blades?
thanks
Hi Tony
I covered a bit on Placement Policies in my response to Fred in the question posted October 13, 2012 at 12:37 pm so worth having a quick read of that.
But in short you are correct, in your situation having only a single Mez adapter you will only have vCon1 available to you.
A vCon as listed in the placement policy represents a Mezzanine card so if you have a full width blade with 2 Mez cards you could define which vNICs/vHBAs are placed on which Mez by assigning some to vCon1 and some to vCon2. You may see higher vCon numbers as an intergrated C Series can take more than 2 Cards.
The only time you may want to define a placement policy for a single Mez Blade is when using dynamic vNICs with VMFEX and you want to ensure they appear to the blade higher up the PCI Bus than the Static vNICs and vHBA’s. Or of course if you want your vNICs / vHBAs in a user defined specific order on your single Mez adapter.
Regards
Colin
hi
I did see one vcon1 but under the vcon1, I see vcon1-4. why is that?
Hi Tony
As mentioned all vCons in your case will be assigned to your only Mez Card (vCon1). The system is intelligent enough to know that even if you did have a placement policy specifing multiple vCons (Mez Adapters) it will only ever place them on vCons you actually have. vCon1 in your case.
Hope that makes sense.
Colin
Hi there,
I have seen the recommendation from cisco to have different vsans to each path on each Fabric interconnect. What is the effect of having the same vsan ( like the default vsan 1 ) for the whole cluster?
Hi Noorani
Yes that is correct, there is of course nothing stopping you using the default VSAN1 on both Fabrics, however it is a long standing best practice amoungst SAN administrators not to use VSAN 1 for (production traffic at least) on their SAN swicthes (Just like the LAN best practice not to use VLAN1).
But using the default VSANs certainly works, I use them when connecting to upstream SAN switches that do not understand VSANs (Brocade for example)
But as you say best practice is to use VSANs other than VSAN1 and have a different VSAN on both Fabrics, this just makes administration and troubleshooting easier on many levels.
Sometimes the VSAN ID’s will be predetermined by the Storage Admin and they will just tell you them, but if not or this is a new installation always go for user defined unique VSANs on MDS and Nexus Fabrics.
Regards
Colin
Thanks Colin
Hi Colin
When connecting UCS to two brocade switches is it best to :
a – use the default vsan
b – create two different vsans one on each fabric with different vsans and fcoe id’s and assume brocade will ignore/strip the vsan.
Thanks
Hi Mike
When uplinking to SAN switches that have no concept of VSANs I generally take your option A and just use the default VSAN for each Fabric in UCSM.
Regards
Colin
hi colin,
I got a situation where 1 host will see all 8 paths on the storage array, but another host will see only 4 paths to the same storage array. Both hosts are using the same service profile. Have you come across this before?
thanks
Hi Tony
I assume you mean the Service Profiles are created from the same Service Profile Template (and as such have all the same HBA settings, bar the unique WWPN’s)
Your issue sounds to me most likley to be a Zoning issue on the SAN switches.
I would have a look in your flogi database and active zoneset and ensure you see all WWPNs from the host that can only see 4 paths and that the Zones are correct and have the correct WWPN’s or alias in with no typo’s.
You could also check the initiators (WWPNs) are registered and active from the Array side.
Regards
Colin
Hi Colin,
I have 2 questions.
– Do you know how to clear power failure alarm on a chassis? We have 2 different power source to our equipments and for testing purposes we turned off one source to analyse the reaction. Then we brought it back online but UCS is stuck with the power failure error on the chassis. I havent found a way to clear it.
– Also another question concerning power, i have read that if you had 2 power sources like most datacenters have, its recommended to have the redundancy mode from N+1 to Grid mode? You have any experience/recommendation for this?
Assuming the power has indeed been restored your event should clear, if not you could try manually clearing the System Event Log (SEL)
Go to the system event log in the SEL Logs tab, click Clear.
Re your second question.
Power configurations in Cisco UCS can be a complex topic in its own right once you get into the details and topics like running in High Density Mode, but if you stick to the below “rules” you will be fine.
in UCS Terms treat N as 2 so N+1 would equal 3
This means you have one more power supply than you need to run the chassis and can stand the loss of a single PSU.
As you point out most Data Centres have redundant power feeds (Grids) so if you had 3 power supplies running in N+1 you would have to connect 2 power supplies to Grid A and only 1 to Grid B. Now while you are covered for a single power supply failure you are NOT covered for a failure of Grid A, as that would take out two power supplies and leave you with only one. And remember you need N to run the box with no redundancy and as we know N=2
So to run in fully Grid redundant mode, you would need 4 Power supplies and Grid Redundantcy selected, that way you can suffer the loss of any 2 power supplies or any Grid.
If you have 4 power supplies and you leave the tick box as N+1 your chassis will automatically run in whats called High Density Mode, which means it will actually be using 3 power supplies allowing a higher power draw to each blade slot (600W rather than 550W in standard mode) But in my experience I have never managed to get a Blade tio run hot enough to require running in HDM Mode (You would need to Max the Memory, Use the Highest CPU and then MAX all of this out with the workload on the server)
In the above scenario N becomes 3 so if you were to have 2 power supplies fail you would experience an outage.
In real terms if your chassis is running production workloads always go for 4 Power supplies and run with Grid Redundancy.
Regards
Colin
Hi UCS guru
In you reply to tarun
2) If a vNIC was statically pinned to an uplink and that uplink failed then that vNIC would NOT be dynamically pinned to another uplink, When the uplink target on Fabric Interconnect A goes down, the corresponding failover mechanism of the vNIC goes into effect, and traffic is redirected to the target port on Fabric Interconnect B.
Is this the same behavior for vHBA?
Will the vHBA failback to the fc-uplink even if it was not statically pinned?
example:
fcuplink1 – vhba1,vhba3
fcuplink2 – vhba2,vhba4
fcuplink1 – offline
fcuplink2 – vhba1,vhba2,vhba3,vhba4
what happens if the fcuplink1 comes back online.
Hi Ashok
Great Question
When fcuplink 1 comes back up the vhba’s would not automatically re-pin back, but fcuplink1 again becomes available as an uplink for new connections or if a server was rebooted or an vHBA flapped etc..
If SAN Pin groups were used my feeling is it would fail back if the pinned target becomes available again (But I’ll Lab it on Monday, and if there is any different result I’ll update this response)
Bear in mind whenever a vHBA is re-pinned this will disrupt traffic on that path as the FI needs to send a flogi on the new port.
Thats why its a good practice to use SAN Port-Channels. (If you have Nexus or MDS SAN swicthes) as the Server WWPNs on the SAN switches are associated to the port-channel and not the fc interface so the FI would not need to issue another flogi to update the updtream SAN switch.
Regards
Colin
Hi ,
I’m using two Fabric Interconnects (6296UP) with 5108 Blade Chassis.One of Fabric Interconnects is broken.And Cisco sent to new one.But I couldn’t change procedure on Internet.How can I change this ?
Hi Indat
I assume you are now just running on the single FI, in which case the addition of the new FI is the same as when you first installed the solution.
Connect your new FI into the infrastructure power it on, an install wizard will ask you if you want to set up the new FI, say “Yes” then choose to join an existing cluster, enter your admin password when prompted, and Fabric A/B and IP infomation when prompted and the new FI will import the config from your working one and rejoin the cluster.
Regards
Colin
I have question, there is one Cisco 5108 UCS chassis, populated with B220 UCS blades, from slot 1 to 4, I want to install B440 Blade to the same chassis, what is recommened proceduree….
Hi Aamir
No problem at all you can put your B440 in slots 5&6 or 7&8
You just need to take the guide bar out from between whichever of the above slots you use. (At the front of the guide bar there’s 2 small tabs you push one down and one up and then the bar just slides out).
Regards
Colin
Thanks Guru,
One More Question, about WWN Pool, How can we edit WWN Pool in Production chassis, Will it effect the already allocated WWNs, WWPNs to the blades, already in production…………… Or just can add new Pool with New block size and mac:00:00:00 change.
Thanks in Advance!!
Aamir
Hi Muhammad
Yes you can extend the range of your existing WWPN pool with no impact to your already assigned WWPN’s
Obviously the extended addresses should be unique in your environment and not overlap with other pools if you have any.
Colin
Hi Colin – I have a low latency app and my DBA is concerned about traffic going between two baremetal blades (no hypervisor) needs to go all the way from Blade#1 to FI to then come back down Blade#2 (they are on the same chassis). I always understood that the FEX is not a local switch but if depending the way you do mac-pinning you can potentially provide local-switching at the FEX level. I am sure this is not best practices but is this feasible?
Hi Andre
This is a concern I hear occasionally, and you are right the FEX is not a switch and will not provide any local switching.
But don’t think of the FEX as a switch it mereley extends the ports of the Fabric Interconnect and think of the cables between the FEX and FI as the “Backplane” of the switch. This has many benefits in reducing cabling and management points.
The Cisco 6200 FI’s provide the same low latentcy hardware switching as in the Nexus 5500 (2us port to port) so is well suited to low latentcy workloads.
You will also want to ensure that all of your East/West low latentcy traffic is mapped to the same FI and as such can be locally switched inside the FI, you can do this by having 1 vNIC per baremetal blade and mapping it to a single fabric and protecting it with fabric failover.
(The FI can localy switch L2 within the same fabric)
Hope this addresses the concerns of your DBA.
Hi Colin,
Great site! I’m starting to look into UCS and I have a question about mixing virtual and bare metal workloads in a UCS environment. I would be looking to replace an HP c7000 infrastructure with UCS. We currently have a mix of ESX boxes (which seem like they would make perfect sense in UCS), and mix of dedicated boxes for processor intensive work. Would these different workloads coexist well inside a UCS environment? In one of Joe Onisick’s posts (http://www.definethecloud.net/why-cisco-ucs-is-my-a-game-server-architecture) he mentions true workload portability as one of the game changing features of UCS. Does this mean a bare metal server can essentially “drag-and-drop” between physical UCS blades?
Thanks,
Brandon
Hi Brandon
Thanks for the question.
As we all know not all Workloads are suited to a Virtual Envrinoment, this can be for any number of reasons; Vendor Support, licencing, Performance, Security, Direct access to Fibre Channel devices like Tape Libraries, as well as Politics to name a few.
Also not all workloads are suited to a Blade Environment, and not a week goes by that I don’t have a “Blade Vs Rackmount” conversation with someone.
And this is really one of the many strengths of Cisco UCS.
Being able to mix Blades and Rack Mounts within the same cohesive system without adding management points, and even move workloads between them, Now that certainly is taking flexability to a whole new level.
This makes upgrading a dream or even temporarily “flexing” a workload up or down as demand dictates, for example you could move your payroll app to a Quad Socket Rackmount for the week that it is in most demand, and then move it back to an efficient performance 2 socket Blade for the rest of the month when its less utilised.
The keyword here is choice, Why choose if you don’t have too? and to quote Killian from the Running Man! “If you can’t decide don’t decide”
To give you a real world Enterprise example, I recently did a UCS design for a financial institution here in the UK, which was to migrate their entire Enterprise onto Cisco UCS, and just like your requirement this was from HP C7000’s and Stand-a-lone Rack Servers.
After 2 months of discovering and analysing the clients environment the below Cisco UCS kit was recommended and has just been installed.
6 x Cisco UCS Pods (each Pod being in a different security zone)
131 x B230M2 20C 256GB RAM (for ESXi Clusters)
99 x B22M3 6C 32GB RAM (For Bare Metal Windows and RHEL)
15 x C200M2 (For Bare Metal workloads with older O/S like RHEL 4.9)
15 x C220M3 (For Bare Metal workloads with O/S’s supported on M3 Blades)
So as you can see there is a real mix here, with each platform “flavour” suited and “pooled” to a particular use case.
So yes you can essentailly “Drag and Drop” workloads between Cisco UCS Blades/RackMounts, in UCS terms this is called a “Disassociation” from one bit of tin and a “Reassociation” to another bit of tin. The server in Cisco UCS terms being the “Service Profile” which is just a logical entity that can be freely moved around.
In order to get the most out of this “Statelessness” definatley look to Boot from SAN or iSCSI as that removes any dependantcy that a workload might have on a particular bit of tin, and with Cisco UCS configuring SAN boot for your whole environment takes about 10mins with the creation of a System wide boot policy.
Good luck in your journey and UCSguru.com is always here to give you a helping hand along the way.
Regards
Colin
Hi Colin !!!
I like your blog !!, I’m really new in UCS, so I want to know how to start in this theme, any link or tutorial is very welcome,, so please help me.
Thanks a lot
Thanks
I have just mailed you across a copy of my UnOfficial “UCS for Dummies” 🙂 which gives you a good intro
I think you are going to enjoy your Cisco UCS Journey.
Regards
Colin
Can I get this “UCS for Dummies?” Been reading all these posts getting ready to install our first UCS system on Monday. Need all the help I can get. Thanks in advance.
Hi Geron
Whats your E-mail and I’ll send you a “UCS Starter Pack”
Colin
Great blog!
Can you explain fabric failover for me? On all my Windows hosts, I have configured just one NIC with fabric failover enabled. If I lose both uplinks on Fabric Interconnect A, will my NIC failover to Fabric Interconnect B? Or does failover only happen when a Fabric Interconnect completely dies?
In addition, my ESXi host are configured for 6 nics. 2 for mgmt, 2 for vmotion and 2 for VM traffic. vnic0 goes to FI-A, vnic1 goes to FI-B and so on with no fabric failover. Since ESXi will handle NIC failover in this scenerio, am I correct in thinking we should keep fabric failover for these servers disabled? Something just seems wrong with enabling NIC failover on multiple levels.
Thanks in advance!
-Sharishma
Hi Sharishma
Thanks for the great question and certainly one that comes up alot.
Re Fabric Failover:
When ever you tick the fabric failover box for a vNIC a virtual Ethernet port (vETH) is created on BOTH fabric interconnects with a different identifyer (You can see this by looking under the VIF Paths tab of your Service Profile)
Then if the primary Fabric fails, the FI will do a subsecond failover to the other fabric (the standby virtual circuit is already established and just waiting to go active) The FI containing the failover circuit will then issue a GARP containing all MAC addresses that are behind the vNIC, up the new circuit to inform the upstream switches.
Now what can cause the failover? basically the loss of the primary FI as you say, or the loss of all FI uplinks that a vNIC could be pinned to.
Generally UCS best practice really minimises the scenarios that can initiate a Fabric Failover i.e. the use of Port-Channels combined with Multi-chassis Etherchannel (MEC) technologies like vPC and VSS.
Re: Fabric Failover or Redundantcy via Teaming
As a rule I use a single vNIC with fabric failover enabled in any situation where teaming or loadbalancing is not an option or a requirement or if I want to confine traffic within a certain fabric for low latentcy L2 swicthing within the FI (vMotion Traffic for example)
But for uplinks to vSwitches and DvS’s etc.. I always go for 1 Fabric A and one Fabric B and let the Hypervisor or Nexus 1000v handle the redundantcy.
I do not enable fabric failover on these already redundant vNICs as I have seen that mask issues (i.e if there is a failure I want to know about it)
Hope that clears things up for you.
Regards
Colin
Hi Colin,
Great Blog. I have a strange issue with PVLans. I have ESXi 5.1 configured on the UCS Blades. I have dVSwitch setup with multiple VLANs. We are trying to configure Private VLAN ( PVLAN ) on the dVSwitch. The steps to taken to create the PVLANs are as follows
1. Create the Master (vlan id 110) the Secondary PVlan (vlan id 115) in the Physical Switches.
2. We have created both Master and Secondary VLANS in the UCS as normal VLANS 3. On the Distributed vSwitch, Created the Primary VLAN id (110) and Created a secondary VLAN (115) The Type for the Secondary VLAN is Isolated.
4. Created a Port Group and the VLAN type chosen is Private VLAN and the Private VLAN Entry as Isolated (110,115).
Deployed a VM int the Port Group and we are not able to ping the Gateway. For troubleshooting purposes, Changed the VLAN Entry int the Port Group from Isolated ( 110,115) to Promiscuous ( 110,110). Then tried to ping the Default Gateway on the VM, it started Working. Went back to the Port Group settings and changed the Private VLAN Entry from Promiscusous ( 110,110) to isolated ( 110, 115). Tried to ping the gateway from the VM, the ping is still working. But after few hours, the ping stops working. If we go back to the Port Group settings and change the Private VLAN entry from Isolated to Promiscuous, the ping start to work. But only for few hours. Do i need to create Private VLANs in the UCS before creating in the VMware. I am thinking this is a bug in the vmware. the symptom are same either in regular dvSwitch or when using nexus 1000v.
Any help is appreciated.
thanks
-Vijay
Hi Vijay
I usually use one or other i.e either use PVLANs in the UCS or in the DvS (Unless of course you have a combination of physical and virtual workloads that need to share the Private VLANs)
I would suggest if you are only using Virtual machines in your private VLANs that you pass all VLANs through the UCS as classic VLANs and then do all the PVLAN config on the N1kv which has more PVLAN functionality like Community PVLANs etc..
Failing that if you are still experiencing issues then raise a Service Request.
Regards
Colin
hi Collin, wow amazing your blog and i love it. anyway i’m newbie for with UCS can you help me design with this material :
Options A :
– UCS 6296UP = 2
– 10GBASE-SR SFP Module = 4
– 10GBASE-CU SFP+ Cable 3 Meter = 12
– 8 Gbps Fibre Channel SW SFP+, LC = 8
– UCS 5108 Chassis = 2
– UCS 2208XP I/O Module = 4
– UCS B200 M3 With 2650 8x16GB Dual VIC = 4
– UCS VIC 1280 dual 40GB = 4
– UCS VIC 1240 Modular LOM = 4
Options B :
– UCS 6248UP = 2
– 10GBASE-SR SFP Module = 4
– 10GBASE-CU SFP+ Cable 3 Meter = 8
– 8 Gbps Fibre Channel SW SFP+, LC = 12
– UCS 5108 Chassis = 1
– UCS 2208XP I/O Module = 2
– UCS B200 M3 With 2650 8x8GB Dual VIC = 4
– UCS VIC 1280 dual 40GB = 4
– UCS VIC 1240 Modular LOM = 4
thank you very much if you helping me, because i dont know about UCS and how to design that material
Hi Pedro
Normally you would do a design before you define the Bill of Materials as one should dictate the other.
Designing to a kit list is definatley the wrong way around.
I can’t really advise as to a design with the kit you list, as there are far too many variables involved.
As a general rule, I always start with the use case and application requirements then work back to ensure everything is optimally designed for the application.
There are lots of design tips and examples in the “Ask the Guru” section of this blog so well worth having a read through as many of your questions have likly already been asked and answered.
If you have any specific questions that have not already been asked, then feel free to fire back.
All the best with your UCS journey.
Regards
Colin
Hi
I have votion vnic templates created in ucs and have set these to a mtu of 9000. however vmotion is very intermittent and failing most of the time. but when i set them back to 1500, vmotion seems to work. My upstream nexus 7ks are enabled for jumbo frames already. Is there anything else in ucs that I need to enable for vmotion to work with jumbo frames?
I also have 2 iscsi vnics that is also having issues. I suspect it has to do with the jumbo frames setting.
any ideas?
thanks
Hi Tony
I’m really glad you asked that, as it is a really common question / issue.
I can certainly see why users get a little confused, as to why when they set the MTU on a vNIC to say 9000, that they are experiencing a lot of fragmentation as the Fabric Interconnects are still sending packets with an MTU of 1500.
This is because the Fabric Interconnects at NX-OS level (under the hood) are essentially a Nexus 5500, and as you may know in NX-OS the MTU is defined on a per CoS basis. So your issue will be your vNIC is sending packets out with your defined jumbo MTU but if you have not defined a CoS Class for them, the traffic will default to the “Best Effort” class which has an MTU defined of 1500.
So all you have to do is define a QoS policy in UCS Manager and set the MTU of that Policy to 9216
My Advice would be just to change the MTU of the predefined “Gold” Class to 9216 (if 9216 supported in your environment) and then just assign Class “Gold” to your vMotion vNICs which you have already set as MTU 9000.
Proceedure as follows:
Configure the Gold Class for MTU 9216
LAN Tab > LAN Cloud > Qos System Class > General Tab
Enable the Gold Class and set the MTU to 9216
You may also want to set the “Weight” for Gold to 10%, to always reserve 1Gb of bandwith for vMotion
Create a QoS Policy
LAN Tab > LAN Policies > Create QoS Policy
Give it a name i.e. QoS_Gold_vMotion or somthing
Selecy “Gold” from the Priority drop down list.
You then can just reference this Qos Policy in your Service Profile or your vMotion vNIC Template, then hey presto you’ve configured your UCS for Jumbo Frames!
Remember to confirm your MTU is supported all the way to the Array, I usally do a PING test with a -f (Don’t Fragment) and -l 9000 (buffer size)
i.e. PING x.x.x.x -l 8900 -f if you get a reply your MTU is supported end to end, if you get a response saying “Fragmentation required but Don’t Fragment bit set” or simlilar your MTU is not supported end to end, and somthing on route is trying to fragment the packet.
Good luck
Regards
Colin
Hi Colin,
thanks for your response. Do I need to do some QoS/Cos maps on the upstream switch where the iscsi device is connected to? I heard that return packets going from the ucs server through the FI and then to the core upstream switch is tagged with the CoS/Qos value but returning back its untagged.
thanks a lot
HI Guru, please can you tell me if its posible connect two catalyst 3750 to fabric interconnect through 10 giga thanks a lot
Hi Dave
Yes absolutley no issue, you can either have a single port or better still a port-channel from each FI to the 3750 Stack, or a single link or port-channel from each FI to each 3750 if they are not stacked (but you would need a trunk link between them)
Regards
Colin
Guru!! thank you very much from Costa Rica, I learned a lot in this blog, go ahead, greetings.
Hi Guru,
Great posting and answers in your blog since the start of the year. Thanks a bunch for your answers and thanks to all who post questions as well :), my learning is going in steady pace.
While creating service profiles, vNIC templates etc and other policies and so on there are many options where in, we need to either set something or we can leave it default/not set. Wanted to know what is the difference between “default” and “not set”, do we have a document from cisco to know what are these defaults. Thank you.
Warm Regards
Sandeep
hi UCSGURU, i have 2 fabrics Cisco UCS 6140XP and a mds9000 as san, im working with vmware esxi 5.0 and i just want to enable npiv on my ucs for pass N wwn´s through this path , i open a case on cisco tac, and they says me that i need to upgrade my ucsm version from 1.4 to 2.1 to pass N wwn´s through this path or the other option is change end host mode to switch mode, but i cant do this, what do you recommends? please let me know if you do not understand me.
Hi Jose
I think you maybe confusing NPIV with NPV.
You do not enable NPIV on the UCS side, but rather on the MDS side with “feature NPIV” if using NX-OS or “NPIV enable” in SAN-OS.
The default mode of the FI is as you say End Host Mode or NPV in SAN terms, this means each UCS FI acts like a big server with multiple HBA’s and thereby multiple WWPN’s. By default your MDS F ports only expect 1 Flogi and 1WWPN behind the port and thus will only assign a single FCID. But as you have many WWPN’S and require and FCID for each of them the F port on the MDS needs to support NPIV to allow this to happen.
The first Flogi occurs as normal but subsequent Logins are changed to Fabric Discoveries (FDISCs)
There’s lots of info in the question section on this page which addresses setting this up and troubleshooting.
Good luck with it.
Re versions: All the above is supported on 1.4 but you may want to consider an upgrade anyway as there has been loads of cool features added since 1.4
Regards
Colin
Hi Guru,
Suppose there is a Cisco UCS system working wonderfully with vmware hypevisor. Can I use a 3th party blade system for vmotion and disaster recovery and load sharing purposes. What I mean is Cisco provisioned vm machines and network attributes and UCS management does provide or prevent vmotion to another non-cisco blade systems.
Thank you.
Regards,
SSC
Hi yes that’s fine just make sure you meet the usual prerequisites for vMotion I.e CPU compatibility etc.. You will likely need to configure Enhanced vMotion Compatibility (EVC)
Regards Colin
HI Guru, I can have two RAID arrays, 5 and 1 on Cisco ucs c220, if its posible, which controller i need, thanks.
Hi Dave Yes you can have a R1 and R5 using the Embedded MegaRAID controller as long as you meet the minimum disks required for each raid level. Have a read through the below doc which gives full details.
http://www.cisco.com/en/US/docs/unified_computing/ucs/c/hw/C220/install/raid.html#wp1015625
Regards Colin
Awesome blog!!
The new zoning feature in 2.1 firmware…what’s its’ signifigance? By that I mean, one of the purposes of zoning is an added layer of security…you can’t just plug something into a SAN switch, or in this case, a blade chassis and it automatically start hitting your array. Zoning creates an added layer of security where you have to specifically allow and configure access to the array. But with service profiles, this was already happening, a blade in a UCS system configured for direct attached storage couldn’t just communicate with the array, you had to first specify a service profile which then had configuration items which allowed communication to the array. What is the new zoning feature do differently besides add a couple more policies where you configure storage connectors? There doesn’t appear to be a significant difference and I was wondering if you could explain this for me.
Thomas
Thanks Thomas
The FI zoning feature is really only intended for specific use cases, i.e. No other fc SAN switches in the environment thus directly attaching fc targets to the FI’s.
In this setup I’m sure you can now see the benefit of being able to zone the FI’s to prevent inititators seeing initiators and targets from seeing other targets. Basicially being able to adhere to the best practice of Single Initiator / Single Target or at least Single initiator / Multi Target (SIZ) so more geared around aiding fabric stability and performance than security.
Regards
Colin
Thanks for the reply, Colin. I had thought, however, that initiators couldn’t see each other anyway. That, via adapter FEX, that traffic was all isolated anyway. And if I’m only plugging into one array, there is no worry about multiple targets seeing each other. What am I missing here? Are you saying this is incorrect and prior to the zoning in 2.1, all initiators and targets could see each other in direct attached scenerios?
Thomas
Hi Thomas
If multiple initiators are in the same zone or you are using the FI in Fibre Channel Switch mode with no upstream Cisco fc switch from which the FI can inherit the zone info from then there is nothing to stop the initiators seeing each other at fc level. Adapter FEX doesn’t prevent this potential communication that’s just the way fc works.
Always best practice to only have one initiator per zone.
Regards
Colin
Hi Colin,
How do you go about troubleshooting IO module down and in Fault tab it displays “link failed or not connect” and in FI Primary similar message is been display?
How do I know whether is it FI SFP, IOM or the cable connected is faulty?
Thanks.
JE
Hi Jia
“Link failed” would generally indicate an sfp or cable issue! If the IOM module is green in UCS Manager or just look at the LED on the back of it, then the IOM will be ok. Also if the IOM module was failed I would expect a critical alert to that effect.
Ensure you FI port is configured as a Server Port and check the cabling.
Regards
Colin
Hi Colin ,
My question is on UCS Central . I can add domains that is fine . When I look at the faults or events of those domains in UCS Central it says that it cannot connect to UCSM using the IP address . It almost looks like its trying to use a certificate bound to an IP rather then a name .This happens if your using the default keyring or a CA certificate keyring . Why would it be trying to connect IP rather then using DNS because during setup we specify a DNS server in UCS Central . Do I need to create certs based on IP and not Name ?
Thanks UCS Guru 🙂
Chris
Hi Chris
I personally haven’t seen this issue, every time I have setup UCS Central I have just used IP addresses to add in each UCS domain.
When I get some lab time I’ll see if I can replicate your issue. If you need this resolved ASAP then open a case with TAC.
Please update this thread if you get your issue resolved.
Regards
Colin
Question: On a 6200, when does a port consume a port license? And how do you release a port license from a port that is not in use? My system shows some ports in grace period when I have more licensed than are being consumed.
Hi Mike
Great question, port licences are required for every port on a UCS FI, but all FI’s come with several port licenses that are factory installed and shipped with the hardware.
Cisco UCS 6248 fabric interconnect—pre-installed licenses for the first twelve unified ports enabled in Cisco UCS Manager. Expansion modules come with eight licenses that can be used on the expansion module or the base module.
Cisco UCS 6296 fabric interconnect—pre-installed licenses for the first eighteen unified ports enabled in Cisco UCS Manager. Expansion modules come with eight licenses that can be used on the expansion module or the base module.
To emphasise port licences are assigned to the first ports you activate NOT to specific ports. If you have a licenced port that is unused simply disable it and that licence becomes available again. This is especially relevant to unused fc ports as they will always consume a license unless disabled.
Hope that clears things up.
Regards
Colin
Also i believe in a 6248 once a port has been designated as FC, it consumes a license independent of whether the port is actually used or not
noorani, I don’t beleive that to be correct. I had to disable some FC ports for a client running a 6296 to bring the license count back in compliance.
What i mean is that once you use the slide and designate the port to be a FC uplink, it uses a license, independent if you actually have a FC cable plugged in.
That is true, once you configure the port for FC it will consume a license but you can just disable the port to get that license back, so to speak.
I tried to do the hot swap for HDD on UCS Blade system and I need to re-ack the chassis for new HDD. Is this the hotswap behavior? Can we have any explanation on this?
Hi
You certainly should not have to Re-Ack a chassis after swapping a hard disk.
The only time you need to Re-Ack a chassis is when you have changed the number of FI to FEX links or during an initial chassis discovery if you are using more links than that defined in your chassis discovery policy.
This certainly needs more investigation.
Colin
Hey Guru,
I’ve read through all of these comments but I don’t think I saw anything in here address the vSphere 5 configurable maximums. I’ve done some research but I can’t get a clear answer on this. Here is a quick background of my setup:
2204 Fabric Extenders
B200 M3 Blades with 1240 VIC
No additional mezz cards.
So now the question is – vSphere 5.x has 8 10Gbps NIC configurable maximum. If I carve up 8 10Gbps vNICs for VMware to use, does it actually count the 8 vNICs against the configurable maximum or does it only see the 2 physical NICs from the 1240 VIC?
Thanks in advance!
Hi Jeff
The two 10Gb traces per Fabric on the VIC 1240 are completely transparent to ESXi. ESXi will only see the vNICs you have created in the Service Profile (Uses a similar technology to SR-IOV). What I crudely call “Virtual Physical NICs)
However there is some Cisco “special source” that does not seem subject to the usuall VSphere configuration maximums. While I’m not privy to exactly how this works, and how ESXi allocates memory to these “Virtual Physical NICs” I know you can go alot higher than the usuall 8. From memory I think 32 Static vNICs are possible with many more Dynamic vNICs possible (upto 116) if using VM-FEX
All this said I have rarely needed to use more than 8 Static vNICs as my preference is to use an HA pair of uplinks on. DvS like Nexus 1000v and then perhaps another couple of pairs of a management and vMotion vSwitches (if you don’t want the N1KV to handle these )
Regards
Colin
Hi,
I am not sure which management monitoring policy to choose in UCS manager. The choices are quite easy to understand except for Media Independent Interface status which i dont quite get what it is or what it does exactly. If you could shed some light on this for me, i would appreciate it.
Thanks,
Hi Noorani
I would recommend the “Ping Gateway” option as that in my opinion is the most logical option.
You can think of the “Mii Status” option as monitoring the internals of the MGMT 0 interface itself or more accuately the inteface between the Phycial Layer Chip (PHY) and the Ethernet MAC control Chip
Regards
Colin
Hi Colin,
I have a problem with UCS uplinked via FCoE from FIs to Nexus 5548UPs and want to see if you have encountered anything similar. After configuring a FCoE Uplink port-channel (2 interfaces, via twinax cables) from the FIs to Nexus switches and disabling the native FC Uplinks, storage performance is severely degraded (multipath software shows big queues).
Ethernet and vfc interfaces show no drop or errors on both FIs and Nexus switches.
But after reviewing “show queuing interface ethernet 1/5” i see a lot of packets discarded on ingress:
qos-group 1
q-size: 79360, HW MTU: 2158 (2158 configured)
drop-type: no-drop, xon: 20480, xoff: 40320
Statistics:
Pkts received over the port : 809739
Ucast pkts sent to the cross-bar : 743529
Mcast pkts sent to the cross-bar : 0
Ucast pkts received from the cross-bar : 67599
Pkts sent to the port : 67599
Pkts discarded on ingress : 66210
Per-priority-pause status : Rx (Inactive), Tx (Inactive)
I’ve found the same problem on Cisco Support Community: https://supportforums.cisco.com/thread/2189106 but no viable solution.
Could you point me in the right direction to troubleshoot.
Thanks in advance
Best Regards,
Adi
Hi Adi
Thanks for flagging this to me, when I tested out multi-hop FCoE in my lab I just used a single FCoE link for all LAN and SAN traffic between FIA and IOM A (no vPC) and same for Fabric B. Must admit I didn’t do to much in the way of performance testing. But your issues and those listed on the CSC sound pretty dire.
Has anyone opened an SR on this? If not suggest you do, so this issue is officially recorded by TAC.
In the meantime I’ll see if I can replicate the issues in my Lab.
I’ll update this thread if I find anything, or would appreciate if you would If TAC resolves the issue.
I know the first Maint Release for 2.1 is due out shortly, so this may well be addressed if it was a known issue.
Colin
Hi Colin,
thanks for taking interest.
I’ve opened a service request and will update the thread if TAC resolves the problem.
Regards,
Adi
Hi,
here is a small update; I’ve spoken to TAC but they said we need to turn up the FCoE Uplinks so they could do the troubleshooting but unfortunately we were unable to since this is a production environment now. I’ve asked if they could recreate the problem in a LAB, still waiting for reply. They also suggested we update the Win2012 server HBA drivers since they were not the latest and test again.
Have you been able to test this problem in lab enviroment Colin?
Regards,
Adi
Just to update the thread, seems that the problem was QoS bandwidth reservation mismatch between UCS and Nexus.
Cisco community thread: https://supportforums.cisco.com/message/3897188#3897188
Adi
I have a UCS version 2.1 with (4) B200-M3’s and (2) 6248’s. My core switch is a Nexus 7000 with 10G ports available. I currently have FC storage presented and that is running fine. I want to add an iSCSI storage appliance with 10G ports and don’t know where to start. I don’t need to boot from iSCSI. Connect the iSCSI to a port on the Nexus 7K on its own VLAN and create an iSCSI vNIC in the Service Template?
Hi Brian
I appreciate your frustration the focus certainly is on booting from an iSCSI target these days and plain old iSCSI access is often just passed over.
The simplest method is just create an additional regular vNIC (Only use iSCSI vNICs for iSCSI boot) call it iSCSI give it an MTU of 9000 and assign it to a QoS system class configured with an MTU of 9000.
Create a seperate VLAN for iSCSI and corresponding iSCSI subnet
Then just configure your iSCSI via your OS as normal.
Regards
Colin
Have you seen bugs in UCS Central? I can barely get it to do anything after log in. There have been no updates since release and I have yet to see anyone report the problems I have been seeing. I was assuming I am the only one using it. Things like “Communications error, click OK to restart”.
Hi Daniel
I have had some intermittent connectivity issues with UCS Central, I.e. all is well then perhaps when I choose launch UCS Manager I get a communications failure or something. I resolved these by de registering and re registering the UCS Domain from UCS Central. My UCS Central has been fine since.
Regards
Colin
I had the same problem, spent some time looking into firewall logs (I am assuming that the UCS Central and the Management workstation are on different networks) and found that port TCP843 was been blocked, Used by Adobe Flash. Seems that if that is blocked it will boot you every 10 minutes or so.
Regards
Lee
hello
I have a service profile that consists of 10vnics. this is because I am running 2 vnics for nexus 1000v. and the other 8 for 4 dvs switches – vmware mgmt, vmotion, vms and iscsi.
I needed this because I can change a vm from a dvs to the nexus anytime I want.
Do you see any issues with this service profile config?
thanks
Hi Colin,
Your tips for IT people are really great.
I have one more question regarding the FI.
Current FI’s version 4.1- in a UCS infrastructure are old version and the UCSM version is 1.3. One of the FI is out order, it is dead now. We received a new one it is with it is with latest updated.
Can we downgrade the IOS version of the new to the current UCS Infrastructure.
What is the best solution in this kind of situation, we are in Production and downtime is a question.
Thanks & Regards,
Aamir
Hi USC guru
what a great blog, Thx a lot for your work here… absolutely phantastic.
I’ve also an unanswered question. Because I haven’t found anything which helps solving my problem, I will ask you to help me.
I want to install Windows Server 2012 Hyper-V on USC B200 M3 blades with iSCSI boot from a NetApp iSCSI target. I found nowhere a solution how to configure it. I configured in the past iSCSI boot for vSphere ESXi 5.0 and it works great.
Can you help me, what steps I have to do, to implement iSCSI boot for a Windows Server 2012 Hyper-V host?
thanks and regards
Reto
Hi Reto
Apologies for the delay, I’ve been working away all week.
I’ve not done too much around Hyper-V as yet, I’m much more of a VMware guy
so I’ve had a quick look around too, most of the iSCSI boot for Windows docs / posts I have found apply to W2K8R2.
Sounds like you need to write a “how to” guide for Booting Windows server 2012 Hyper-V
Colin
Hi Colin, we are planning to build a small cloud with KVM and OpenStack,
we’d like to use five UCS C240 for HYP, and NetApp as storage.
What is the basic configuration you suggest using UCS, to reach the goal to have from the beginning 10Gbe and a Network scalable and ready to grow.
The matter is, we have small budget to start, but we’d like to keep the possibilty to grow doing some nice choise !
Regards
Mark
Hi Mark
Can’t really give you a kit list without really going into your requirements.
But based on what you mention above, you may be better off looking at a small B series setup or even something like an ExpressPod or small FlexPod (if you haven’t already bought the Storage) The key fact you mention is ready to grow there is a tipping point when B series becomes a better value propersition than C series which can be around the 5 Rack mounts you mention.
Regards
Colin
Hi Colin,
I was wondering if you can provide some visibility on the process for configuring connectivity between Cisco FI 6296, MDS and SpectraLogic T120 Tape Library? We are currently using a 5108 Chassis, B200 M3 blades, vSphere 5.1 installed and RHEL6.2 guests operating system. I would like to use a virtual machine for accessing the Tape Drives via 8Gb FC. From my understading, this would be the steps required. Would you mind clarifying the process?
1) Connect Fabric from FI to MDS
2) Connect Fabric from Tape Library to MDS
3) Configure FI Ports as “FC Uplink”
4) Provide WWN and Zone Accordingly
5) Create vHBA Pool and Template
6) Assign SP Template to Blades
7) Confirm NVIP is enabled on MDS Switch
8) Configure VSAN on Both Sides {Default or Custom}
9) Configure Virtual Machine As Pass Through
10) Validate Connectivity
Cheers,
Mike
Hi Mike
I have had similar requirements in the past.
Last time I checked (and I don’t think things have changed) the vHBA’s on a Cisco VIC did not support pass through (VMware DirectPath I/O)
Whenever I have required tape drive access I have used a small blade with a Baremetal O/S
Regards
Colin
Hi with all this UCS 2.1 goodness I love to get there. With that said I am currently running 1.4 and would like to upgrade to 2.1. With that said any gotchas or upgrade advisers out there to check the current system and what (if any) gotchas going to 2.1) I realize there are Cisco docs out there and I have read them albeit a bit dry none the less the intent is to save your bacon but how about a readers digest version of an upgrade it..?
I am running (2) chassis with 16 blades and I do have (2) FI’s
p.s.
I like the idea of an upgrade advisor tool to run against it 🙂 (if it existed)
Hi Pete
Your doing the right thing, dry though they may be, follow the correct upgrade guide 1.4 to 2.1 in your case.
I still do even after what has probably been 50 or so UCS production upgrades.
The main thing is to ensure your environment is stable and configured for fabric resiliency (so when the FI’s get rebooted there are no unpleasant surprises.
Also even though this process should not cause an unplanned outage, always perform the upgrade in a maintainance window.
Good luck
Colin
Thanks for the reply Colin. One of the things I was reading is something about no longer supporting default vlan. I looked at my current config and it shows the default id is is disabled. From seeing that I will assume it should be no problem for the upgrade to 2.1 from 1.43l?
Hi,
I have following devices with me and need your help on design.
2 UCS 5108 Chasis
16 B200 M2 blades
1 UCS 6100 Fabric Interconnect switch
1 Core Switch Nexus 5548 UP chasis 32 10 GbE Ports
1 SAN Switch MDS 9148
1 Storage EMC VNXe 3100 with 12 TB (3 TB SAS + 9 TB SATA)
Hi The above is fine, but obviously you will have no redundantcy in the Fabric Interconnects and only have half the available bandwdith of you server Mezzernine adapters.
While you could use your MDS as SAN Fabric A and Portion off a block of your Nexus 5548UP as a SAN switch B, I don’t really see the point given you only have one FI.
I guess this is a Lab setup or Test / Dev or somthing.
Anyway your kitlist pretty much dictates your design, which would be somthing similar to the below.
Regards
Colin
Thanks for your reply. There are some changes in my devices. Now I have following devices with me.
2 UCS 5108 Chasis with 4 2204XP I/O modules
16 B200 M2 blades
16 Cisco UCS VIC 1240 modular LOM for M3 blade servers
16 Cisco UCS VIC 1280 dual 40Gb capable Virtual Interface Card
1 UCS 6248UP Fabric Interconnect switch
1 Core Switch Nexus 5548 UP chasis 32 10 GbE Ports
1 SAN Switch MDS 9148
1 Storage EMC VNXe 5100 with 12 TB
My confusion is can i connect 2 FEX from one chassis to 1 Fabric Interconnect and what is the use of 1240 and 1280 VIC if I can not connect 2 FEX to 1 FI?
Regards
Hi Mike, I have a question regarding the speed/BW of vNics we create put of VIC 140/1280. Lets say I am using 6248 FI’s and 2208 IOM’s and I connect all 8 ports from each I/O module to FI, so I will have 80 GB B/W on each IOM going to FI. I have a VIC 1240 adapter on all of the 8 blades on the Chassis and I have ESXi installed on all 8 blades. So lets I want to have 4 nics on each ESXi hosts. What will be the speed of each nic on each host? Is it 10 GB(thats what we see in Vcneter) or is it less than 10 GB or this speed depends on the number of connections between IOM and FI?
Thanks,
Bhargav
Hi Bhargav
If you are using a VIC 1280 with a 2208 and are using all 8 FI to FEX Links then each one of your blades will be able to drive upto 40Gb of I/O per fabric (Upto 80Gb Total)
As far as your vNICs are concerned yes they will be reported by the OS as 10Gbs, but the traffic eminating from those vNICs will be load balanced across each of the 4 x 10Gb Traces (KR Ports) on The VIC 1280 Fabric to which it is mapped. EACH of these load balanced flows are limited to 10Gb, so your single vNIC could in theory drive upto 40Gb but is likley more dependant on the OS Driver and OS Policy. (I feel an Network Traffic Generator test coming on)
The fact that you have 80Gb of bandwidth between the FEX and FI would mean that there is no inherent bottle kneck between them for a blade driving 40Gb of I/O.
Hello,
Wondering if you can help, i am a USC novice, however i have been tasked to set up boot from iSCSI SAN. I am currently using firmware 2.1(1a). Any help or pointer would be greatly appreciated.
Hi Neil
The below link details the setup of iSCSI boot.
http://www.cisco.com/en/US/docs/unified_computing/ucs/sw/gui/config/guide/2.0/b_UCSM_GUI_Configuration_Guide_2_0_chapter_011101.html#concept_CFF6B18F18684915816935F89B62CCAC
Also Craig over at RealWorldUCS has also done a nice iSCSI boot video
Regards
Colin
Hi there,
so I have been working on Vblock installs for a while now typically just handling the storage and fabric portion. My question is when doing a manual blade add it asks for a vhba for boot policy and I usually use whatever wwpn I have zoned to the new hosts such as vnx spa or spb ports. I am a little cobfused about
Hi Lee
When you are creating a Manual Service Profile, thats when you specify how many vHBAs you want in your Server commonly 2; I tend to call them
fc0 and map to Fabric A and fc1 mapped to Fabric B.
The Server will then want a single WWNN for the blade and each vHBA’s will want a WWPN, you can either just pull these from a pool you create (by far the best and easiest method) or you could just manually define them.
This is great as you are able to code alot of granular detail into your WWPN’s which can make trouble shooting a dream (example below)


.
.
.
.
.
.
Once the Servers vHBAs are configured and have addresses, you can then create your Boot from SAN Policy. (example below)
.
.
.
.
.
.
You would generally add two targets per vHBA (These would be the WWPN’s from your VNX SP ports.
The diagram below shows a typical UCS SAN setup

.
.
.
.
.
.
There is loads of info in previous answers on this page about how to setup and troubleshoot boot from SAN.
Good Luck and keep them Vblocks rolling!
Regards
Colin
Hello Colin,
First of all I’m really impressed of your knowledge and all the different topics you are talking, or writing, about Cisco UCS! Great site! Thanks a lot!
Actually I have two questions about Cisco UCS, whereat you hopefully have an answer on each of them for me.
Just to give a brief overview of our environment:
2 x datacenters with each of them having:
– 2 x UCS FI 6248UP (in Cluster)
– Each FI has 2 x 10GE-LAN-Uplinks and 6 x 8Gbit/s-SAN-Uplinks (to Brocade DCX Fabrics)
– 4 x UCS 5108 Chassis with each having two 2204XP I/O Modules (two ports of each 2204XP are wired)
– Each Chassis has 8 x B200 M3 Blades
– Each Blade Server has two E5-2680, 192GB RAM (24×8), one VIC 1240 LOM, no local storage
Ok, let me come to my questions:
1) As we have 32 Blade-Servers per datacenter, I have to assign 32 management-IPs for each Blade-CIMC plus 32 management-IPs for each Service Profile. Due to the fact that the management-IPs are placed in a pooled IP-range I thought I just have to reserve like 10 IPs and UCS takes care to assign an IP to an blade-server or a Service Profile that should be viewable through KVM. If I just assign 10 IPs into the pool and connect the FI to UCS Central, it even does not allow the association of new created Service Profiles to Blade-Servers… It stucks in the creation process. If I disconnect UCS Central it allows me the creation of SPs just until the pool is full.
2) For troubleshooting reasons I wanted to disable consecutively the assigned vHBAs to a Service Profile. Each SP has two vHBAs (vHBA0 and vHBA1). As I didn’t know how, and the complete environment is still under construction, I was able to disable all SAN-Uplinks, first of fabric A, then of fabric B. But in production usage I think this won’t be possible. So is there a possibility to shut down a virtual interface (may it be veth or vfc)?
Thanks a lot!
Regards
Hannes
Hi Hannes
Thanks for the question
Not sure I fully understand the first question,
The Management IP address is mandatory for the Blades (CIMC) and as soon as you create the pool All blades will take one.
The Management IP addresses for Service Profiles are optional (use them if you need a consistant KVM address if the SP moves to a different blade)
I certainly haven’t had any issues around UCS Central caused my Management IP Pools, (every UCS Domain I have added, has always had plenty of Management IP Addresses in it.
2) No affraid you can’t shut down a veth or vfc within an FI (would be good if you could), what I have done in the past as the next best thing is disable the NIC under the host OS for the vNIC and put the vHBA into a VSAN that does not exist in the upsteam fabric (This brings down the HBA)
Feel free to fire back with some more info.
Regards
Colin
Hi Colin,
thanks for the answer.
For question 2) Thank you for the workaround. A quick possibility of “shut” and “no shut” would also be great from Cisco. Let’s see what future versions bring with them…
For question 1)
I wasn’t aware that the Management IP addresses are mandatory for the Blades (CIMC)…
My understanding of a Management IP-Pool was, that I e.g. have 10 IP addresses and these 10 IP addresses are mostly unused. But when a KVM connection is needed, UCS should associate one free IP of the 10 IPs to the requested Blade. And after the KVM session is closed, the IP should be released from the blade.
So to say, to “save” IP addresses…
So if I got you right I must have at minimum the exact number of management IP addresses as the number of blades I’ve got. Right?
But I don’t have to have furthermore reserved IP address for Service Profiles, if I don’t want to have static management IPs for ServiceProfiles, do I?
Thanks in advance
Hannes
Hi Colin,
Like everyone here, I really appreciate the clarity and depth to this product line. I also appreciate your responsiveness to this venue. Bravo!
I posted a message further up in response to one of your responses, but I wasn’t sure if you’d catch it so I thought I would re-post it here with the most recent questions and provide a little more detail.
On October 14th 2012 you answered Tarun’s question about Static and Dynamic Pin Groups. My question is along those lines.
I think I know the answer, but I thought I would post it to make sure. Starting with the assumption that you have one static pinned uplink and two dynamically pinned uplinks (in a port channel). I realize that the only traffic destined for the static uplink would only be that which is in the pin group. Everything else would crowd out the dynamic ports. What happens if both of the dynamically pinned uplinks go down? I assume the traffic will use the only uplink left… the static pinned uplink. Any port in a storm I guess. Is that correct?
Here’s why I ask the question… we have a local 8509 in our datacenter that we will have both fabrics attach to via port channels. For fail-over use only, we’d like to connect single links from each fabric to another 8509 that we’ve got in another part of the building using long-range optics. We don’t want any traffic to use the fail-over link unless there is a failure of the datacenter 8509. Since I’m not aware of any ability to put a cost on the paths, I thought a statically pinned uplink along with an empty pin group associated to the fail-over uplink would do it and offer us the greatest amount of flexibility. Does that sound reasonable?
Thanks for any help you can offer!
Troy
I quick follow-up to let you know where I came up with this idea. @2:10 in Brad Hedland’s Part 7a video on End-Host Mode Pinning indicates this is the case, but I just wanted to verify this because I wasn’t able to find it in the documentation. Brad’s videos http://bradhedlund.com/2011/03/08/cisco-ucs-networking-videos-in-hd-updated-improved/
Hi Troy
Firstly appologies for my lateness in answering, I’ve been working away all week and have been totally maxed out.
Anyway I did answer your first question about and hour ago but thanks for adding in the additional info it gives the question the context it needed.
But affraid the answer is still the same, the Dynamic vNICs will not failover to the Static Target, but instead will either failover to the other Fabric (if configured for fabric failover) or just rely on having a teamed member in the other fabric.
You could have a link or channel to the non DC switch but you would need a L2 port-channel between your DC switch and your Remote switch. Which may have a sub-optimal effect on your traffic paths.
Perhaps better to put the link in and disable it at the FI end, and enable it in a DC switch failure scenario (if you can still get to it that is)
Regards
Colin
Hi Colin,
Your tips for IT people are really great.
I have one more question regarding the FI.
Current FI’s version 4.1- in a UCS infrastructure are old version and the UCSM version is 1.3. One of the FI is out order, it is dead now. We received a new one it is with it is with latest updated.
Can we downgrade the IOS version of the new to the current UCS Infrastructure.
What is the best solution in this kind of situation, we are in Production and downtime is a question.
Thanks & Regards,
Aamir
Have a question, why i could not able to set BIOS backup version for some blade models (ie: i have used B230 m2 blade, VIC 1280 and UCSM firmware 2.0(4b). unable to update bios firmware, set backup version. it appears N/A why ? hardware is not supported upgrade bios via GUI?
Hi
It may well be that your running BIOS version is the first version that supports your hardware, thus a backup version is unavailable.
Regards
Colin
Colin,
I and my implementation partner have been scratching our heads about an error that we received. First, let me define my environment. I have a Cisco UCS 5108 with 6 UCS B200 M3 blades. We are using an EMC VNXe 3100 for storage (iSCSI), and VMWare 5.1 Standard for virtualization.
We have the blades installing the VMWare without any problems. The problem comes on the reboot. We receive an error that Bank5 and Bank 6 are not VMWare boot bank, and no HyperVisor is installed.
The common answer is that did we change the boot from UEFI to BIOS, and the answer is no.
Any advice or direction would be greatly appreciated.
Thanks in advance for your assistance. Jimmy
Hi Jimmy
Must admit have not seen that issue before.
Are you using the Cisco OEM version of 5.1? available here.
If you still have issues fire, back or open a Service Request.
Colin
Colin,
Yes, we are on that version. The problem was the fact that the iSCSI NIC was set for jumbo frames with an MTU 9600. The underlying NIC was set for the same MTU. In some other research, we found that even if the iSCSI NIC is set with an MTU 9600, the underlying nic needs to be set at 1500. Once we made that change, the boot from an iSCSI SAN worked.
Jimmy
Total newbie question…created a server profile, specifying local disk in the boot policy as 1st in order, with CD-ROM as 2nd in order. (The boot policy instance specifies a Raid-1 configuration).
The server boots to the CD-ROM as expected (RHEL 6.4 install iso); but after successful installation and reboot the server does not/will not boot from local disk despite the policy. Am I missing a step somewhere?
I was able to install/boot another blade without a problem. Interesting that in comparing Bios settings, the problem blade does not see the disk but the successful blade does. I’m suspecting a hardware/controller problem; however, the bios will not let me disable quiet mode so I can’t get into the controller setup. If anyone has any other observations/thoughts I’d welcome them.
Thanks,
Peter
Hi Peter
No sounds like your doing everything right, if your Hard Disk is above your CDROM in the boot policy and it has a bootable OS on it then that should be all that is required.
If your same Service Profile works on one blade but not another, then as you say sounds like that blade may have an issue.
Sounds like the best thing to do is open a service request.
Colin
Hi ucsguru,
I wonder if you can give me a quick explanation. We have Vethernet interfaces created for the vNIC paths to the servers, however when a blade is decomissioned our monitoring tool see’s these as down, when we put a new blade in and commission it, the UCS dynamically creates new Vethernet interfaces but the old one’s are not removed and our monitoring tool keeps logging alerts for these interfaces showing as down.
Should we stop monitoring Vethernet interfaces as these are dynamically created by the UCS and can not be statically monitored, does the UCS not remove old unused Vethernet interfaces?
Thanks in advance.
Simon
Hi Simon
You are correct that vEths are dynamic and will be created and deleted as Service Profiles are associated and disassociated from the blades.
First a quick word on vEth behaviour.
The vNICs and therefore their corresponding vEths are created when the Service Profle is associated to the blade (during VIC programing while automatically PXE booted from the UUOS ISO on the Primary FI) Once created the vEth remains down (nonPaticipating) until the server O/S boots.
If the Server is Shutdown the vEth remains but is brought to a down state (BoundIFDown)
If the Service Profile is Disassociated from a Blade then the vEth is deleted from the Fabric Interconnect. (If yours are not it may be a bug in your UCSM version)
If the Service Profile is then re-associated (Whether to the same blade or not) UCS Manager will assign a different Channel ID’s and therefore different vEths ID’s to the vNICs.
So now we understand the vEth behaviour, you can make the decision whether to monitor them or not. If your environment is static and Service profiles don’t get disassociated very often then there is probably no harm monitoring them. If you have a more dynamic environment then you will probably get a lot of “False Positives”.
That said all the causes that I can think of that could bring a vEth unexpectedly down will alost certainly generate another alert i.e. failed FI Port / Failed VIC. And there is not much chance of a Virtual Cable being pulled out 🙂
Hope that all helps guide you.
Regards
Colin
Hi Colin,
Many thanks, I have another question, if I add new RAM into a blade does the service profile need to be disassociated/re-associated for the changes to take affect?
No you don’t. Think of it the same way as adding RAM to a regular physical server. Power down install the RAM and power back up.
Okay well that causes me an issue, as the server got stuck in a reboot cycle and had to be hard shutdown and disassociated/re-associated from profile before it worked.
Thanks UCSguru for your reply. There are some changes in my devices. Now I have following devices with me.
1 UCS 6248UP Fabric Interconnect switch
2 UCS 5108 Chasis with 4 2204XP I/O modules
16 B200 M2 blades
16 Cisco UCS VIC 1240 modular LOM for M3 blade servers
16 Cisco UCS VIC 1280 dual 40Gb capable Virtual Interface Card
1 Core Switch Nexus 5548 UP chasis 32 10 GbE Ports
1 SAN Switch MDS 9148
1 Storage EMC VNXe 5100 with 12 TB
My confusion is can i connect 2 FEX from one chassis to 1 Fabric Interconnect and what is the use of 1240 and 1280 VIC if I can not connect 2 FEX to 1 FI?
Also can you please tell me what kind of cable (part number) I need to connect MDS to Fabric Interconnect and VNX 5100.
Can I use VMware Free Hypervisor in above environment?
Regards
Hi
In answer to your questions.
Q) “Can i connect 2 FEX from one chassis to 1 Fabric Interconnect”
A) Absolutley Not! Both fabrics must remain isolated from each other (see below)
Q) what is the use of 1240 and 1280 VIC if I can not connect 2 FEX to 1 FI
A) You will still get 20Gb of usable Server bandwidth with a VIC 1280 and your 2204XP IOM over your single Fabric
Q) Can I use VMware Free Hypervisor in above environment?
A) Yes Stand-a-lone ESXi (Free) is fully supported.
Regards
Colin
Thanks Guru.
As per your explanation. Even though I have 2 FEX per chassis, I can connect only left side of IOM from each chassis to Single Fabric Interconnect and my right side of FEX from each chassis will be ideal.
Do I need both 1240 and 1280 VIC? Can I work with only VIC 1280 and get 20 GB of usable server bandwidth?
Is 1240 and 1280 for adapter redundancy? If yes how to configure it?
With above setup in future can I add one more FI and get redundancy easily?
Regards,
Hello Guru,
Was reading through multiple posts of yours. Great stuff. The vmware port-group diagram with vNIC is an awesome depiction.
Can you please share me the dropbox link. The link you have provided doesn’t seem to work.
https://dl.dropbox.com/u/36029701/VMware-Stencil1-UCSguru.zip
Thank you
Cheers,
Sandeep
Hi Sandeep
Yes appologies, I only have a 2GB Dropbox and needed the space, maybe one day I’ll buy some more space 🙂
Have added the file back in
https://dl.dropbox.com/u/36029701/VMware-Stencil1-UCSguru.zip
Regards
Colin
Hi Colin,
I have a couple of good questions about direct-connected SAN cabling.
1.When we connect directly VNX to Fabric Interconnects and want to use native FC, which TwinAx cables do we use? “Active”?
2. When we connect VNX directly to Fabric Interconnects and want to useFCoE, which TxinAx cable should we use?
3. When we connect VNX directly to Fabric Interconnects and want to use iSCSI protocol, which TwinAx cables do we use?
Thanks!
Hi Alexey
1) TwinAx is Ethernet not Native FC 😉
2) / 3) The VNX range support Active TwinAx cables
There is a section on VNX and TwinAx in the below whitepaper
Click to access h8217-introduction-vnx-wp.pdf
Regards
Colin
Hello UCSGuru,
How to connect FC Tape library to UCS environment to take data backup of UCS blades? Can we connect it to Fabric Interconnect?
Regards,
Hi Yes you can and with UCSM 2.1 you can now create Zones of the FI’s
You will need to put the FC portion of the FI’s in switch mode for direct N Port connection and configure your FI port which connects to the Tape Library as an “FC Storage Port”
Have a read of the below doc which covers all the FC Zoning configuration http://www.cisco.com/en/US/docs/unified_computing/ucs/sw/gui/config/guide/2.1/b_UCSM_GUI_Configuration_Guide_2_1_chapter_011011.html
Regards Colin
Hello UCSGuru, I have a problem that is really puzzling me. I have a new VM on the UCS chassis that is utilizing a newly created vlan on the Nexus 1kV, 5k, and Nexus 7k devices. After configuring the ip information on the VM it will not gain network connectivity. I have stand alone servers on the same vlan outside of the UCS working fine. The 1kV, which is connected directly to the UCS chassis can ping the vlan gateway(10.130.1.254) just fine, but it cannot ping the VM ip address (10.130.1.16). All other vlans are working on the UCS chassis. Any help would be appreciated.
Hi
Nexus 1000v Side
I would confirm that the VLAN you are using for your VM (the vEth port-profile) is allowed on your Physical system uplink (Eth Port profile)
Also that your VLAN exists in the VLAN database of the Nexus 1000v.
UCS Side
Also that the VLAN is created within the Cisco UCS VLAN Database and tagged on the ESXi Host vNICs that provide connectivity to the VEM
The fact the Nexus 1000v can PING the gateway only means the N1kv management is OK, the N1kv is only a layer 2 switch, so unless your VM is actually on the same subnet as your N1kv MGMT0 interface, this test doesn’t help much.
Good luck
Regards
Colin
We are planning some migrations to the UCS platform. There will be virtual as well as physical servers. Have you successfully completed any sort of bare metal restore (or P2P) to the Cisco UCS blades?
Hi Jason
Yes many of most flavours, my product of choice for this is PlateSpin Migrate, I have had issues getting the Cisco VIC drivers into the PlateSpin boot ISO, but found our PlateSpin supplier fairly helpful in assisting with this if we sent them the Cisco drivers.
Regards
Colin
Update capability catalog?
Since I am still pretty new with UCS I was adding a C rack mount server to our UCS which is still on 1.4 – anyhow I have the FEX 2232PP on there and notice that they are stuck in “identifying” this if the FI’s cant see those they arent going to see the C server. So I read some place from a fault message (cant think of the number off the top of my head) basically saying the catalog needs updating. I assume this is as simple as downloading the catalog and updating it? Should not disturb anything in the environment? firm ware is at 1,4 and the catalog is at 1.039 (or something like that. Any gotchas I need to know about?
Another question I have in a potential upgrade from 1.4 to 2.1 in the cisco doc it states:
Default Zoning is Not Supported in Cisco UCS, Release 2.1(1a) Onwards
Default zoning has been deprecated from Cisco UCS, Release 2.1(1a) onwards. Cisco has not supported default zoning in Cisco UCS since Cisco UCS, Release 1.4 in April 2011. Fibre Channel zoning, a more secure form of zoning, is available from Cisco UCS, Release 2.1(1a) onwards. For more information about Fibre Channel zoning, see the Cisco UCS Manager configuration guides for the release to which you are planning to upgrade.
Caution
All storage connectivity that relies on default zoning in your current configuration will be lost when you upgrade to Cisco UCS, Release 2.1(1a) or a later release. We recommend that you review the Fibre Channel zoning configuration documentation carefully to prepare your migration before you upgrade to Cisco UCS, Release 2.1(1a) or later. If you have any questions or need further assistance, contact Cisco TAC.
What is that exactly? Is it asically saying “If you use the default zone that cisco has when you install UCS it will no longer support it and if you use your own VLAN’s then you have no worries” ?
I also notice it says its not supported in 1.4 which is the version I am on. I am curious as I want to stay away from any issues 🙂 Sorry for the ignorance.. I just like this stuff and unfortunately an upgrade like this is nothing I can practice on except for the production equipment.
Hi Pete
What is meat by “Default Zoning” is that the default Zone in each VSAN can either “enabled” (fully open) or “Disabled” (fully closed). enabled meaning that all traffic is permitted among members of the default zone, thus relies soley on masking at the array to prevent initiatiors seeing LUNs they shouldn’t.
Zone inheritence was supported, in that id you uplinked to a Cisco MDS/Nexus SAN switch the FI could “Inherit” the Zone info, but in reality if you have a MDS or Nexus SAN switch in your environment why would’t you just connect your targets to them rather then the FI direct. (I guess if you have run out of ports / capacity perhaps, but still not a great solution)
Default zoning is not recommended for production environments, due to the openess and potential initiator to initator traffic or target to target traffic or any combination of each, which may cause issues.
If you upgraded a <2.0x working default zoned FI, to 2.1 all of your member ports within that default zoned VSAN would suddenly stop being able to talk to each other, and the FI would have to be zoned, as per a normal SAN switch to re-establish the required fc connectivity.
Hope that clears things up for you.
Regards
Colin
If you have a multhop FCoE design, edge-core-edge. And you use QOS System Classes in the UCS, do you need to have all the upstream switches support the COS’s also, so that the markings are honored on the packets?
Hi Saied
I would think if all of your ports end to end are FCoE ports and as such support the DCB standards (in particular 802.1Qbb, Priority-based Flow Control) The the default CoS assigned to fc traffic (3) will be honoured with the standard non drop class and 50% weight.
If at any point your traffic traverses native Ethernet links, then you would need to define a policy for CoS 3 to have jumbo frames and the weight you require.
Anyone else got any input?
Colin
Hi Colin!
I just had an odd event on one of my UCS installations. Both FI connections to my core switches blipped several times over a 8 minute period, dropping for right around a second each time. I don’t see to see anything in the logs on the UCS. Is there a good place to go looking for that? Thanks!
Jerry
Hi Jerry
Not somthing I have seen, before.
Assuming your upstream swicth ports are configured and channelled correctly i.e. “mode active” and set to “Edge Trunk” if Nexus and carrying multiple VLANs.
We would certainly need more info to troubleshoot this, i.e. UCS Code level, Config of UCS and Upstream switches, was this a one off, or does it occur regulally etc..
Probably not the best forum here, but definatley check the upstream switch config.
Regards
Colin
Hello,
We need to enable jumbo frames in our 7k/UCS/1k environment, and I have read the docs that explain fully how to accomplish this (by changing the QoS system class), there is nothing mentioned about any impact to traffic. I know, for instance, that when you change the MTU on physical links (vPC links, or even regular links) the ports bounce, so I am wondering if anyone here can point to documentation, or has explicit experience with whether any traffic disruption will occur when we change the QoS class to an MTU of 9216.
We are using updating vNIC templates in our environment, which call on the QoS policies defined.
Hi James
I have certainly changed the default MTU on the fly on a live production 5500’s with no impact, and would expect the same on a 7K, just remember that if there are multiple hops in the path your MTU would need to be set end to end, otherwise excessive fragmentation could occur, which may actually reduce performance or cause connectivity issues.
Proceedure for enabling Jumbo Frames on 5k and 7k
http://www.cisco.com/en/US/products/ps9670/products_configuration_example09186a0080b44116.shtml
The default MTU on the Nexus 7k is 9216 anyway (look for the line “system jumbomtu 9216” in your running config) if you need to change the default mtu on L3 interfaces (1500) just use the mtu command under that interface.
Regards
Colin
How does UCS work with Hyper-V? It seems that all I can find is with VMWare. I am specifically looking for information with integrating NetApp storage and Blade servers virtualized with Hyper-V.
Hi Mike
I’m similar in that 99% of my Cisco UCS Work is vSphere based, but I have done some Hyper-V deployments.
I’ve certainly not had any major issues with it, there is a fair bit of docs out there around Hyper-V on UCS
Try this one for an overview and access to additional white papers.
http://www.cisco.com/en/US/solutions/collateral/ns340/ns517/ns224/ns1150/ns1154/white_paper_c22-713212.html
Regards
Colin
Hi,
we doing a POC / Lab of UCS with 2 6248 FI and 3 blades. we are having issues connecting the uplinks to 3750x with port cahnnel group of 2 1 gig ports on both FI. port channel is configured as active on 3750 x. but still no luck on seeing the FIs on the network. vlans are same on both the sides.
Thanks
Zubair Rahman
Hi Zubair
I would check you have set your uplink ports on the FI’s to 1Gb.
Double Click a port>show interface> click the radio button for 1Gb
http://www.cisco.com/en/US/docs/unified_computing/ucs/sw/gui/config/guide/2.0/b_UCSM_GUI_Configuration_Guide_2_0_chapter_0101.html#task_544C54884DAD4B4982CC499A9EF41AA0
Regards
Colin
What are WWxN Pools?
Hi Saied
Just my Lazy way of representing WWPN and WWNN Pools at the same time 🙂
Colin
Does single wire management for c series rack mount require twinax or can I use fiber ?
Thanks
Hi Pete
Yes you can use the standard fibre sfp+’s
Regards
Colin
I have tried with no success. Firmware is at 2.1(1d) 2232pp fex and the end points of the c240 m3
Initially I had it with the 1 gb connected to the lom ports. I decommissioned the server and removed the lom connectivity. I powered on the server and the server does not discover unless I put the lom port connectivity back in play.
dear colin,
i have ucs5108 with 4 blade servers.i have installed esxi 5.0 on each blade..one of my blade does not ping the gate if i choose the nic 0..i have reconfigure the network and need to choose the 2 nic so it starts pinging the gateway..and when i try to add in my vmware cluster it keeps say ” the host couldnt see the HA..cant see the isolated ip add ex: 192.168.222.1
Hi Sam
It sounds to me like you NICs are ordered differently on each of you hosts.
I would suggest you check the order of the NICs in your service profile and reorder as required I.e your HBA’s would generally 1 & 2 so set your NICs to use 3, 4, 5. Just ensure your NICs have the same numbers across hosts I.e vMotion = 3, MGT = 4 and so on. So on you hosts you know the NICs are I’m the same consistent order. Then double check you are tagging the right VLANs on the correct NIC.
You could also bind these service profile to an updating template to ensure consistency.
Regards
Colin
hello colin,
thanks for the prompt reply..would u help me to check the nic card in service profile and could u pls tell me ..how to change it….
Hello Colin,
I have a production UCS environment with a single chassis that was originally provisioned without FEX port-channels, but the customer would now like to change this. Changing the global policy requires a re-ack of the chassis to pick up the change, but causes the whole chassis to lose network and SAN connectivity for a period of time.
Is the downtime period a serious concern to VMware’s access to its datastores, or will the hosts successfully buffer datastore access for a short period?
If the full disconnect from datastores is alarming, is there a method to modify the uplinks on a per-FI basis so that SAN connectivty can be maintained as the fabrics are updated one at a time?
There will be a off-hours maintenance window for this task, but the customer has indicated that they are not willing to do a full powerdown of the environment.
Hi Dave
I have done the same thing on many live Systems, A Chassis Re-Ack certainly does drop and re-establish all of the Virtual Network Links to that chassis and will cause approx 30 seconds of disruption.
In my experience I have never had a server crash through Re-Acking a Chassis (Most environments I build are boot from SAN). I have had a cluster shut down all of its VM’s as HA was set up incorrectly (both hosts in the same chassis referencing only the other host and set to shut down all VM’s if isolated.
Rather than Re-ack the chassis I have had success in shutting down the UPlinks from an FI, as there are then no uplinks for the vNICs and vHBAs to pin to The system shuts down all VIFs on that fabric and then once you bring the uplinks back up again, the system then picked up that the FEX to FI links were now a port channel. You might want to try this before the Re-Ack to see if that works for you. (Obviously check you have fabric fault tolerance correctly configured for you Service Profiles first)
Regards
Colin
What would cause a FC-Uplink port to fail with “initializing”? The MDS side sees the port and is showing up (green). The FC port on the UCS side is set as FC and is licensed.
Hi Michael
Could be a few things (besides dodgey hardware / cables), VSAN mismatch or another mismatch with the settings at one of the ends. I most commonly see this when users are trying to Trunk multiple VSANs down the link, or Port-Channel multuple links or both.
My advice would be take all of the ports out of the channel if using PC’s both ends and just check the link comes up with a straight F to N port setup, then you can add the links into the channel one by one.
Funnily enough I had this issue last week on an 12 port fc port-channel with VSAN tagging, all links were up, we then shut down the fc port-channel at the UCS end (Fabric A) to test the multipathing, this was all fine, but when I re-enabled the fc port-channel at the UCS end all fc ports just stuck on initialising.
I shut the ports down several more times and confirmed all settings, even just tried a single port, but that single port also stayed in initialising. Despite numerous Shuts/No Shuts at the MDS and the FI end (and a reboot of the FI) what finally cleared the fault was a reset of the line card at the MDS end.
This was traced to be a bug with the MDS code we were running.
Anyway hope that helps.
Regards
Colin
We have our UCS environment in a pre-production state and are doing some FC failure simulations for testing. We have (2) 6296 Cisco interconnect switches on the “A” and “B” side of the fabric. We have 8 NPIV connections from each interconnect to Brocade 6510s. We have 15-16 vWWNs (representing ESX servers) on each of the 8 ports on both sides of the fabric as it stands. Our test was to disable 1 of the 8 ports on the “A” side of the 6296 to see if the vWWNs successfully migrate to the 7 surviving ports on the Brocade 6510. That test was successful. All the vWWNs moved across the surviving ports. We then re-enabled that port and saw it come back on-line on the Brocade 6510. We kind of expected vWWNs to make there way back to the port that has now been re-enabled but that did not happen. The port came back up successfully but no WWNs moved back onto that port. We decided to disable another port on the “A” side to see if vWWNs would go back to that first disabled port. When that second port was disabled, all of those vWWNs moved to the original port we disabled. Excellent!
My question is, what (other than another link failure) will migrate vWWNs back to that failed port? After this test, we now have 7 active connections on the “A” side of the fabric and 8 on the “B”. I’m assuming that will hurt us bandwidth wise on the A side with 7 connections rather than 8.
Hi Keith
That is the correct bahavior to how UCS manages fc link failures, it can be made a bit more graceful using fc port-channels but as you probably know fc port channels are not supported between the FI and a Brocade switch.
The reason I guess there is not auto failback is that you want to be as least disruptive to fc traffic as possbile if a link has failed and the FI has had to to an fdisc (fabric discovery, (think flogi on an NPIV enabled port) then it’s best to just leave it alone rather than fail it back.
As soon as tou have an event that requires a vHBA to be pinned to an fc uplink, (link failure (as you found) or a service profile reboot, or a new server brought online) then your “unused” link once brought back up will quickly be used again. Don’t worry best just let the system handle this for you.
Regards
Colin
Gents,
Great content!! Quick question on the C series and managing through UCSM. I’m pretty sure I know the answer but want to double check. Is there a way to connect the C series directly to its Fabric Interconnects without going through a 2232 FEX? The question applies to both single and dual wire management.
Thanks!
John
Hi John
No, back in UCSM 1.4 days you connected the 10Gb ports of the C Series directly to the FI and the on board 1Gb ports to a 2248FEX, however in UCSM 2.0 this was dropped and from then on only connecttion (single wire, or otherwise) via a 2232 FEX is supported.
Regards
Colin
What up Guru!?
Awesome site – thanks for the all the time you clearly put into it!
Can you please affirm my thinking? I have a test lab with Controller A of a NetApp system directly attached to the interconnects of a UCS – so the interconnects are configured in FC Switch Mode. The interconnects will have FC uplinks to two Nexus 55xx’s. For testing native FC on the Nexus switches, I’d like to configure NPIV using a vSphere VM. All blades in my chassis are ESXi hosts. I’ve already moved Controller B of our NetApp system to the Nexus’. I’ve included a link to a ridiculously awesome mspaint picture of where I am currently.
http://www.evernote.com/shard/s290/sh/45cb1fc8-dddc-4325-8c40-3bfe7f54d459/a3ae983ec889d15282f15974d6340137
So my Nexus switches will be configured in NPIV mode. I understand that the interconnects will need to be configured in End-Host Mode in order for a VM on UCS to use NPIV. Is it possible to keep Controller A directly connected to the interconnects and switch to FC End-Host Mode? I know the interconnects will need to bounce, but will everything still function? Just remember, I’m holding you to this 😉
All the best,
Mike
http://VirtuallyMikeBrown.com
http://LinkedIn.com/in/michaelbbrown
Hi Mike
Thanks for the detailed question and masterful artwork 🙂
In short No, As I’m sure you are aware in order to use direct attach fc storage to the FI, you must be in fc switch mode.
You are right that the best way forward would be to put your FI’s in fc N port virtualization (NPV) mode (Think End Host Mode for fc)
Bascially this turns your FI’s into a Host which will then send FDISCs rather than Flogi’s to your Nexus Switch F Ports.
The Nexus switches will then have multiple WWPN’s/FCID’s associated with a single F port and be recieving FDISCs rather than Flogi’s, this is why you need to enable feature NPIV on your Nexus switches.
If you leave Controller A directly connected to your FI’s after your reboot to switch back to NPV Mode, Controller A will no longer have connectivity, as fc Storage ports are only valid in fc switch mode.
PS Had, a look at your blog, I like your down to earth writing style 🙂
Regards
Colin
Hi Colin,
Thanks for the prompt reply. That’s excellent news – thanks for the affirmation. And thanks for checking me out 😉
All the best,
Mike
Hi Colin,
Can I have an NPIV-enabled VM running on UCS blades? I can’t find anything anywhere about this. Sure, FC End Host Mode/NPV Mode for the interconnects and an upstream switch, such as Nexus or MDS in NPIV mode, but this is only for the ESXi hosts, right, not VMs? That’s not to say ESXi hosts can only run FC with interconnects in End Host Mode. FC Switch Mode works fine, too, if your storage is connected directly to your interconnects.
By the way, I finally finished my post on the work I did. Check it out if you like and feel free to point out any errors!
Thanks!
Mike
Hi Mike
I have never tried it, but can’t see why this would not work. As the Cisco VICs do not support vHBA pass through to a VM you would have to present a RDM through and then enable NPIV on the VM, the only reference in Cisco docs I can find on this is below.
http://www.cisco.com/en/US/prod/collateral/ps4159/ps6409/ps5990/white_paper_c11_586100.html
Please update this thread if it works for you, plus any findings/observations.
Regards
Colin
Ok, after scrutinizing my config and satisfying myself it looks good, I think the issue is that my VIC does not support NPIV. There are a few VICs that *do* appear to support it, though. This is based on the Cisco adapter data sheets.
Supports NPIV
M72KR-E (http://www.cisco.com/en/US/prod/collateral/ps10265/ps10280/data_sheet_c78-703582.html)
M73KR-E (http://www.cisco.com/en/US/prod/collateral/ps10265/ps10280/ucs_kre_emulex_ds.pdf.pdf)
Does *not* support NPIV
M72KR-Q (http://www.cisco.com/en/US/prod/collateral/ps10265/ps10493/data_sheet_c78-623738.html)
M61KR-I (http://www.cisco.com/en/US/prod/collateral/ps10265/ps10493/data_sheet_c78-623739.html)
M81KR (http://www.cisco.com/en/US/prod/collateral/ps10265/ps10280/data_sheet_c78-525049.pdf)
M73KR-Q (http://www.cisco.com/en/US/prod/collateral/ps10265/ps10280/data_sheet_c78-703587.html)
Thanks Mike, Useful to know
Regards
Colin
Hi Colin,
I have a question.
We have 4 UCS in our infrastructure and I have seen this issue only with the Q-logic Adapters, on our B200 M2 blades.
Random to different blades, when we do a Boot from SAN, it installs the first round of ESXi 5.0 installation and once it reboots, it doesn’t boot from the same SAN, instead it starts PXE booting.
The fix was to swap the Primary/Secondary targets by pressing ALT+Q/CTRL+Q on one of the two vhba(s).
Now for the first time I am seeing this in a Cisco VIC M81KR. And as there is no option of changing the Primary/Secondary targets as in Q-logic, the server is stuck in PXE boot loop.
Have double checked with our SAN team whether its something wrong in the Zoning or LUN mapping (we have IBM SVC) and also verified by LUNLIST on UCS-CLI :-
adapter 1/8/1 # connect
adapter 1/8/1 (top):1# attach-fls
adapter 1/8/1 (fls):1# vnic
—- —- —- ——- ——-
vnic ecpu type state lif
—- —- —- ——- ——-
13 1 fc active 10
14 2 fc active 11
adapter 1/8/1 (fls):2# lunlist 13
vnic : 13 lifid: 10
– FLOGI State : flogi est (fc_id 0x010122)
– PLOGI Sessions
– WWNN 20:15:00:80:e5:2c:46:8c WWPN 20:15:00:80:e5:2c:46:8c fc_id 0x010400
– LUN’s configured (SCSI Type, Version, Vendor, Serial No.)
LUN ID : 0x0000000000000000 (0x0, 0x5, IBM , SQ14900811 )
– REPORT LUNs Query Response
LUN ID : 0x0000000000000000
– WWNN 20:14:00:80:e5:2c:46:8c WWPN 20:14:00:80:e5:2c:46:8c fc_id 0x010000
– LUN’s configured (SCSI Type, Version, Vendor, Serial No.)
LUN ID : 0x0000000000000000 (0x0, 0x5, IBM , SQ14900168 )
– REPORT LUNs Query Response
LUN ID : 0x0000000000000000
– Nameserver Query Response
– WWPN : 20:14:00:80:e5:2c:46:8c
– WWPN : 20:15:00:80:e5:2c:46:8c
adapter 1/8/1 (fls):3# lunlist 14
vnic : 14 lifid: 11
– FLOGI State : flogi est (fc_id 0x010121)
– PLOGI Sessions
– WWNN 20:25:00:80:e5:2c:46:8c WWPN 20:25:00:80:e5:2c:46:8c fc_id 0x010400
– LUN’s configured (SCSI Type, Version, Vendor, Serial No.)
LUN ID : 0x0000000000000000 (0x0, 0x5, IBM , SQ14900811 )
– REPORT LUNs Query Response
LUN ID : 0x0000000000000000
– WWNN 20:24:00:80:e5:2c:46:8c WWPN 20:24:00:80:e5:2c:46:8c fc_id 0x010000
– LUN’s configured (SCSI Type, Version, Vendor, Serial No.)
LUN ID : 0x0000000000000000 (0x0, 0x5, IBM , SQ14900168 )
– REPORT LUNs Query Response
LUN ID : 0x0000000000000000
– Nameserver Query Response
– WWPN : 20:24:00:80:e5:2c:46:8c
– WWPN : 20:25:00:80:e5:2c:46:8c
Any help is appreciated, Thanks!!
Hi Shaggy
Do you have a Network option listed in your Boot from SAN, boot policy? If so I would remove it (at least for testing)
I have detailed Boot from SAN troubleshooting in some detail, higher up this trail. (I’ll list the time/date stamp when I get onto a decent device)
Fire back how you get on.
Regards
Colin
Hello Guru,
Very nice site. I’ve disovered it two weeks ago and was very impressed by these in-deep answers !!!
I’ve a “little” question about San boot Policies with UCS-B.
I’ve searched and read UCSM cnfiguration guide but didn’t find clear explaination about SAN boot policy path selection …
Here is my configuration:
UCS-B with SAN FC access to a netapp array.
FI’s are ecah connected to a FC fabric (FIA connected to SAN Fabric A and FIB connected to SAN Fabric B)
Each controlleur of NetApp array is connected to Fabric A and Fabric B
Everything is OK about SAN access from ESX (Round Robin, multipathing, failover).
My question is about SAN boot policy :
Here is my boot policy:
San primary : vHBA0 (on Fabric A) Lun ID 2 (Boot Lun)
– San Target Primary: Lun ID 2, P1 of NetApp controlleur 1 (on fabric A)
– San Target Secondary: Lun ID 2, P1 of NetApp controlleur 2 (on fabric A)
San secondary : vHBA1 (on Fabric B) Lun ID 2 (Boot Lun)
– San Target Primary: Lun ID 2, P2 of NetApp controlleur 1 (on fabric B)
– San Target Secondary: Lun ID 2, P2 of NetApp controlleur 2 (on fabric B)
How exactly UCS will select a Path to boot LUN and how does it scan HBA / Path to select a path if the first one is down and so on ?
I’ve read that it is somewhat based on PCI order but nothing more … and a can’t figure what will be the order of selection between those 4 paths ….
Thanks in advance
Regards
Sebastien.
Hi Sebastien
Glad you like the site.
There’s no wierd formula or anything for this the Service Profile will try and boot of the following paths in the following order.
SAN Primary – Primary Target
SAN Primary – Secondary Target
SAN Secondary – Primary Target
SAN Secondary – Secondary Target
For instance every Service Profile that is associated with your boot policy above, will boot of the SAN – Primary, Primary Target, and it will only move to the SAN – Primary, Secondary Target if the specified LUN is not found on the primary target within a set timeout period.
There is a school of though to create multiuple SAN Boot Policies and have a different Array front end port order in each, this will stagger the front end array ports that each Service Profile uses to boot. (you would of course need to associate these different SAN Boot policies to different SP’s which could require multiple updating templates etc..) For this reason I don’t follow this school of thought.
I prefer a single boot from SAN policy associated to a single updating template, this makes life easier all round. And as Servers generally are not rebooted too often there is not much chance of a “Boot Storm” causing congestion on your Primary SAN, Primary Target fromt end port. Once the Server is booted Multipathing techologies e.g MPIO / PowerPath kick in to make full use of all paths, (totally separate from your Boot Policy)
The only thing I would add is in VDI environments, where 100’s of virtual desktops could all get powered on first thing in the morning, you should be wary of boot storms, but this would not be subject to your Boot from SAN policy (which would only effect the host) but would rather be a potential issue with the LUN(s) that housed your VDI OS’s or VDI Gold Image, there are numerous ways of addressing this (Use of Flash disks, multipathing etc..) so well worth having a readup if this is a potential issue that would affect you.
Regards
Colin
Hi Colin,
do you have the information about the support for booting B-series of a SD flash card?
I cannot find any useful information and by looking at the UCSM it seems that it’s not supported yet.
Best Regards,
Adi
Hi
SD Flash boot is not supported yet as of (2.1f) Only internal USB boot is possible at the moment.
Have a read through the below thread on this.
https://supportforums.cisco.com/thread/2154478
Regards
Colin
Hi Colin,
i wonder if it’s possible to switch traffic within the same vlan no furthur than the Fabrics for a VMware-ESX belonging VM and a Hyper-v VM. i mean, not being needed to leave UCS to un upper switch. Thsi is the first time we need to have Vmware and Hyper-V within the same UCS. up to know because of the architceture we had specific enviroments (Vmware-HyperV). this is a new scenario where within the same UCS we’ll have Vmware-VM and Vm-Hyperv sharing the same vlans.Is it possible to switch this traffic on the fabric’s?
Thansk in advance.
Regards
Hi Gab
Yes, as long as the traffic is same VLAN same Fabric the traffic will be switched locally within the FI. To ensure this you can configure a single vNIC (Protected by Hardware Fabric Failover) for your traffic type I.e uplink from your vSwitch and SoftSwitch.
You won’t get Fabric load balancing for this traffic but you will know it will be locally switched within the FI. For other traffic types you can use the above technique but map to the other Fabric, or just use fabric load balancing for traffic types you don’t mind potentially being L2 switched upstream.
Regards
Colin
Well the last time I configured 6248 with an expansion module, it went upto 52 licensed ports.
Here is the breakup:
– 12 ports are pre-licensed for base ports
– 8 ports are pre-licensed for expansion module
– & CCW tool let me configure 32 UCS-LIC-10GE licenses more. :S
Keeping in view the total physical ports to be 48, howcome the tool is letting me configure 52 licenses?
Hi Saad
I’m not a big user of CCW, I mainly use NetFormX, but I agree with your logic, if you have the expansion module, you would only need 28 additional port licences to fully licence the FI.
Regards
Colin
I have one newbie question. We have 2 x 6248UP connected with cisco blade chassis and uplink to old MDS switch with other standalone FC hosts. EMC storage is connected also to 6248 directly. Could we connect our rack server with fc hba directly to 6248 and zone it with storage?
thank you…
Hi Johnny
You could do, if you are using direct attach storage already, you must have your FI in FC Switch mode already. And if you are using UCSM 2.1 you will have zoning options.
You obviously could also connect your rack mount HBA’s to your MDS if that also gives you the connectivity you require.
Regards
Colin
Hi Colin,
We have lab setup of a couple of N5010s connected to two 6140s (A &B) in a redundant setup.
(2 x 10Gb links) from each N5010 to FIs A & B. Only one Port-channel 119 (part of vPC 119) is configured between the N5010s and both the FIs. I saw some network designs which have two port-channels defined on the N5010s ( po50 & po51)towards each FIs as seen in the below URL. (Page 10 & 11)
Click to access SBA_Mid_DC_UnifiedComputingSystemDeploymentGuide-February2012.pdf
Which one is a better setup?
1)One port channel between the N5010s towards the FIs or
2) Two port channels, each defined separately for the FIs
Sample One port-channel setup:
——————————–
interface port-channel119
description PO119 link to FIs A & B
switchport mode trunk
vpc 119
spanning-tree port type edge trunk
spanning-tree bpduguard enable
spanning-tree bpdufilter enable
!
interface Ethernet1/1
description Link to FI A
switchport mode trunk
channel-group 119 mode active
!
interface Ethernet1/2
description Link FI A
switchport mode trunk
channel-group 119 mode active
!
interface Ethernet1/4
description Link to FI B
switchport mode trunk
channel-group 119 mode active
!
interface Ethernet1/5
description Link to FI B
switchport mode trunk
channel-group 119 mode active
!
Thanks,
PJ
Hi PJ
The FI’s should be treated as completely separate entities, they do not support LAGs/vPCs/ Multi-Chassis Etherchannel (MEC) between Fabric A and Fabric B, as such you cannot have a single vPC from your upstream Nexus switches to BOTH FI’s. the correct setup would be a vPC from The Nexus Switches to FI A, then a 2nd Separate vPC from the Nexus switches to FI B.
If you were not using vPC, but still wanted the benefits of EtherChannels you would have a 2 separate EtherChannels from each Nexus to each FI.
Regards
Colin
Thanks a bunch, Colin for your reply.
Great information on UCS on this website.
PJ
Hi Colin,
I am currently working on my first UCS installation. Current version is 1.43. We are using 6120XP FIs and B200 blades with M81KR VICs. Ethernet Uplinks are configured to 2 NEXUS 5548UP.
There are two vlans configured so far in all switches and also UCS manager.
I’ve installed 4 Linux hosts and 2 Windows 2008 (all bare metal installations). 2 VNICs were created on the server profiles and associated to each one of the VLANS (110 Public , 10 Private) with the native VLAN option unchecked. The problem i have is that traffic from ALL hosts is leaving untagged. I can ping the default GW for the public VLAN , that is connected to one of the 5548 , only when the port is on VLAN 1. I also reconfigured one of the host’s Public NIC to access VLAN 1 instead of 110 and it is still able to ping the other host in VLAN 110, which i think confirms that traffic is leaving untagged. Any thoughts about this ?
Thanks in advance for your help.
Alvaro
Hi Alvaro
It will do, unless you are using .1q aware driver on your Bare Metal host. If you have 2 vNICs in each host which are only carrying a single VLAN each. Then leave it default at the host (untagged) and then on the Service Profile vNIC tick the relevant VLAN for that vNIC (10 or 110 in your case) and also tick the Native box next to that VLAN.
Then all should be well.
Regards
Colin
Hi Colin
I have been watching your videos on VM-FEX which are very helpful. In my Lab, we have a 2104 with only one physical uplink from the FEX to the FI. The vmnic0 created is assigned to the vSwitch. I created a DVS and My doubt is, is it mandatory to have another physical uplink from FEX to FI or can I use the same vmnic0 as an uplink to the FI? Please share your thoughts.
To add to the above, we have only 1 FI and FEX module in this scenario.
Regards,
Ravi
Hi Ravi
You will need to create a dedicated vNIC for the Host to use as the VM-FEX uplink. Even though this vNIC does not actually get used, VMware does expect to see one and won’t work without it.
Also be aware that with a 2102XP FEX with a single uplink you be limited to 13 Virtual PCI devices (or more acurately VN-TAGS) for each Host, so for example if you use 2 x vNICs and 2 x vHBAs for your host that makes 4 “Static” PCI devices, which will leave you a maximum of 9 Dynamic vNICs which can be used for VM-FEX.
Regards
Colin
Hi Colin
Thanks for your quick reply.
Regards,
Ravi
We have 2 Cisco 6248 fabric interconnects, 2 UCS Chassis and 9 Cisco B230 Blades. We have 2 Esxi Clusters.. 5 UCS Blades for Desktops in one vmware cluster and 4 UCS Blades for Servers in another VMware cluster. We have recently added in 2 Nexus 5K switches with each one having a Nexus 2K line card. After the Nexus 5K addition we have a huge speed issue with random Vm slowness. Not all Vm’s are slow all the time. Sometimes it is desktops and sometimes it is servers. We have identified bandwidth bottlenecks between hosts that are connecting across the fabric interconnects. vm’s on same host talk fast. vm’s across hosts and clusters is where we run into issues. It seems it is when they are on fabric a talking to fabric b of the UCS. Any idea or ways we can troubleshoot.
Hi Greg
As Fabric Interconnect A and B are only connected by the upstream Nexus 5k’s, that may well be where your issue is.
However most performance related issues I see that are not Storage related come down to misconfigured QoS or MTU size.
If you have any configured maybe worth setting it back to defaults to see if that cures your issues, and if so then look into the settings you were using.
You should be using multiples of 10Gb links everywhere so I’d be very surprised if bandwidth is a noticeable bottleneck for you.
To confirm it is indeed inter-Fabric communication which is causing the latency you could map all of the vNICs of some test hosts to the same Fabric A or B. (bear in mind that L3 traffic (Inter-VLAN) will always get routed upstream. But same VLAN same Fabric will get locally switched by the FI. And do some tests I.e PING intra-fabric Vs Inter-fabric test on both A and B.
If that checks out and it is only Inter-Fabric comms where you see the issue, you can look at the links between the FI’s and Nexus Switches. Look at port stats both sides (use “connect NXOS” on the FI side)
Let me know how you get on.
Regards
Colin
Hi Colin
I have been following the procedure as shown in the VMFEX and was able to integrate vCenter and UCS manager and the VEM’s seem to be correctly installed on the hosts. However Im unable to ping the VM because of a slightly different scenario in my setup. Please review the below and let me know if Im missing something.
vSwitch Setup
————–
1) The setup contains two Vlans (Management and External). vmk0 adapter is assigned to the port group (PG 1) containing Management VLAN with the ESX host IP address.
2) The VM is on the External VLAN which is assigned to PG 2.
With this Setup, Im able to ping the VM.
VM-FEX
—————
1) Created a port group in UCSM which contains both the VLANs (Management and External) and the corresponding profile client was created in the vCenter
2) After migrating to the distributed switch and assigning the VM to the port profile client, Im unable to ping the VM.
3) Did not migrate the vmk0 adapter from Management VLAN on PG 1 of vSwitch to any of the port group on distributed switch.
Please let me know if Im missing something here.
Regards,
Ravi
What are known issues or risk of using JBOD on UCS. I know I can enable it by using the command “-AdpSetProp -EnableJBOD -1 -a0”, if you have done this and ran into problems or know any detail analysis good and bad contrast your thoughts are greatly appreciated it.
Hi Jeremiah
I don’t think there are any specific issues using JBOD around UCS, that you wouldn’t have with any other Server Model.
If you are happy not to have any RAID level protection for your disks (Most of my customers arn’t) then I guess go for it.
I am guessing this is just a Test/Dev lab where capacity is the overwhelming requirement and data protection is not required.
I have configured this on Lab servers (B and C Series) in the past and touch wood have not had a drive fail yet. (I have generally just used RAID 0 rather than the command you mention)
My preference is to always use diskless servers with all Boot and Data LUNs provided by a SAN, but appreciate thats not always possible or desired.
Regards
Colin
Hi Colin,
We have UCS 2.0 (5a) with 2208 IOMs and 6296 FIs. Blades are all B200 M3s with VIC 1240 and expansion modules. We are using vSphere 5.0. We have a basic design with (currently) three vMotion vNics with F.Failover enabled on diffeent VLANs. All are pinned to FI B to avoid hop up to Nexus &K switches. Each IOM has four uplinks to the respective FI. Rightly or worongly our VM vnics are pinned to FI A (using F.Failover) as it stands currently so there should be no contention on uplinks (but not necessarily on any shared queues on VIC card?)
The three vMotion vNics are configured to use vSphere multi-NIC vMotion. vMotion flows over all three vNics at approx equal bandwidth. We have noted that irrespective of how many vMotion vNics we use, we cannot get more than about 17Gb/s of throughput. So in summary we get no benefit with more than two vMotion vNics.
This is after a lot of testing ranging from single VMs with large memory delta, to many small VMs. Includes vMotion to hosts within same chassis or different chasses, and scenario where multiple hosts are sending vMotion data and one or two hosts on different chassis are receiving. We have configured workload so that the ESXi hosts are not running at more than 30% CPU during testing because we initially noted high CPU contrained vMotion throughput. We have also tested with large MTU (verifed using large packets with DF set), with vNic enabled for RSS, large (4096K)receive buffer etc.
We run Nexus 100ov in production, but have tested the above within N1K and also Standard vSwitch with little or no difference. Note that we do not set Host Control = Full because we had previously been informed it could reduce number of available queues and resultant contention and we validated this on earlier release of firmware. Rather we use QoS on UCS by applying policy to each “physical” vNic. vMotion vNics are assigned to silver with 20% bandwidth under contention. However based on dedicated connectivity to FI B there is no contention at all.
I was wondering if you had any thoughts on how we could increase vMotion throughput?
Would a placement policy help (or be relevant at all)?
Could this be anything to do with how VIC 1240 and the expander card interact?
(as per your excellent “20Gb + 20Gb = 10Gb? UCS M3 Blade I/O Explained” post).
Many thanks and regards,
Justin
Hi Justin
Thanks for the great question.
Sounds like you guys have been pretty comprehensive in your testing, most possible causes that went through my head as I was reading, you mentioned futher down (Large MTU etc..)
You are right that with the combination you have each server has a 40Gb connecttion to each Fabric, and that each 2208 has 40Gb of bandwidth to the FI. The first thing to confirm is that your links between the FEX and FI’s are Port-Channled (Not Default) This is under the Policies Tab under Equipment. If not your server will be “Pinned” to a particular FEX link and will not have access to the full 40Gb)
As you are getting results of upto 17Gb/s I would expect you are already running these links in Port-Channel mode.
Placement Policies would only come into play if you had more tham one VIC, the Port Expander just provides additional traces to the single VIC1240 you have.
There is a method of load balancing multi-NIC vMotion traffic across both fabrics, while still ensuring all vMotion traffic is locally switched at the FI Refer to this post http://www.bussink.ch/?p=262 by Erik Bussink.
If all above fails I would open a TAC case to confirm with them the throughput you should be seeing with 3 vNICs mapped to the same fabric. Theory says about 25Gb/s but as we know there are alots of other potential variables involved.
I would be really interested in seeing how this progresses, I’ll run some tests when I’m next in the Lab in a couple of weeks, but please post back if you have any updates in the meantime.
Regards
Colin
if Fabric interconnect A and Fabric interconnect B both of them Fails, what will happen in the Server level, Server will function normally and vm’s will up and running ?
Hi Ravi
If both your Fabric Interconnects went down you are in effect pulling the LAN cable out of all your servers. i.e all of your ESXi Server NICs (the uplinks to all your vSwitches would go down).
Not a very likley scenario though. A well designed UCS solution should be totaly resilient against a single FI failure though.
Regards
Colin
Kindly provide me the step by step firmware upgrade from 1.4 to 2.0 for UCS
Hi Ravi
Step by Step 1.4x to 2.0x Guides and Videos can be found at the below links.
Cisco PDF Guide
http://www.cisco.com/en/US/docs/unified_computing/ucs/sw/upgrading/from1.4/to2.0/b_UpgradingCiscoUCSFrom1.4To2.0.html
Cisco Video Guide
http://www.cisco.com/en/US/docs/unified_computing/ucs/sw/video/upgrade/14to20/upgrade_20_a.html
As and when you want to go to 2.1 the upgrade guide and video can be found here:
http://www.cisco.com/en/US/products/ps10281/prod_installation_guides_list.html
Regards
Colin
I have a question about vPC in regards to UCS. In our non-UCS server environment a vPC is created Nexus side for each of our ESX servers with port channel set up accordingly on the ESX host side. With UCS servers attaching to 6200 fabric interconnects, is this still the method of doing it? Is it even possible?
Hi Brian
Yes absolutley vPC is supported and is infact the best practice. As if a link where to fail there is no re-pinning or Gratuatous ARPs that need to be sent out by the Fabric Interconnects in order to inform the upstream swicthes that the MAC address of you workload is now on the end of link “X” rather than the failed link “Y”
Just bear in mind that vPC is supported upstream, but the Fabric Interconnects are totally seperate entities and as such DO NOT support vPC or any other Multichassis Etherchannel options between each other.
So your setup would look like the below.
Also remember to set your Nexus ports to “spanning-tree port type edge trunk”
Regards
Colin
Regards
Colin
I was referring to vPC downstream, between the 6248 and an ESX host running on an UCS blade. Right now on our HP and Dell equipment I create a vPC on the Nexus 5k for the actual HP/Dell ESX host. So if there are 20 ESX hosts, then there are 20 downstream vPC’s set up.
Hi Brian
As the Fabric Interconnects are not connected to each other in anyway from a Data point of view (by design) you cannot create a vPC domain between them. You can however get the same outcome by creating 2 vNICs uplinks from your vSwitch/vDS in vSphere assign one to Fabric A and the Other to Fabric B in UCSM then Team them within vCenter, you just need to ensure you hash on Port Group ID. to ensure that VM’s don’t flap between fabrics.
Regards
Colin
Hello Colin,
first of all – thank you so much for what you’re doing, especially to give us an option to address any questions like that!
My question is related to Adapter-FEX, VM-FEX and Nexus1000v.
I’ve been reading about these features for days now. However, I got so confused now so I basically cannot identify what exactly the difference is between these features. Also, Is the A-FEX and SR-IOV the same thing? What exactly the Adapter FEX is anyway? I’d be very thankful if someone help me to finally understand it… I’ve been reading alot, really.. but I just got so confused now … 😦 Here is what I’ve learnt so far:
1. Adapter-FEX is an option to extend the FEX functionallity to the physical adapter card (VIC interface).
I don’t know if that option works with Fabric interconnects, because all the examples I’ve found was with Nexus 5k. But if that option is available on FIs as well – what’s the difference between A-FEX and VM-FEX?! (as in both cases the logical interfaces will apear as vEths on FI) Also, if we have FI with IOMs, we basically have few levels of FEX (from FI to IOM and then to the adapter itself?) If that’s true, is that mean we use different VM-TAGs to identify each interface (LIF/VIF)? Is the adapter now considered as VIFs?
2. VM-FEX and Nexus 1000v are mutually exclusive, since both are offering an alternative to VMware’s DVS (distribution virtual switch). Both are installed as “plugins” within the vCenters and should we decide to use the VM-FEX – all the vEths are created as logical interfaces on Fabric Interconnects (or N5K) where with N1Kv option all the vEths are extended to the VEM.
3. Nexus 1000v can work with A-FEX. But … Why we’d want to use that?
4. Is the Adapter/VNIC Creation (within the UCSM) related to any of these options A-FEX/VM-FEX? When we create a VNIC within the UCSM – do we use A-FEX to spawn an interface from the A-FEX functionallity or not? If so, is that mean that we always use A-FEX when we use Cisco UCS/UCSM?
I am telling you guys, It’s such a mess in my head right now .. Few levels of virtualization, few levels of FEX functionallity, … we create VNIC’s from the UCSM that will appear as VMNICs to the ESXi, and from these VMNICs we create another (port-groups) VNICs to provide the GuestOS… but these VMNICs (on the ESXi) can be delivered by A-FEX or SR-IOV … ahh.. I prefer to stop right here.. 😀
Thanks in advance!!
Hi Wand
Thanks for the Question, and your certainly not alone in your confusion, I teach this stuff and sometimes end up going down extreamly dark technical alleys with some of them 🙂
Fabric Extension (FEX) Technologies are subject to huge confusion, I think if Cisco had called it “Switch Extension” it would make more sense to people, but that didn’t abbreviate down as well 🙂
I’ll address your points by the number you have used.
1) Adapter FEX, you are right Adapter FEX basically extends the ports of the Controlling Bridge (The Fabric Interconnect in the case of UCS) into the Mezzanine Adapter. i.e. if you create a vNIC on the Cisco VIC, you will see a corresponding vEth port get created on the FI (They will have the same identifyer i.e if you check your UCS Service Profile VIF paths tab, you will see a circuit number assigned to your vNIC.
i.e Circuit number 999, if you were to ssh into the FI and do a “connect nxos” and a “show interface brief” you will see a dynamically created veth999.
So when you create a vNIC on your VIC in UCS Manager, a vEth is automatically created for it on the FI and they are joined together with a “Virtual Cable”, this relationship of the vNIC to vEth is called the Virtual Network Link (VN-Link)
These virtual cables are actually just a unique Virtual Network tag (VN-Tag) assigned to the traffic.
2) Nexus 1000v and VM-FEX: While on the face of it they seem to do the svery similar things, or at least address the very similar concerns i.e granularity of visibility/control to VM level, they are very different technologies and have very different use cases.
As a simple rule:
If latentcy is the greatest customer requirement, look at VM-FEX as inter-VM traffic is switched in the Hardware ASICS of the FI, think of each VM as plugging directly into the FI.
If Functionality and features are of prime concern and the customer has in house Cisco Nexus skills or the solution will be managed by someone who does, then Nexus 1000v will likley be the best bet.
I have re-posted a VM-FEX Vs Nexus 1000v Features table below.
3) If using Nexus 1000v on UCS on a host which uses VIC cards you are already using it in conjunction with Adapter-FEX as thats just how it works, i.e. the uplinks for the Nexus 1000v that you assign to each VEM have corresponding vEths created for them and are connected to the FI’s via VN-LINKs (see my description in answer above)
If you haven’t already check out my videos on VM-FEX http://ucsguru.com/category/vm-fex/
4) Yes this is Adapter-FEX see description of VN-LINK in answer 1
5) SR-IOV, the Cisco VIC uses very similar concepts to SR-IOV i.e. making a single Root Function (i.e Single Ethernet Port) appear as several seperate Ethernet ports (Virtual Functions), each with there own assigned resources etc.. this greatly optimises traffic movement between VM’s.
Anyway as I don’t work for Cisco, they won’t tell me what the technology behind the VIC is, but Cisco have told me it’s not SR-IOV but there own propriortory technology. (Probably SR-IOV dipped in Unicorn Tears 🙂
Anyway
Hope that Clarifys a few things for you.
Regards
Colin
VM-VEX Vs Nexus 1000v
Fantastic!!!
Thank you so much Colin for spending time on my questions and nailed it this way !!!
Yours sincerely,
Wand.
Hello, We have (2) C240 M3 that I want to connect into UCSM. We don’t have any 2232’s, but do have 6296’s and 5548’s. Can I connect the C240’s directly to the 6296’s? Also need to connect a NetApp 2240 the same way?
Thanks,
Boardman
Hi Boardman
That certainly used to be the way you would connect your C Series into the UCS Fabric Interconnects in the USCM 1.4 days but even then you needed a Nexus 2248 FEX for the 1Gb Management connectivity, however that was dropped I think back when 2.0(2) was released and support for the 2248 was dropped. Now you must must have a 2232PP FEX for C Series connectivity.
You still have a choice on using dual wire or single wire connectivity. If you use the P81E VIC or other supported CNA’s you need to run the 10Gb Dataplane and 1Gb Management seperatley.
If you use the VIC 1225 you are able to run single wire mode, where you only connect the VIC1225 and the Management connectivity runs over these links too (Side Band Management)
I have played about using Appliance ports to connect in C Series and other Types of servers, but that certainly isn’t what they were designed for and thus not supported.
I certainly would not be surprised if a future UCSM release incorporated support for single wire direct attached C Series, (we can but hope 🙂
Re your NetApp 2240 you certainly have direct connect options there, if using native FC or FCoE you would need to put your FI into “FC Switch Mode” and you if use UCSM 2.1 you now have the option to configure Zoning on the FI’s.
If your using File protocols like NFS then this is what you would connect to the UCS Appliance ports.
There’s a nice Cisco Guide which details all the options for NetApp Direct Attach Storage.
http://www.cisco.com/en/US/prod/collateral/ps10265/ps10276/whitepaper_c11-702584.html
Regards
Colin
Thank you for commenting….can you use 5548”s instead of the 2232’s?
Hi Boardman,
No the only option is 2232 FEX’s.
Regards
Colin
Hello, I tried to install ESXi 5.1 on UCS B200 M3 using the KVM, but it keep gives (no network adapter were detected)..I used Cisco custom image but it also failed. I updated the firmeware adapter to 2.1(1f) but that also didn’t help. If you have any idea regard this issue can you please share it. Regards,
Hi Aiham
That seems pretty odd, I have installed ESX 5.1 on dozens of B230M3 and have never seen this error.
Just to confirm that your VIC1240 is running ok, and that you have created the required vNICs in your Service Profile.
Also may be worth trying the Cisco OEM install of vSphere 5.1 which I have made available here.
Regards
Colin
is there any way i can put two data ports in to a one vlan and set another port into a management vlan?
Hi
I’m not sure exactly what your asking, could you please elaborate a bit more on what you are wanting to do.
Regards
Colin
Hello Guru, you have any doc or manual configuration of vmware vcenter in Cloupia, do the virtual data center but I do vcenter networks in the time to development, any ideas? , Thank you very much
Hi Dave
I haven’t had a serious play with Cloupia or UCS Director as it’s now called. I’ve stood it up in the Lab, but now it’s been re-named to have UCS in the title, it is certainly top of my list to learn.
In the meantime there is the Cisco Community Forum, which may be a better place to ask your question.
https://supportforums.cisco.com/community/netpro/data-center/unified-computing
Also have a check at http://www.cisco.com/go/ucsdirector for any support guides.
Regards
Colin
Colin,
Just got my hands on a few C240 M3′s with the VIC 1225 adapter and began setting them up as a VMware 5.1 U1 cluster. I’ve configured 8 vNICs per host: 2 for Management, 2 for VMotion, 2 for iSCSI, and 2 for VM traffic. Each pair of vNICs has one pinned to uplink 0 and the other to uplink 1. vNICs are set to trunk mode in the VIC since I am tagging multiple VLANs from VMware. The hosts are physically connected to a stacked pair of Cisco 4500-X switches; physical uplink 0 to one switch, uplink 1 to the other switch. Switch ports are trunked to allow the VLANs we plan to use. Portfast is enabled. VMware vSwitches using Source Port ID for Load Balancing and the vNICs are active/active for Management and VM traffic. No port channel or Etherchannel is configured on the swtiches.
After creating a VM for vCenter and joining the hosts to it, I started migrating existing VMs from an old cluster and saw odd network behavior. It seems whenever a VM or vmkernel interface are on any vNIC pinned to the same physical uplink on the same host, they can’t talk to each other.
Example: VM1 and VM2 are on host 1. VM1′s network adapter is pinned to vNIC1 using VLAN 10 which uses physical uplink 0. VM2′s network adapter is pinned to vNIC2 using VLAN 10 which uses physical uplink 1. VM1 and VM2 can ping each other. If I move VM2′s network adapter to any vNIC that uses physical uplink 0, just like VM1, then VM1 and VM2 can no longer ping each other. Or if host 1′s management IP is pinned to vNIC 1 on physical uplink 0, any VM on host 1 using a vNIC also pinned to physical uplink 0 cannot ping the host.
Any ideas?
Thanks,
Mike
Hi Mike
Thanks for the question, sounds a fun one to troubleshoot.
Hope I understand the issue.
Great that you can isolate the issue only a single host as that simplfies things.
I would expect 2 VM’s on the same host and same VLAN to communicate over the vSwitch and not even use the uplinks.
I’m not huge on cli troubleshooting the standard vSwitch but I know you can use scripts or commands like vsish as a way of viewing the MAC-Address table on it.
Have you tried making the uplinks Active/Standby just to see if that makes any difference.
As I’m sure you know the vSwitch has protection mechanisms to prevent traffic looping back on its self (DeJa-Vu and RPF Checks) though I very much doubt any of these are causing your issue.
My feeling is that it’s likley a VLAN configuration issue somewhere,
I would start, bu double checking all pNICs and vNICs are configured correctly and have the correct VLANs tagged.
Check MAC-Address-Tables on vSwiches if possible but may just be easier to stick Wireshark on both VM’s to check if ARP’s etc.. are being sent/seen.
Please feed back how you get on.
Regards
Colin
Should have been clearer…. this is happening to all hosts and if the VMs are in the same port group, vSwitch, and host then they can communicate fine since traffic never has to go to the 4500-X’s.
I first noticed the issue when I had the vCenter VM in a port group on vSwith3 which used vNICs 7 and 8 in an active/active config. The vCenter VM could not ping the management IP of the host it was running on but could ping the other two hosts in the cluster. Management vmkernel was on vSwitch0 which used vNICs 1 and 2 active/active on the vSwitch.
Confused, I created a port group on vSwitch0 using VLAN 10 (VM’s and VMware Management both use VLAN 10) and then the vCenter VM could ping the host’s management again. However, I then noticed vCenter could no longer reach the domain controller VM which was running on the same host but back on the port group vCenter used to be in — vSwitch3 on vNICs 7 and 8.
So the issue rears its ugly head when an IP on a host (VM or vmkernel) is in a different port group and vSwitch, but has to talk to another IP (VM or vmkernel) that is using the same physical uplink. If VM1 is on vSwitch3 and VMware has VM1 currently pinned to vNIC7 on uplink 0 and that VM has to talk to the management IP of the host it’s running on which VMware has pinned to vNIC1 on uplink 0, then the two IPs cannot talk.
We’ve checked VLANs and that all seems to be fine on the switch side.
As a stop gap I’ve pinned all hosts Management vmkernel to physical uplink 0 and VM port groups to physical uplink 1. Now there are no issues with VMs and host management IP talking, nor with vCenter talking to the domain controller since they’re in the same port group/vSwitch.
The issue seems to be that the 4500-X’s refuse to switch a frame back down the same physical uplink it arrived on.
Thanks!
Update: Cisco support essentially told us that using vNICs from the VIC 1225 connected to a Catalyst will work but only if you’re properly pinning traffic on uplinks. In order to use full active/active like you would on the B-Series you have to connect the VIC 1225 to a Nexus switch. To circumvent our issue we’ve placed vCenter in its own port group on the same vSwitch as management to ensure they can always communicate, then pinned both to a vNIC on physical uplink 0. We then pinned all other VM port groups to a vNIC on physical uplink 1. This will ensure vCenter can always talk to the host and it can reach the virtualized domain controller should they happen to be on the same host together.
Thanks for the help!
Im really interested too 🙂 What are the configuration on your vswitch / portgroup , i mean in terms of the policy exceptions and teaming tab when you hit properties ?
Also is that the only host experiencing this issue? if yes, id suggest create host profile from a working host and test against this one?
Hello Guru,
We experienced a fault today, and saw the error message in the UCS Manager GUI at the time, but did not archive it. When I checked back in the GUI later the fault was gone. Alas I learned that we have our system configured to delete cleared faults after one hour. I’ve fixed that now 🙂 However is there any way to view the cleared/deleted faults again ?
I posted this question to the Cisco forum too and was told that this is not possible. Syslog should be used for this (which we had configured but is not working for some reason).
Thanks. …Brian
Hi Brian
No way that I know of, if it was one of the Cisco menbers that responded to you on the community forum (Padma / Robert Burns etc..) then take that as gospal as they are real smart Cisco UCS Cookies!
Get that Syslog working! 🙂
Colin
Hello…
I’m currently working with the UCS emulator prior to getting out to a job site. While following along with the instructors video for adding devices inside of the “Startup Inventory” area, I’m noticing that I’m being asked about “slot id’s” after I add components, such as a fan, whereas the video instructor is not (i.e., “Fan slot id must be a range in the format [a-b]”).
Any ideas as to why I would be asked this?
Thanks.
Jay
Hi Jay
I am a regular user of the UCS Platform Emulator, but must admit I’ve never watched the Instructional Videos for it (Assume you mean official Cisco Videos) If you are seeing a difference in what the video details and how the actual UCSPE acts. I would confirm that the videos you are watching is for the same version of the UCSPE you are using. If it is worth buzzing Cisco and letting them know.
You could always ask one of the UCSPE Developers (Eric Williams @aeroic78) why this might be.
Regards
Colin
Hi I have ucs 24 m3 and integrated with UCSM 2.1d I am trying to change some bios settings in the server for the option rom / PCIe setion to “disabled’ but it will not let me select it to make any changes.. There is nothing like this in the policies either.. Any suggestions?
Hi Pete
Have you tried whether you can access the BIOS directly? i.e. stick a Monitor/Keyboard on the server and hit F2 at boot time?
If you can’t even do the above, it is possible (though unlikley) that you may have a corrupt BIOS, in which case the BIOS Recovery option is in the below doc, but I would enage TAC first to confirm.
http://www.cisco.com/en/US/docs/unified_computing/ucs/c/hw/C24/install/install.html#wp1318669
Regards
Colin
@Colin
Thanks for the response however I think i may have not been clear. The issue I am having is not a corrupt BIOS. However what I just learned is that the availability to perform what i wanted to do cannot be done until UCSM 2.2.
I can get into the bios fine however there are some “optionrom” settings I wanted to disable however they are not able to be selected and are enabled.
Here is the email response I got from a tac this morning:
——————————————————–
Hi Pete.
The functionality you are looking for does not current exist with our current implementation of C-series integration.
The functionality you are looking for is expected to be available after a major UCSM code release late this fall, and will ‘probably’ be called UCSM 2.2
Hi, We have a Cisco UCS 5108 Blade Chassis and a few weeks ago the PSU was replaced. Our monitoring software is still detecting a fault ‘overall status is not operable – chassis 1/psu 3). All the status details on it are reporting ok Operability OPERABLE, power ON, Voltage OK, Performance OK, Thermal OK, Presence EQUIPPED..all apart from overall status is powered off- any idea what I need to do to clear this please? Many thanks.
Hi Stuart
You mention its your monitoring software thats still reporting the issue, are you still seeing any errors reported by UCS Manager?
If so whats the Error code?
Regards
Colin
Hi thanks for your prompt response. Only evidence of an issue is the Overall Status is saying powered off – nothing else showing anywhere else to suggest a problem.
Dear guru,
i have a issue with one of the nexus 5 k…i have configured ucs and i wanna configure uplink with nexus 5 k…from ucs i have configured the port has uplink do i need to configure nething on nexus 5 k which is connecting to core switch..im gettting a error on ucs …NPV UPSTREAM PORT NOT AVAILABLE ..
pls advice
Hi Sameer
I assume you are refering to using the Nexus 5k as a Fibre Channel storage switch, as that error indicates that there is a fibre channel issue some where.
I would first check that NPIV is enabled on the N5K (Feature NPIV) if so Check that the VSAN ID’s match at the Nexus 5K side and the UCS Side.
Also it may sound silly confirm you have indeed connected a Fibre Channel port on the FI to a Fibre Channel port on the N5K.
Regards
Colin
Hi Colin,
Great blog, great content, not sure where you find the time. My question is on the B200 M3 blades. According to the spec sheet, you must have the VIC 1240 mLOM installed in order to use the VIC 1280 in the Mezz slot, otherwise you have to use a Q-logic or Emulex CNA in the mezz slot. I was under the impression that by going with a 1240 + 1280 config you have redundancy in case one of the VICs were to die. However reading that you must have the 1240 installed in order to use the 1280 leads me to believe that if the 1240 died for some reason, then that would render the 1280 useless. Can you confirm one way or the other?
Thanks,
Frank
Hi Frank
Thanks for the compliment, finding time for this blog is always a huge challenge, but very rewarding as it keeps me sharp and gives me a great idea of what people are trying to do out there!
I’m with you on this, the release notes do not make this particulally clear. So to Clarify
You CAN use a VIC1280 in the Mez slot on it’s own in a B200M3 as the mLOM is completely optional. However in this configuration you will only get a maximum of 20Gbs per fabric per server, as 2 of the 4 x 10Gb traces from the IOM go to the mLOM slot.
You CAN use the VIC1280 in conjuction with the VIC1240 in order to get your full 40Gbs per fabric (if also using the 2208XP IOM). The VIC1280 will continue to work just fine, if the mLOM was to fail, and vice versa i.e. the mLOM would continue to work just fine if the VIC1280 failed. So as you say this provides a level VIC redundantcy. The only impact would be the reduction in bandwidth by 50%. And potential loss of any Dynamic adapters on the failed VIC if using VM-FEX.
The reality of it, in my view as a non Cisco employee, is: Of the thousands of VICs I have implemented I have never seen one fail. And in the M3 range I always spec up the mLOM and if additional bandwidth is required then I spec the port-expander. And as you know the port-expander is certainly “dead in the water” if the mLOM was to fail.
In my view the simplicity of the port-expander is preferable to the VIC1280/1240 combo, as the VIC1240/PEX Combo is one logical adapter rather than 2 physical ones i.e. The VIC1280/1240 combo would need vNICs/vHBAs created and assigned to each of them to provide the redundantcy you mention.
While the mLOM in a mLOM/PEX combo may be viewed as a SPOF, as mentioned I have never seen one fail and as it’s just a PCB, you may as well say the motherboard is a SPOF. And generally redundantcy for workloads is provisioned higher up the stack. i.e. clustering, VMware HA/FT etc..
But if Host availability is of primary concern then of course the option is there to use the VIC1280/1240 Combo.
Hope that all makes sense, if not fire back.
Regards
Colin
Hello, is it possible to manipulate t ESX in that way that it is able to recognize the embedded Software RAID from a UCS C220M3 (i know that in the Installation Guide Cisco said that this is not possible)?
Hi Michael
I have never seen or heard of anything that will do that, ESXi will only see the resulting configuration of what you have done on the RAID (i.e the Logical drives)
Regards
Colin
Hope I am writing this in the correct place:
Building RAC clusters with UCS and it appears the cluster interconnect network has a keep-alive enabled. Can it be disabled for specific IPs?
Hi Daniel
Funnily enough I spent last week specing UCS based systems as an preferable option to seperate Exadata and Exalogic systems and combining them in a single high performance UCS Intergrated System.
Anyway.
The Cluster interconnect between the 2 Fabric Interconnects is only for state syncronisation and keep-a-lives between the 2 FI’s themselves, Not for hosts. No user data ever traverses these links.
Hope that answers your question.
Regards
Colin
Hi, Colin. I have a question. I just installed 2012 on a UCS blade. The install went smooth. However, when I go into the OS, it sees the NICs and HBAs, but it looks like the drivers aren’t installed. Therefore, it doesn’t see the network. I checked the managment console, and the NICs are definitely there. What drivers do I need to download to get 2012 to recognize the UCS HW?
Hi Tony
You will need to download the Cisco UCS B Series Drivers ISO from Cisco.com
ucs-bxxx-drivers.2.1.3.iso
Mount up the ISO in your W2K12 Server either using Virtual Media via UCS Manager KVM Laucher, or an inband ISO mount util (I use virtual clone drive)
Then just update the NIC drivers using the path Windows>Network>Cisco>MLOM>W2K12>x64 (If using the MLOM, or Windows>Network>Cisco>VIC1280>W2K12>x64for VIC180)
While your at it also launch the setup script in the Windows>Chipset folder to install other relevant drivers.
If you want to create a Windows NIC Team you will also need the utils ISO
ucs-bxxx-utils-windows.2.1.1c.iso
Regards
Colin
Hi, Does anyone have a Cisco UCS Memory Installation guide for Mixed memory, I’m planning to upgarde 20+ UCS Blades (Cisco UCS B200 M2) with mixed memory modules and cannot find a comparison guide anywhere within Cisco.com.
Thanks
Alan
Can QoS be configured on a FC port-channel between the FI and an upstream N5K or MDS? i.e. Can we guarantee a certain FC bandwidth within the PC to a single, or multiple blades? Alternately if we have to use FC pin groups to pseudo achieve this, how does the traffic flow if the port in the pin group fails?
Hi,
I have a question regarding LAN pin groups which I haven’t been able to find the answer to.
Suppose I have a UCS with FI-A and FI-B, where each FI is connected by one uplink (U1) to the LAN.
What would happen if I created a LAN pin group (PG1) utilizing only U1 on FI-A and then created a vNIC and assigned it to FI-B but using the LAN pin group PG1. I would have a vNIC belonging to FI-B but associated with a pin group selecting U1 on FI-A.
I tried to figure it out by using our demo equipment, but I’m not allowed to play around too much. I created the pin group and then a vNIC-template, and UCSM didn’t complain anyway. I guess the users might though..
Tank you!
Best regards, Clayton
Hi Clayton
Thanks for the question.
Firstly appologies for the time its taken me to reply, your question seems to have slipped through the net after my holiday.
Ok to answer your question, there must be a valid uplink carrying the correct VLANs for that vNIC, if not the vNIC will not come up.
If you were to do as you suggest, assign a vNIC mapped to Fabric B to a Pin-Group that only had uplinks on Fabric A you would get an F0841 error telling you that the Pinning Target for your Eth “x” on Service Profile “Y” is missing or misconfigured.
Your vNIC would then default to Dynamic Pinning, and as long as there was a suitable uplink available on that fabric the vNIC would get pinned and come up. The F0841 error would remain until you either removed the vNIC from the Pin-Group or added a valid Uplink to the Pin-Group.
Regards
Colin
Hi,
Is it possible to connect a USB 3G cellular modem to the UCS?
Thanks!
Hi Meir
As far as I know the only supported internal USB Devices are Cisco USB 2.0 Flash Sticks.
Regards
Colin
Where is the “Management IP Pool” option found in the latest version of UCSM? In the older version, it was found under the “Admin” tab followed by being listed under the “Communication Management” section.
Thanks.
Hi Jay
The “IP Pool-ext-mgmt Pool” as it is now called can be found under the LAN Tab>IP Pools.
Regards
Colin
Here is the scenario:
1xB200 M3 with 1240+1280 card. (on UCSM I can see 4 DCE per VIC). 40GB per slot per chassis.
Traffic needs to be categorized as following:
Vnic1-Fab A VIC 1240 NIC Team Bronze VM data 50%
Vnic2-Fab B VIC 1280 NIC Team Bronze VM data 50%
Vnic3-Fab A VIC 1240 NIC Team Silver FC 40%
Vnic4-Fab B VIC 1280 NIC Team Silver FC 40%
Vnic5-Fab A/B VIC 1280 Fabric failover Gold vmotion 10%
Here is the question, is this percentage per DCEs? per adaptor? so how does vmotion traffic will be treated?
note that vmotion is on vNIC5 on adaptor 2 but “Gold” class is system wide parameter( I guess per both adaptors?) My question is this 10% will be reserved from what location (which adaptor)?
I have a hard time understanding while QOS config is global, how this is performed on 10GE vNICs while we could have say 5 10GE vNICs on 1240 card which only have real capacity of 40GB.
Or if its per DCE ,I think it is , how does UCS act base on above scenario , asymmetric vNIC distribution, what will happen if it failsover (vnic 5 vmotion) ?
I couldnt find an answer for above anywhere, let me know whats your thoughts on this.
Hi Jeremy
Agreed not too much info as to how exactly this works when multiple 10Gb “lanes” are utilised. And I’m not 100% sure either.
But My view would be that as each vNIC/vHBA has a correponding vEth/vFC at the fabric Interconnect. And these virtual ports inherit the QoS policy associated to the corresponding virtual adapter.
Along with the fact that these vEth/vHBA ports are aware of the ammount of 10Gb Traces (KR Ports/ UIF) which are “lit up” i.e in your case your vNICs/vEths should report as 40Gb interfaces.
The the %’s allocated via the QoS Policy will be representative of the bandwidth available to that vNIC i.e 40Gb in your case.
Things to bear in mind:
The multiple 10Gb KR ports are channelled in hardware (various combinations depending on your MEZ selection) thus any one FLOW will be restricted to 10Gb, as the VIC distributes across the KR Ports based on flows.
Traffic will only “Compete” for the same bandwith if mapped to the same Fabric (Obvious I know)
Anyway just my 2cents.
Next time I speak to TAC I’ll see if they have a nice WP on this. Or I know some Cisco TAC Gurus follow this blog so feel free to input.
Also while only dealing with Gen 1 UCS Brad Hedlunds QoS on UCS post is still worth a read.
http://bradhedlund.com/2010/09/15/vmware-10ge-qos-designs-cisco-ucs-nexus/
Colin
Hi Colin,
Can I install VMware Standard (Essential kit for 3 serves) and use that with VM-FEX ?
I don’t need DS, vswitch is ok for me.
If I can’t use VM-FEX, can I use just static vNICs for VMs ?
There will be 5-10 VMs on ESX.
I’m going to order VMware Essentials kit.
Is there any issues with that ?
Thanks
Hi Sharka
As VM-FEX utilises the vDS functionality within vSphere I’m affraid your gonna need Enterprise Plus license if you want to use VM-FEX or Nexus 1000v
Colin.
When using a modern hypervisor like vSphere 5.1 or 5.5, and Enterprise + licensing, what’s the current thought around the number of pNICs presented to the distributed? I’ve read VCE presents only the two 10Gb pNICs then uses NIOC/Load Based teaming to handle bandwidth control. Kendrick Coleman mentioned this on his blog.
In the past others like Brad Hedlund presented 8 virtualized NICs to the distributed switch, and configured UCSM to handle bandwidth control/QoS. From what Kendrick said vSphere doesn’t know about the real phyiscal NIC load when you virtualize NICs with UCSM (since SR-IOV isn’t used), so the load balancing based on NIC load isn’t aware of the real NIC load.
The more modern approach (with NSX/SDN on the horizon and increasing vDS features) seems that presenting the two 10Gb pNICs and using vCenter vDS to control BW, and matching that up with UCS QoS classes is the way to go.
Thoughts?
Hi Robert
As you rightly point out there are several views on this, probably due to the fact that there is no ONE right answer. The number of pNICs you assign to the vDS or to the host for that matter will depend on a few things namley.
Bandwith requirements
Fault Tolerance
Traffic Patterns (local FI switching or upstream)
Traffic seperation (to different/non-contiguous upstream networks)
Some customers like there UCS Servers to have the same uplink config and there Physical Servers.
Some customers prefer leaving management and/or vMotion on standard vSwitches.
QoS / Weight requirements (easy to assign to different pNICs)
Comfort factors with vSphere QoS / Traffic shaping Vs Cisco UCS methods
Once you discuss the above requirements with your client amd the pros/cons you will have the solution that best suits your client, the important thing is to have all the above “arrows in your quiver” and be able to use the right ones for the circumstances.
Tradional thinking was to use a separate pNIC (or pair of pNICs if fabric loadbalancing was desired) for each use case i.e Management, vMotion, iSCSI etc.. this may well still be valid as it is easy from the UCS point of view to define the correct QoS / MTU etc.. to these different pNICs.
With the native vSphere vDS you could only assign one pNIC (not sure if 5.5 changes this) so my preference is to use the Nexus 1000v which allows multiple pNICs to be assigned to the N1kv and to split all the required traffic out logically. (Whether to use the vSphere vDS or N1kv is another matter for discussion with pros and cons to each)
In Cisco’s best practice white papers they do now lean towards providing a single pair of pNICs (one Fab A one Fab B) to the N1kv, but again its only there suggestion as it greatly adds simplicity.
Last time I checked the VCE Logical Build document, they were still creating seperate pNICs for certain traffic vMotion for one, but this may have changed.
And re SDN particulally NSX, NSX has its own traffic seperation requirements as I am sure will most Overlays. I know Brad recently posted his view of how NSX should run over Cisco UCS http://blogs.vmware.com/networkvirtualization/2013/09/vmware_nsx_cisco.html#more-456
Anyway great question, sorry I couldn’t give you a nice clean answer, but then again I’m sure you never really thought there was one 🙂
Regards
Colin
Colin, thanks for the reply. I’m a little confused about your VDS and pNIC comment. The vDS can easily support multiple pNICs, like the N1K. I do need some clarification regarding how QoS works when using the vDS to do the marking, and UCS is also configured for QoS. My understanding is if the VMware vDS does QoS marking (NIOC enabled) that UCS will respect those tags (“host control=full”), and put the packets in the proper queue throughout the UCS data path (NIC, IO module, FIs).
However, during some testing I found an interesting situation that calls my assumption into question. Setup:
QoS System Class: Priority-Best Effort, CoS-any, MTU 1500
QoS System Class: Priority-Silver, CoS-2, MTU 9216
QoS Policy: Priority-Best Effort, Host Control = Full
If I assign the QoS policy to a pNIC and use the VDS to mark vMotion traffic as CoS 2, vMotions fail with MTU 9000. vMotions work with MTO 1500. My assumption was that the VDS would mark vMotion traffic CoS 2, so the Silver MTU would be applied and all would be fine. That’s not the case. If I change the ‘best effort’ priority to MTU 9000 then vMotions with MTU 9000 work.
When configuring the QoS policies my assumption was that all CoS tagged traffic would be applied to the proper UCS priority, and unmarked traffic would not get tagged since ‘best effort’ is not tied to a specific class in the QoS system policy.
This situation calls into question the CoS marking and honoring when using the VDS and UCS. Does that make sense? The Cisco documentation is fairly unclear so maybe I’m making wrong assumptions.
Hi Colin,
first of all thank you for providing such a great informational blog and sharing your knowledge! I had a lot of visits to your blog in the last couple of months.
I’m curious to know, if you see any possibility getting a 6248up FIC into disabled npv mode but still end-host-mode, or in other words, connecting a 6248up FIC to an FCoE Switch, which does’nt provide support for npiv.
Thanks,
Mike
Hi Mike
Thanks for the kind words
Certainly not a possibiliy, you only have the 2 options: NPV mode (default) or Switch Mode.
Which upstream switch are you using? as most I have seen support NPIV.
If it doesn’t support NPIV then FC Switch Mode is your only option.
Colin
Hi Colin,
I see strange behavior of IQN pools. I created iqn pool for esx servers:
prefix: iqn.2013-09.com.esx
iqn suffix: srv-esx, from 1, size 3
I.e. there should be IQNs: iqn.2013-09.com.esx:srv-esx1 … iqn.2013-09.com.esx:srv-esx3
But as I see, UCS created IQN suffixes as: srv-esx:1 … srv-esx:3
I.e. initiator name will be as: iqn.2013-09.com.esx:srv-esx:1
My NetApp storage doesn’t accept this initiator name with double ‘:’ in the name.
UCS 2.1(1e).
Is it a bug ? Can you please check and ask Cisco ?
Thanks
Fixed. Done via CLI. It seems it’s NetApp onCommand System Manager issue.
Can any one tell which would be the best suited drive for boot from SAN. Is that EFD (Flash drive), FC drive or SATA drives.
How would I connect 2 different UCS Domains (4 FI in total, 2 in 1 site 2 in a remote site) the 2 site are connected through 10GB fibers. I have 2 seperate UCS domains for Site failover. (San is already replicated to each site and that portion work fine)
Thank you
Hi Joseph
This would be a job for UCS Central, (Free to use for under 5 Cisco UCS Domains)
http://www.cisco.com/en/US/products/ps12502/index.html
Regards
Colin
Hi there,
I have a question about UCS and FCoE – I don’t have a solution for my problem 😦
I configured UCSM 2.1(3a) with a FCoE Uplink, default vsan, fcoe VLAN 99 – and the upstream nexus 5548up (nx-os 5.1.3) with npiv and fcoe features – everything works fine except end to end connectivity. My virtual HBA has done the flogi perfectly, but in the fcns the fc4 type is missing so I can’t reach storage or other things. fcping works but thats all – no other connectivity.
The Blades are B200 M3 with VIC1240, all firmware from new 2.1(3a) release. Zoning seems to be correct, system qos settings are fine on my 5548 but now im running out of ideas.
Do you have an idea?
I tried restarting the blades / fi’s but nothing works.
Best regards,
Dennis
Hi Dennis
If you are seeing all the WWPNs in the fabric (Initiator and Targets) and your Zoning is all correct (Check to see you see an * next to each WWPN, when you do a Sh Zoneset Active)
And your masking on the array is all correct.
I would be inclined to run a debug on the Nexus SAN Switch to see exactly whats happening (or not) “debug fcns events register vsan 1”
this command is detailed in the MDS Trouble Shooting guide most of which is still relevant to Nexus
http://www.cisco.com/en/US/docs/storage/san_switches/mds9000/sw/rel_3_x/troubleshooting/guide/trblgd.html
If you are still having issues I would suggest contacting TAC.
Regards
Colin
Hi,
I have a problem when i did a acknowledge chassis 1 i ve lost my FC path to my storage ( boot san )
so it’s a big problem… to go back to an initial state i have to rescan all datastore fc path on each esx host, can you give me an idea of what can be the root cause ?
In details i have 2 fabric with one vsan on each, 2 chassis 4 link between IOM and Fabric chassis discovery policy is 2 link. and I have 2 vhba on each ESX host.
check my cabling here ( 1st design) https://community.emc.com/message/759696?et=watches.email.thread#759696
thanks for your help
Hi Macihh
When you Re-Ack a Chassis all of your vNICs and vHBAs for both Fabrics will offline for approx 20 seconds, this will mean that your hosts would loose connectivity to their disks during this time, which has almost certainly caused your issue.
Re-Acking a Chassis should only really be done in a maintenance window especially in a Boot from SAN production environment. Best to shutdown the servers then do the Re-Ack.
You should only really need to do a Re-Ack if you change the number of FEX to FI links for a Chassis.
Colin
Hi Colin,
Thanks for hosting a great website. It provides heaps of useful information to newbies like me. Even though I have experience in implementing VMware for sometime, I am reasonably new to UCS. I have implemented boot from SAN with iSCSI and the blade’s initiator is seeing the target (NetApp) fine. Once the installation of ESXi (5.1) finishes it restarts and when it boots back up gives this error message:
BANK5: not a VMware boot bank
BANK6: not a VMware boot bank
No hypervisor found.
VMware has a KB relating to this but it doesn’t fit our scenario. (http://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=2012022)
Do you have any idea what the issue might be? I have checked the service profile configurations and also have checked everything I could from the NetApp side as well.
Hoping you would have come across this at some stage.
Thanks,
Ranjan
Hi Ranjan
Certainly not an error I have come across before, I like you found many references to this but all pointing back to that KB article.
Which indicates a partition issue with the Datastore. Sounds like one for TAC.
But please update this thread once you resolve the issue.
Regards
Colin
Hi Colin,
Thanks for your response. After wasting a lot of time with it, followed an advise from one of the forums and changed the MTU of the iSCSI vNIC from 9000 to 1500 and it worked.
Same issue with booting a Windows blade from SAN (one of my colleagues was working on it) it wouldn’t go past after selecting the disk for installation. After spending a lot of time trying to inject the correct drivers it came down to the same MTU issue. Really strange but that’s the only way we could get it to work. All the other MTU values along the path remained on 9000.
Regards,
Ranjan
Hi this is a basic question. In a lab environment I am setting up a UCS chassis to (2) 6240 FI’s and the uplink is going to (1) FEX 2232PP that FEX has 4 uplinks 2 to each 5596 switch. This setup seem ok or is a second FEX required? The two 5506’s havea heart beat link between them again this is for a lab situation
Hi PL
If both your FI’s are up linked to a single 2232PP FEX, then that is obviously a single point of failure. Probably fine as this is just a Lab environment but not recommended for a production environment. In which case you would either want to add in the 2nd FEX or bypass the single FEX you have and uplink the FI’s directly into the Nexus 5596’s using vPC.
Regards
Colin
Dear sir I kindly ask you for help. I have 2 Cisco UCS C220 M3 with P81e card and two Nexus 5548UP. Can I use these cards for Ethernet and FC traffic, on Vmware virtualization Platform without distributed switch. Only with Vmware Esentials Plus Kit?? Thanks.
Best Regards
Horatiu
Hi Horatiu
Yes, absolutely if your happy using standard vSwitches.
Colin
Hy thks for your response. I prefer to work with dvs or 1000v but in public auction the price make difrence. Thks a lot.
Hi Guru,
I have been following your blog regularly since I started my work on UCS.
I have a question on HA in UCS FI.
My requirement is to have the FI across different data halls, but as the limitation of span of ethernet LAN cable which will connect between L1 and L2 i have this limitation.
Just thought over this, what if I configure the UCS and then after the initial implementation for cluster then If I move the FI across the data halls disconnecting the L1 and L2 cables, does the EEPROM will help the UCS FI still work on HA.
I don’t know if this a dumb question, but this is what I am trying to achieve.
Cheers,
Sandeep
Hi Sandeep
I really would not advise trying to split a UCS domain between Data Halls, in addition to your L1/L2 restriction you would also need to cable every chassis back to both FI’s which would lead to a cabling head ache, far better to have a separate UCS Domain in each Data Hall.
Colin
Sure Thanks Guru for your reply.
I’m using vSphere 5.0 DVS with UCS. My model is presenting the two pNICs to the DVS, then use DVS CoS tagging and UCS system QoS classes. The vNIC template uses ‘best effort’ as the default class. On the DVS I’m using CoS tags 1 (mgt/VR), 2 (vMotion), 4 (IP storage). No FT. Should I set a CoS tag of 0 on the DVS side for VM traffic, or just leave it untagged and have it fall into the ‘best effort’ default bucket at the vNIC level. Does it matter?
Hi Robert
I usally only set the QoS within UCS Manager i.e. on a per vNIC level. If you want to have differing QoS/CoS levels within a vNIC i.e your DVS uplinks will multiple port-groups behind them then of course you can use the vSphere CoS tagging and set the UCS QoS policy for that vNIC to “Host Control”
If you are using the Nexus 1000v, then you could have a different pNIC for each of your Port-Groups and go back to just using UCS vNIC based QoS.
The definitive UCS QoS post is still this one so worth having a read.
http://bradhedlund.com/2010/09/15/vmware-10ge-qos-designs-cisco-ucs-nexus/
Regards
Colin
Colin,
A question on QoS and adapter policy on vHBA. Currently, QoS policy and adapter policy arenot set on vHBA. If we were to apply QoS policy and adapter policy, do we need to reboot the blade?
We have B200M3 blades running ESXi. Firmware is 2.11b and adapter is VIC 1240
Hi Charan
Changing/Setting the vHBA Adapter Policy, QoS Policy or Stats Threshhold Policy does not require a blade reboot. (I Just changed all 3 on a running ESXi Server)
Regards
Colin
Just want to thanks for your reply hope you the best !
I have a Cisco B420 M3 server. It has a VIC 1240 and a VIC 1280 and 2208XP IO Modules. 8 NICS and VMware on the blades. 8 NICS, 4 show up as 20GB in the vSphere Client and the other 4 show up as 40GB. It is my understanding that they should all up as 40GB, is that correct? If so, why would they be showing up as different speeds? Any ideas?
Hi Carl
The reason for this is the VIC1240 and VIC1280 are seperate adapters, so any vNIC mapped to the VIC1240 will show up us a 20Gbs vNIC and any vNIC Mapped to the VIC1280 will show up as a 40Gbs vNIC.
The Speed of the vNIC as detected by the OS (ESXi) is determined by the bandwidth of the UIF Interface. The UIF Interface is the Hardware Port-Channel of the Multiple 10Gb Traces (KR Ports) between the VIC and the FEX.
If you read my post on B200M3 Architecture (entitled 20Gb + 20Gb = 10Gb) you will see that these hardware port-channels form differently in different combinations of Adapters and MEZ cards.
For example a VIC1280 will have a single 40Gb Port-Channel (4x10Gbs) for each Fabric and thus vNICs will report as 40Gbs whereas a VIC1240 will have a 20Gbs Port-Channel (2x10Gbs) to each Fabric and its vNICs will report as 20Gbs.
If you want all of your vNICs to report as 40Gbs, you have a few options. Easiest this to do is to add a port-expander to effectivley turn your mLOM VIC 1240 into a VIC 1280. thus whichever adapter your vNICs are placed on they will report as 40Gbs.
Hope this all makes sense, as mentioned have a look at the B200M3 Post as the diagrams will make this a lot clearer.
Regards
Colin
On a 6296 interconnect firmware 2.1 can I connect NetApp 10G network link directly using appliance port for NFS…Or is my only option to use SFP or FCOE?
dear guru,
im getting this error message in all blades…after every few seconds.
successfully restored access to volume 51790c55-csfq5df following connectivry issues
lost access to volume , due to conectivity issues. recovery attempt is in projess and outcome will be reported shortly
its disconnect and connects in less then a second..
would u pls advice me on this
Hi Sameer
I’ve not seen this error myself, but I did find reference to this message on an EMC forum as below.
Hope it points you in the right direction.
Regards
Colin
“It was found that the frames were being delivered to the array out-of-order and when that occurs, the array drops the frame. Once in-order delivery was enabled on the Nexus the problem stopped. We can see in the spcollects in the ktrace log the “OOO” listed as an error. When you see those, there are a cople of problems – usually a bad SFP on the switch or this new one with the Nexus. Customer was also using VAAI which seemed to make the problem worst.”
Hi,
I’m on 2.0(3a). Is it at all possible to configure the UCS for VM-FEX, or is going up to a later firmware my only option?
Cheers
Hi Stan
VM-FEX for vSphere is supported from 1.x so you are fine with 2.0(3a), There are lots of cool new features in 2.1 so you may want to consider an upgrade at some point anyway.
http://www.cisco.com/en/US/docs/unified_computing/ucs/sw/vm_fex/vmware/gui/config_guide/2.1/b_GUI_VMware_VM-FEX_UCSM_Configuration_Guide_2_1_chapter_01.html
Regards
Colin
I should have mentioned, this is for Hyper-V. Specifically, Step 11 under Creating a Service Profile for VM-FEX for Hyper-V from http://www.cisco.com/en/US/docs/unified_computing/ucs/sw/vm_fex/hyperv/gui/config_guide/2.1/b_GUI_Hyper-V_VM-FEX_UCSM_Configuration_Guide_chapter_011.html#task_943280F652F648B69A74A556B24C4574 doesn’t seem to be available in 2.0(3a). As such, I’m unable to assign a Dynamic vNic Policy to the first pfNIC.
Hi UCSGuru,
I have a question on the re-acknowledging of the chassis in UCS – If I’m using 4 server ports from FI to the chassis (40Gbps) but need to free up two of those ports in FI. If I simply disable two of the servers ports in FI, do I need to re-ack the chassis or it would automatically detect the removal and adjust bandwidth to 20Gbps and I don’t have to re-ack the chassis?
Thanks
Badri
Hi Badri
If you were just to pull 2 cables out the system would detect that 2 links have failed and warn you accordingly. Depending how the system is setup would determin how the system deals with this condition.
If you are in Discrete Pinning mode (Default) the blade slots that are mapped to the “Failed” links will failover to the other Fabric, if you have also removed the respective links from the other Fabric then the servers to which those links were pinned will lose connectivity until you Re-Ack the chassis.
If you are using Port-Channel mode the Servers will continue to use the remaining links on the port-channel (no fabric failover occurs).
But you would see a “failed links” type error in UCSM until you did a chassis Re-Ack. (remember this is distructive to connectivity for about 30 secs so only do in a maintainance window)
Regards
Colin
Hey Colin
This is a blast from the past. Keep up the great work. Makes me feel proud to have worked with you
Gurmakh
Hi Gurmakh
It certainly is hope you’re doing well. 🙂
Colin
Hi Guru,
How to monitor the outgoing traffic on a FIC? I have an issue where from UCS environment i am not able to ping the virtual ip of the firewall cluster, but i am able to ping to the physical IP of the firewall node. Network team has connected a laptop to capture the traffic using continuos pings.
Result is they do not find any traffic of the ip which is not pingable. So i would like to check whether this is getting dropped on the FIC.
Thanks
Bharath
Hi Bharath
In order to capture egress traffic directly from the FI you need to configure a “Traffic Monitor Session” (Think SPAN) Go to the LAN Tab and under the Traffic Monitor Sessions, create a new session on the FI you are interested in capturing from.
Select a Destination port for the traffic and whether the port should run at 1Gbs or 10Gbs the just plug your server/laptop into that port.
You can also use the PING function from the FI CLI by using the “connect local-mgmt” option and look at MAC Address-tables and ARP caches (same commands as Nexus Switches) by using the “connect nxos” command from the FI CLI.
Good luck
Regards
Colin
Hi,
I have a question around the ext-mgmt pool, I have a single block of addresses in the pool and are finding that both the physical server (blade) and the associated service profile get an unique address each.
Both will allow you to connect to the same kvm consle.
Is this normal?
thanks Lee
Hi Lee
Yes this is normal and by design.
The reason is that the CIMC IP address was historically only assigned to the physical blade.
If the Service Profile was moved to a different blade the CIMC address would obviously change. This is not generally a big deal
as most clients to not reference CIMC address directly but instad use the USCM or KVM Launcher.
However some clients wanted a consistant CIMC address even after a Service Profile was moved to a different blade. This maybe because they are referencing the CIMC IP address in some tool or script.
So since UCSM 2.x an optional CIMC address can now be assigned to the Service profile which moves with it. The CIMC address assigned to the blade is still mandatory even if SP CIMC addresses are used.
As a rule I don’t tend to use SP CIMC addresses unless the client has a specific need for them which isn’t very often.
Regards
Colin
Thank you Colin,
best regards
Lee
Hi,
We have UCS Boot from SAN Service Profiles. Native Fibre Channel is via Brocade switches. The The boot vHBAs Login to the fabric and can be zoned. However additional vHBA added to the Service Profile for ESXI Hosts to access additional storage LUNs do not Login to the Brocade fabric and therefore cannot be zoned. Any suggestions with this setup using additional vHBAs would be appreciated.
Hi Ian
I must admit I usually present Boot LUNs and Non Boot LUNs over the same vHBA, but it is perfectly valid to separate them out. The main thing to be aware of is that when you use a Boot Policy, that will initiate the FLOGI into the FI and the subsequent Proxy FLOGI into your Brocades.
You will not have this with your additional vHBA’s which are not using the Boot from SAN policy and as such will need a driver loaded to initialise the vHBA and kick off the FLOGI process.
If you want to test this from the UCS cli prior to a device driver taking control you can use the following commands.
Attach to the VIC
UCSFI-A# connect adapter 1/1/1 (Chassis/Blade/Adapter)
adapter 1/1/1# connect
adapter 1/1/1 (top):1# attach-fls
list vNIC ID’s and send PLOGI
adapter 1/1/1 (fls):1# vnic (list vNIC ID’s. Mine reports back vnic 5 and 6, I’ll use 5 in this example)
adapter 1/1/1 (fls):2# login 5 (login to vnic 5)
You should then see the PWWN of your front end array port you have zoned to report back.
Confirm PLOGI was successfull
adapter 1/1/1 (fls):3# lunmap 5 (You should see a Y under PLOGI)
list LUNs seen on that path
adapter 1/1/1 (fls):4# lunlist 5 (you should see al the LUN details you have masked to this host on the Array)
Good Luck
Regards
Colin
Excluding a server from a pool?
Hi we have allocated servers to a pool using a “pool policy qualification” based on memory and storage which has picked up 20odd servers.
Now we need to remove one of the servers from the pool to move it to a global pool as we migrate to UCS Central.
Problem is, if we remove it, it goes back to the same pool after a while.
Is there a way to exclude it from the rule?
thanks
Lee
Hi Lee
Unfortunatley not. The only way to prevent a server that matches a qualification from NOT moving to the associated Server Pool, is either to alter the server/qualification so the Server in question no longer matches it. (You could add/remove some memory for example) Or to not use qualifications but manually assign blades to the required groups.
Nether is ideal from your point of view, ideally you would want to match on your blades s/no and have an exclude from qualification option or somthing. Perhaps a feature request.
Regards
Colin
thanks Colin.
Hello, Colin
Recently I was tald by colleague that UCS have been supporting feature to automatically replace faulty blade by other hot-backup blade and aplly to it service profile of faulty server. Can U pls give specific reference of how to implement this feature?
Thank U
Hi Andy
The way to do this would be to create a Server Pool, and associate your Service Profile to the
POOL
then as long as there is a spare Blade in the pool, in the event of a critical Blade failure the Service Profile will “jump” to one of the spare Blades in the Server Pool.
Try it if you have the oppotunity, Associate the SP to a Server Pool, ensure there is a spare blade in the Pool that meets all criteria of the Service Profile. Then just pull out the live blade. And you should have your Server automatically backup after a few minutes.
Obviously you need to be using Boot from SAN/iSCSI to take any reliance away from the failed Blade.
Other things that will speed up the recovery, is ensure the inital power state of the SP is set to “On” and that the Spare Blade is already running the same Firmware.
What I would do is a Gracefull association of the SP to the Spare Blade at some point first, which will upgrade the Blade FW (If using a Host Firmware Policy in the SP) and to ensure compatibility i.e. same/Compatible H/W like Mez Cards.
Regards
Colin
Hello Colin,
I tried to test auto reassociation. It dosen’t work. It woks if I make decommission of faulty blade.
But we can solve this problem with UCS Power Tool. https://cisco-marketing.hosted.jivesoftware.com/docs/DOC-35549
Thanks Dmytro
I’ll check out that script, and your right Auto reassociation only occurs in the event of a total blade loss. The only time I pitch this feature as helpfull is in a complete blade failure (not common) or someone pulls the wrong blade out of a chassis by mistake (sadly more common) then auto reassociation would kick in and automatically get that work load back up.
Regards
Colin
Hi ,
Could you Please explain about the data flow when IOM B & FI A got failed in a productionUCS Cluster?
Thanks in advance
Sabeesh Chandran
Hi Sabeesh
That’s an easy one, if you loose FI A then all your traffic would flow via FI B.
If you were then unlucky enough to have IOM B fail in one of the Chassis at the same time. Then that Chassis would have no access to any Fabric Interconnect and would be dead in the water. (All vNICs would go down as no uplink interfaces would be available to pin to)
Highly unlikely scenario though.
Regards
Colin
Thanks for the Quick Reply Guru..
Again araise some quiestions…Then what does it means by redundency provided by 2 FI & 2 IOM for the Cisco chasis? What is the solution for manage such solution? Since FI does not Support VPC to the South Bond Traffic ……Could you please explain?
Thanks in advance
Hello Colin,
I have Cisco UCS (a chassis 5108, two FIs 6248up and two IOMs 2204xp) and 2 Cisco B200 M3 servers with VIC 1240 card in them. Each IOM has connected to FI by 4 FEX Uplink. After discover and acknowledge the chassis I got an issue on both IO Modules – backplane port n/n overall status – Failed, additional info – Suspended. On a server in the FSM tab came out –
Name: Discover Nic Presence Local
Status: Fail
Description: detect mezz cards in 1/1(FSMTAGE:sam:dme:ComputeBladeDiscover:NicPresenceLocal)
Order:10
Try: 20
progress status: 21%
Remote invocation result: End Point Unavailable
Remote invocation Error Code: 870
Remote invocation description: End Point Unavailable
Decommission and discover chassis didn’t resolve the issue.
Do you have any ideas what can I do?
Thanks in advanced.
Hi are you seeing a UCS fault code (F0xxx)?
Regards
Colin
code=”F16520″
descr=”[FSM:STAGE:FAILED]: detect mezz cards in 1/2(FSM-STAGE:sam:dme:ComputeBladeDiscover:NicPresenceLocal)”
dn=”sys/chassis-1/blade-2/fault-F16520″
highestSeverity=”warning”
id=”359326″
code=”F77960″
descr=”[FSM:STAGE:REMOTE-ERROR]: Result: end-point-unavailable Code: unspecified Message: sendSamDmeAdapterInfo: identify failed(sam:dme:ComputeBladeDiscover:NicPresenceLocal)”
dn=”sys/chassis-1/blade-2/fault-F77960″
highestSeverity=”warning”
id=”359329″
code=”F999560″
descr=”[FSM:FAILED]: blade discovery 1/2(FSM:sam:dme:ComputeBladeDiscover)”
dn=”sys/chassis-1/blade-2/fault-F999560″
highestSeverity=”critical”
id=”359572″
Hi
Does changing the IP-adress of Fabric Interconnects effect our VM-FEX integration with vCenter?
Best regards Andre
Hi Andre
The Trust between UCSM and vCenter relies on the UCSM Extention key and has no tie to the IP Addresses of the FI’s
Changing the IP’s of the FI’s will not alter the Extension Key and therefore not interupt UCSM to vCenter communication.
To proove, I have just changed the IP addresses of both FI’s and the Cluster IP of my Lab setup this did not break VM-FEX
I could still create Port-Profiles in UCSM and they got created in vCenter just fine.
Remember if you are chaning the subnet the FI’s are on you will also need to change the IP Management Pool range.
Regards
Colin
Hi Colin,
I have a b200 series m2. I recently put in a m81kr with firmware 1.0 (1e). my 6248s are running 2.13 firmware. I cannot upgrade the firmware on the M81kr it always fails with a sendsamDmeAdapterInfo: Identity failed. any ideas on how to get this upgraded?
Hi Alan
Sound like the system is having trouble recognising the M81KR (EndPoint)
It maybe that you need to do a intermediate update on it first, so perhaps try and associate a Host Firmware Policy which only upgrades the M81KR to say ver 2.0 and see if that then alows the 2.13 upgrade. I’m pretty sure you should be able to go from 1.0(1e) direct so perhaps one for TAC.
Regards
Colin
Where are the SD cards for the FlexFlash physically located? Are they the slots on the outside of the blade, or somewhere inside, where the case would have to be removed?
Hi Bobbo
Just pulled the diagrams, the SD Slots are located just under Hard Drive Bay 1, but are accessed from the left side panel as shown in the diagram below. So no need to take the cover off, but still need to pull the server out.
Remember that currently only Cisco 16GB SD Cards are supported P/N UCS-SD-16G
Regards
Colin
Hi,
I’m having trouble to perform ping to some KVM ip address from the fabric interconnect mgmt interface.
– Through the primary fabric interconnect I can ping two KVM ip address;
-Through the subordinated fabric interconnect I can ping the other six kvm ip.
Why does this happen?
Regards,
Jeff
Hi Jeff
The first thing I would check is which FI is primary for each CIMC and see if this correlates to the ones you can PING.
If you check each of the Servers and look in the General>Connections Details Tab it will show which FI is owning that CIMC address (by default UCSM staggers CIMC ownership across FI’s)
Also confirm you can PING BOTH Fabric Interconnect Physical IP’s from the network.
Regards
Colin
Hi Colin
I have two UCS environments, 6120XPs and 6248UPs each with a single chassis attached. I now want to connect the 6120XP to the 6248UP so that I can utilize the storage attached via FCoE to the 6120XPs. Is this possible and what should I configure the ports connected between the different fabric interconnects as – Ethernet Uplink, Appliance port, etc?
Hi Brandon
No this would not be supported you would need to add in an FCoE switch (like a Nexus 5500) connect both sets of FI’s to it and move your FCoE storage up to the new FCoE switch.
Regards
Colin
Hello,
I had a question I was hoping you could answer for me that I have been having a hard time finding a resolution to about the Cisco UCS5108 chassis. My chassis is loaded with M300 Blades and is supporting a VMware ESXi 5.5 environment.
I was trying to find a way to disable/down (as a failover test) an individual vNIC that is assigned to a specific ESXi Host. For some context, I have a Distributed switch configured in Virtual Center. That switch has X 2 vNICs assigned to it as uplinks in an Active/Standby configuration. Only X 1 of these vNICs is acting as Active while the other is only meant for failover.
Is there a way for me to disable a vNIC within UCS Manager that is acting as PRI for the Distributed switch to confirm that failover to the Standby works as expected? I have not been able to find a way to down an individual UCS vNIC that is assigned to a specific ESX Host.
On the other hand, I do see ways to kill an entire Fabric Interface port but in doing so it would effect all ESX Hosts within the UCS Chassis.
Thanks for any info you can provide.
Hi Chris
It would be nice just to be able to disable a vNIC, I have put this in as a feature request in the past so who knows, we may see it in a future version.
In the meantime you can reset the connectivity of a single vNIC which essentially does a Shut/No Shut on the relevant vEth on the FI.
This can be done either by GUI or CLI
GUI
Go into the vNIC and select “Reset Connectivity”
CLI
http://www.cisco.com/web/techdoc/ucs/reference/tree/b/commands/set_adminstate.html
The circuit (vNIC) will be down for approx 20 seconds which should be enough for your test purposes, (I.e have a PING -t running or something)
Hope that helps
Regards
Colin
Thanks for the info Colin, I’ll give the reset connectivity a go.
Hello Colin, Chris,
from UCSM 2.2 there is an option to Disable vNIC adapter.
Guess your feature request got implemented 🙂
Best Regrads,
Adi
Thanks Adi, that enhancement slipped passed me 🙂 Thanks for making me aware. Just confirmed it see below.
Regards
Colin
Thanks for the update on the inclusion of the Disable vNic feature. Unfortunately it looks like I’m SOL as I am only running 2.0(3c) at this time.
At least I have something to look forward to when the time comes to update the software.
Hi,
We have a problem with failover between 2 fabric, when we shut Fi A ( electrical shut ) Fi B don’t take the lead it stay on a subordinate state, we have to force the failover with the lead command to go on a primary state. when we do the same with shutting FI B, FI A take the lead normaly.
Do you have any idea of the root cause of that problem ?
PLease check the output below :
FI-B# show cluster extended-state
Cluster Id: 0x685468sdf45ds48df455g4df5gdf654df
Start time: Fry Mar 11 16:12:17 2013
Last election time: Fry Mar 13 16:45:07 2013
B: UP, SUBORDINATE
A: DOWN, INAPPLICABLE
B: memb state UP, lead state SUBORDINATE, mgmt services state: UP
A: memb state DOWN, lead state INAPPLICABLE, mgmt services state: DOWN
heartbeat state SECONDARY_FAILED
INTERNAL NETWORK INTERFACES:
eth1, DOWN
eth2, DOWN
HA NOT READY
Peer Fabric Interconnect is down
Detailed state of the device selected for HA storage:
Chassis 1, serial: FXXXXXXXX, state: active
Chassis 2, serial: FXXXXXXXX, state: active
Hi
The reason is your L1 and L2 (cluster) links are down. shown above as eth1 and eth2, check the cabling and confirm the L1 and L2 links are up before proceeding any further. Chances are as soon as they are up, the FI’s will see each other, sync and then failover correctly.
Regards
Colin
Good morning! We’re in the process of upgrading the firmware in our environment, and last night we had one blade that wouldn’t load the fw bundle that we created. All others ran the updates just fine. Then, on a whim, we ran the updates one at a time and it worked fine. What gives?
Hi Thanks for the feedback
What error were you getting when trying to apply the whole bundle?
And what version were you going from/to and what Model blade?
I personally have not had that issue, but worth feeding back to TAC on a P4.
Regards
Colin
The ucs blade is a 200-m3 and we upgraded from v2.1(1d) to v2.1(3b). Again, the bundle installed correctly on the other hosts (39), and we’re going to use the same bundle on another 68 hosts tonight. Thanks!
Hi –
I have a 5108 full of M3-200’s with 1240 cards. I noticed my lab-mate – who has an identical (or so I thought) setup is seeing 40G links on Vcenter while I’m only seeing 20G links. My guess is that he has the port expander installed on his M3s (he only has 1240’s as well). Is there a way – besides physically looking at them – or getting lucky with 40G vs 20G to actually see that the port expander is installed? I looked around in Inventory, etc but do not see it. The other clue was that his UCSM shows all 32 backplane ports (with 4 connections to each blade) while mine only shows the odd-numbered ports (and only 2 connections).
Hi Brian
I don’t have any port-expanders in my lab here to check, but it doesn’t surprise me that they do not show up in the inventory tab as they are just a passive device that provides access to the other traces to the FEX’s.
You are right in saying just expanding your FEX and seeing how many host interfaces are up is a good indication what combination of FEX, VIC and MEZ you are using.
Remember that a VIC1240 and 1280 are separate PCIe devices and as such share access to the FEX’s between them. Hense with this combo you will only see a max of 20Gbs from any single vNIC, do get the additional BW you would need to have a vNIC on the 1240 and one on the 1280 then team them at OS level.
Best and most simple solution would be to just use the port-expander which will give you 40Gbs from a single vNIC when used with a 2208XP FEX.
Hope this all makes sense.
Colin
We just purchase a UCS system with chassis using 2208XP IOM, and 4 B200 M3 blades. However, these blades only come with the VIC 1240. Can I add the VIC 1280 to the blades to make use of second adapter and more bandwidth?
With the VIC 1240, I configured two vNICs for management of the ESXi hosts, but they do not communicate correctly until I deselected one vNIC. Is it possible to configure two vNICs for each set with one on FI A and one on FI B?
Thanks
Hi An
It would be simpler to just add in the port-expander to your MEZ slot as that will double the bandwidth to your VIC1240 but still show up as a single adapter in UCSM. If you add in the VIC 1280 you will see 2 adapters in UCSM and have to distribute your vNICs across them to make use of the additional bandwidth.
And yes you can create a vNIC on Fabric A and one on Fabric B and then team them at OS level. For management this should be an active/passive team, to prevent your MGT MAC flapping between fabrics. This is most likely what caused your issues.
For a vDS uplink this can be a active/active team if port based hashing is selected.(to distribute VM MACs across fabrics without the same VM MAC flapping between fabrics)
Regards
Colin
Great site Colin!
I read through all of the posts and a few of them kind of answer my question, but need to know for sure if what I am proposing will work.
We have two 6248 FIs running in FC end host mode connected to a Brocade switch that is connected to a VNX (also connected to the Brocade switch are standalone HP DL servers). A few weeks ago we successfully directly connected the FIs to the VNX and of course had to change the FIs from FC end host mode to FC switch mode. The vHBAs FLOGI with no problem and the blades could see the storage.
We would like to move the standalone HP DL servers off the Brocade and use the FIs as a FC switch providing access to the VNX storage. Is this possible or would we have to use a Nexus 5K to facilitate these connections?
Thanks,
David
Hi David
Connecting non Cisco UCS initiators to the FI in fc switch mode is not supported.
If you need to share the storage to servers outside of the UCS domain then you would need to use an external SAN switch as you find before.
Direct Attach storage option should only be used to provide storage to that particular UCS domain
Click to access r_hcl_B_rel2.21.pdf
Regards
Colin
Same goes for direct-attached IP storage appliance ports. Only do this if non-UCS clients do not need access to this storage.
Hi, I need to know how much power does ucs B200 M3 blade requires? I read that 130 W is required for M3 blade and them I read in another white paper that half width blade need max 600 watts to operate in high density mode. This contradicts. I need to understand why we have 2500 W x 4 power supplies if very less power is required for one blade. What is the max power required for fully populated chassis?
Hi Syed
You can run any power scenario through the Cisco UCS Power Calculator (Link below)
https://mainstayadvisor.com/Modules/Analyses/Edit/Analysis.aspx
Regards
Colin
Hi Colin,
What kind of hashing is supported on UCS 6200 Fabric Interconnects in End Host mode? Think single vNIC, statically pinned to a two-link port-channel to an upstream switch to 2 storage IP addresses, like this.
blade —– FI-A ==0== 3850X ==0== Array
Will the single vNIC be pinned to only one of the uplink port-channel links or will it hash differently over the FI-to-3850 port-channel to different destination IPs?
Thanks,
Mike
Hello and thank you in advance. I’ve got a 6120xp pair setup for ucs blade chassis running 2.21 firmware and that works great. I’ve also got a standalone c260m2 rack server bios 1.5.4a CIMC 1.5.4 with the 1225 vic in slot 7 that when connected via two twinax is not seen by the 6120’s. Links show up and up. I’ve looked at the doc and it seems I’m complying with everything. Are there any configs on the 6120’s or c260 that I need to change? Any typical problems?
Can you manage C class rack servers without putting fabric connect cards in them?
I have 30 or so low performance servers that can’t be virtualized, but have very limited performance requirements. They currently are IBM stand alone servers. I would like to get them managed but I don’t really want to purchase chassis or interconnect boards if I don’t have to. Ideally they could be managed by the UCS but not part of the fabric. Is this possible?
Hi Chris
Yes UCS C Series rack mounts run just fine in “standalone mode”, in fact its more common than running them in “integrated mode”.
However for 30 you may be more cost effective going for a B-Series setup and using low cost efficient performance blades like the B22 which support single socket CPU.
Regards
Colin
Hi Colin,
How can I see if my UCS chassis lost power? What might I find in the logs to tell me this? I know I can view uptime on the interconnects, but what about the chassis?
Thanks!
Mike
hi guru,
how are you ? i have challenge in my UCS environment.. im trying to connect HP TAPE LIBRARY ( LTO -6 ) directly to my Fabric Interconnect..i have already configured EMC Storage directly to FI, With 2 vHBA’S …My Question is…
1.) can i connect HP LTO directly to my FI ?( WILL IT SUPPORT)
2) If Yes…can i add the target ID of the HP TL in the same vHBA where i have add the for san?
3) or i need to create one more vHBA and add the target id for HP TL and do the zoning again?
im using ESXi 5.5
thanks
Hi Colin
We currently run a mixed hypervisor environment consisting of ESXi and XenServer. We are a HP house with G7 and 8 Blades and c7000 enclosures, with 10Gb interconnects. One of our challenges is keeping on top of the various firmware updates whilst also finding firmware that is both stable and supported for both Hypervisors.
If we were to migrate to a UCS environment would we still face the same firmware challenges due to the mix of Hypervisors we have I.e and have to run different firmware for each (within physically separate enclosures) or only upgrade the firmware when a firmware release is supported for both.
Just interested if a UCS environment simplifies this in anyway.
Thanks a lot-Mike
Hi Mike
Your life would certainly be simpler in a UCS Environment, FW revisions are consistent across platforms and are centrally controlled and deployed across the whole UCS Domain.
Regards
Colin
Hello,
Have exisiting UCS Server in place with FCOE connectivity to the VNX.
Will be adding a ISCSI SAN in the environment, just wanted to know how hard it would be to modifiy the Service profile template in order to maintain both FCOE to the old SAN and ISCSI on the new SAN?
Hi Jim
If you are just adding in some iSCSI targets and do not want to boot from an iSCSI target then there are no mandatory changes you need to do.
You may wish as a best practice to create a separate vNIC (large MTU) and VLAN for your iSCSI traffic though.
Regards
Colin
while trying to connect to my lab’s b series server its showing connection failed error.
i have already changed the java setting to minimum but the problem still prevails.
I checked the cisco website also on th given links:-
http://www.cisco.com/c/en/us/support/docs/servers-unified-computing/ucs-manager/115958-ucsm-kvm-troubleshooting-00.html
http://www.cisco.com/c/en/us/td/docs/unified_computing/ucs/ts/guide/UCSTroubleshooting/UCSTroubleshooting_chapter_0100.html
Explain me the cause and resolutions as well.
Hi Neeraj
I would need more info as to when you get this error and how you are trying to connect.
Regards
Colin
I have a question in this regard. If I want to boot VMware esxi host on ucs using their own local hard disk and all the VMs need to be booted from SAN. In that case, how will be the boot order in service profile and how VMs will be configured to boot from SAN? How many VHBA needed? also in this case where esxi hosts are booting from local hard disks and VMs are booted from shared storage, will vmotion and HA work in this scenario? Please advise.
Hey Syed,
I think your confusing 2 things here. Your esxi hypervisor will boot from Local drives, so it means your service profile will contain your local disk in its boot order. Then your VMs will be residing on a VMware datastore ( be it NFS , ISCSI , Fibre channel etc.. ) . You cant really call it boot from SAN for the vms, since its the hypervisor that manages the access to the LUNs, not the vms. And for the OS on the vms , it sees the allocated space from the datastore as a local storage.
Also whichever boot media your ESXI is using, it doesn’t really affect vmotion or HA. These clusters parameters pertains to the VMs shared storage used not the Boot storage for the ESX.
Hi,
Thanks for the reply. I am still confused with one thing. As you said ” You cant really call it boot from SAN for the vms, since its the hypervisor that manages the access to the LUNs, not the vms” Which configuration on ucs or VMware will allow VMs to see target LUN/storage array as datastore? I am asking as i don’t see any configuration which allow VMs to see FC storage as datastore How VM will see target LUN? is there any configuration on ucs or esxi host?
Hi Syed
You can use Raw Device Mappings (RDM) within vSphere to present a LUN directly to a VM
Regards
Colin
Hi,
Have a UCS infrastructure deployed within our environment and running firmware version 2.0(3a). Have a mix of B200 M2/M3 blades. We have not added any blades for quite a while and have recently purchased 3 new blades UCS SP7 B200 PERF EXP w/ 2xE5-2680v2 256G VIC1240 bundled servers. Have created servce profiles then bound them to our template but they don’t work (associate profile). Blades came with 2.2(1b) firmware as i can see this when highlighted within UCS manager. I am a newbie unfortuantely to UCS as the person left the business a few months ago. Any help would be appreciated.
Updated the capability catalog to the latest available version as did experience FRU issues on CPU/Mem
If I need to enable CDP without creating any new ploicy, where should I enable CDP ? Should it be under LAN> Applicances> Network Control Profiles > default or should I do this under Lan > root > NCP > default. I need this to get replicated to the veths.
When I create a vnic template, I can see that there is a drop down for NCP and it defaults to the setting in root.. correct ?
Hi Arshad
Go to LAN>Policies>
And there you can change the default to CDP: Enabled
Regards
Colin
Hello ucsguru
Any specific boot from SAN policies -issues for 5.5 B200 M3 ??
1048320 error from the vmware VMFS write stage.
-vuong
Hi
I’ve come across a few boot policy issues in early 2.2(1a/b) code but not limited to ESXi 5.5
Mainly around enhanced boot settings.
e.g bug CSCun10760
https://tools.cisco.com/bugsearch/bug/CSCun10760
Regards
Colin
Thanks for all of the useful information provided on your site.
I have a question in regards to iSCSI boot. My company is running UCS 2.2(1c) and we have a NetApp as well. (Network is all Nexus based) We have two SPs that need to iSCSI boot, but we can only get one blade at a time to iSCSI boot. They have separate IQNs, IPs, etc. We have both of them in the same native VLAN and they are configured to talk to the same target. We have tried putting each in a separate VLAN, with different IPs, etc and have had no luck. It seems like there is some type of limit that is only allowing us to have 1 iSCSI booting blade up at a time.
Nevermind, I figured it out.
Hi James
Thanks for the question, and glad yo sorted it.
If you could update the thread withn your resolution for the benefit of others.
Thanks
Colin
Hi Guru,
I have a question on PVLAN on vmware DVS within UCS in end-host mode. I want to know if I can have a primary vlan in promiscuous mode and an associated isolated vlan (one network e.g. 172.16.0.0/16) configured on VMware DVS.
The above configuration I have done with a Nexus 1000v and it works like a treat. On UCS I create just the primary vlan and map it to the VMNIC for upstream, but with a vmware DVS I am missing something on the vmware side or something on the UCS side.
Can you please help me here. Thank you.
Cheers
Sandeep
Hi Sandeep
I’m with you and use N1KVs more than I use the Distributed Switch, but private VLANs are certainly supported in the manner you want.
Guide below:
http://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=1010691
Regards
Colin
Hi to all of You:
I am new in the UCS field, and I do have a topology where there are 2 FI 6248 UP working as cluster, after a reboot, one of the FI, has not booted up completely, I do have on the console reporte the prompt that is FI-A(boot)#,
Please could you help me on the procedure on copying the image or NXOS to the FI flash or bootflash memory?
Thanks in advance for your help.
Javier
Hi Javier
Pretty sure you’re going to need to raise a TAC case as the boot files you will likley need are not publically downloadable.
The proceedure for the 6120 is as per the below, which I would think would be the same for the 6248 but again TAC would advise.
Good luck
https://supportforums.cisco.com/document/45766/how-recover-software-failure-6120-fabric-interconnect
Any idea if UCS Central supports private VLAN functionality similar to UCS Manager? It does not seem to. From what I can tell so far, it appears as if I want an isolated PVLAN, it has to be with a local service profile.
Thanks. 🙂
Hi Ryan
I like you have only configured PVLANs within UCSM, I checked a clients 1.1(1b) UCS Central earlier this week and you are right no PVLAN option. There is no mention of PVLANs in the 1.1(2) release notes either. so looks like that will need to ramain a local UCSM config task for the moment at least.
Regards
Colin
I reached out to Cisco and the response I got was that there isn’t any road map right now for the feature to arrive in Central. So, what the ‘workaround’ is I suppose is to create those VLANs as classic within UCSC and perform PVLAN operations on either the 1000v or VMware DVS (which now supports them). Doesn’t do much for your bare metal, so if you want to use Central for everything greenfield, host-based access controls and/or PBACLs/VACLs seem like more or less the routes to take there.
What is the use case for a M61KR mezz? Why would one choose this card over one of the VICs M81, 1240, or 1280)? Since it is marketed as a CNA I assume it supports ethernet and FCoE, but the data sheet says it will support fibre channel in the future. Does this mean no FCoE now? Thanks.
Hi Bill
The M61KR is an Ethernet only adapter that uses Intel ASICs (no FC capability) the only storage capability would be IP based storage (iSCSI)
As such I’ve never really came across a valid use case for one, as the price delta with the much more flexible M81KR did not really justify the choice in my opinion.
But if a customer absolutley has no plans for FC storage and prefers an Intel Chipset then this cards for them I guess.
Regards
Colin
Hi Colin,
Please let me know the daily checsk which we can perform on UCS .
Regards, Abhinav SIngh
As far as day to day checks go, I would generally just keep an eye on the Alert traffic lights within UCSM, they are pretty good at picking up most things.
Obviuosly you can also setup alerting to proactivley inform you of any issues, rather than you having to check it.
Regards
Colin
Hi ucsguru!
We had a power failure in our active FI and while it was rebooting, we completely lost the network connectivity to our virtual machines connected to the VDS provided by the FI, after a while (10 minutes or so), the connection was reestablished and everything is working ok, in the vmkernel logs you can see how the interfaces of VDS are going down and 10 minutes later, up. UCS version is 2.0(5f) and vSphere 4.1
We are totally lost about the issue, any ideas?
Thanks!
BTW:
– FI 6120 XP
– Servers B200M1
– M81KR CNA
Hi JMS
I would first look at why you lost connectivity when you only lost a single FI, sounds like you may have some HA misconfigurations i.e. not protect single vNICs with Fabric failover or not teaming vNICs on different fabrics etc..
Regards
Colin
Hi Collin,
Newbie here! I want to move our data center over to Cisco UCS, but have some reservations. To make a long story short, I have 2 Dell server at end of life along with core switch stack. I can combine budget for switches and servers to purchase UCS with 3 x M3 200 servers. I have an additional 6 Dell servers that are not quite end of life (over 1 year from end of life). I have an EMC 5000 connected via 9148 fabric switches and Nimble connected via Nexus 5000 series. Is it possible to buy the UCS and add the 6 Dell servers to the 6296 interconnects for connectivity without buying new copper switches? Is this a dumb question? I plan on replacing the other 6 Dell servers in 2015 with another UCS chassis.
Hi Todd
Not a dumb question at all, I get asked this a lot, why can’t I just plug 3rd party servers into my FI?
The short answer is you can get it to work but it is not supported and certainly not what the FI was designed for.
Looking at your setup the 6296’s may well be overkill for your environment if your only talking about an initial 3 servers, may be better looking at 6248 which should save you some money, and if your current Nexus 5000 are short on copper ports, the money you save would pay for a couple of Fabric Extenders to give you more copper on the N5K’s
Regards
Colin
Hello!
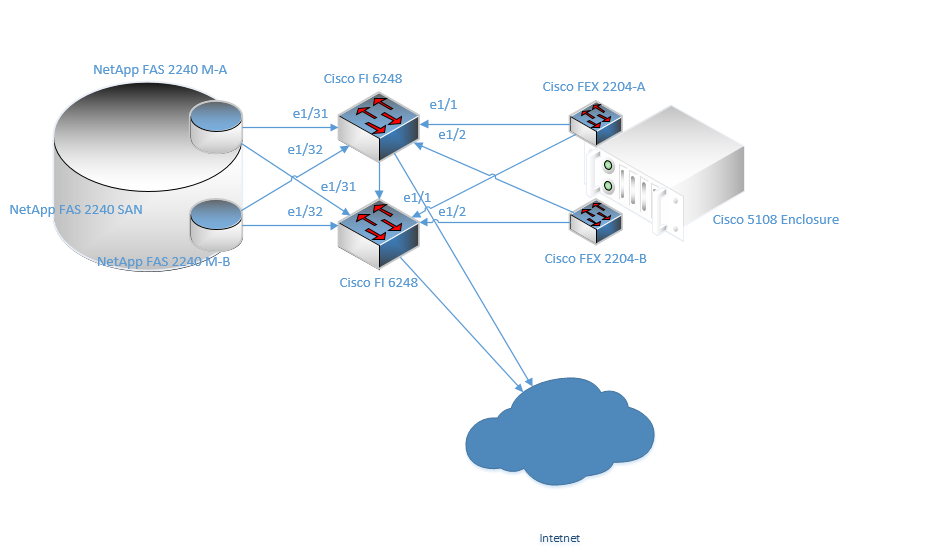
I have next scheme:
Could I connect mgmt0 interface of FI-A to FI-B (port e1/10) and mgmt0 of FI-B to FI-A (port e1/10) ?
I will have visualization and I could contol FIs from VM.
Or it’s not work configuration and i need to use switch for management? Why?
Hi Pavel
Thanks for the question, looking at your diagram, you cannot cross connect a 2204 IO Module to both FI’s IOM A goes to FIA and IOM B to FI B.
Also the ports on the FI’s are not conventional switch ports and do not by default learn MAC addresses. So you cannot plug in a management interface into them. Use a external management switch like a 2960 or something. (Assuming you do not already have an OOB management network)
Regards
Colin
Link aggregation limits.
Are FI to Nexus links treated as traditional link aggregation, where a vm will be limited to the throughput for a single session of 10g? Or is the IOM/FI/Nexus port channel truly aggregation because of some type of magic?
The reason I ask is that I’ve been running into some FC throughput limitations that appear to point to traffic being constrained to a single 10g link.
Hi Matt
By Default blades slots are pinned to particular FEX links (Discrete Pinning Mode) Which would mean that any server would be limited to the bandwidth of a single 10Gb link.
If however you have chosen to Port-Channel the links (And you should) between the FEX and the IOM then each blade will have access to the entire port-channel bandwidth.
While this is the case any individual flow will of course end up on a single 10Gb link.
Regards
Colin
Hi UCSguru,
Good Day!!!
My question might seems to be stupid but I am bit new to ucs. I have a requirement to use catalyst 3850 switch along with UCS Fibre interconect (62xx) for uplink connectivity. I have tried searching for best connection topology for uplink connectivity but unable to find one with cisco catalyst 3850. Can you please suggest best approach to use catalyst 3850 with Fibre interconnect for uplink connectivity.
Regards,
Parkash
Hi Parkash
You would treat your 3850 Stack the sameway as a Nexus vPC pair. I.e you would have a port-channel from FI A to two 3850 stack members, and then the same for Fabric B.
Ideally you will have the 10Gb ports in your 3850 stack, but 1Gb uplinks are supported.
Regards
Colin
Hi,
I want to upgrade the firmware on FI which are not in production. What will be the best method to proceed with the upgrade?
If you already have UCS 2.1 Firmware then use the Firmware Auto Upgrade feature.
But download the specific doc which details the procedure for the version you are going from and to.
Read and follow it carefully.
A few other tips highlighted in the below interview
Regards
Colin
Just stumbled over your blog and its been very helpful whilst researching UCS. Its my first ever exposure to UCS
Our company are about to pull the trigger on the Cisco UCS 5108 – can this chassis be “stackable” if we in the future buy another 5108? If so, can it stack via the built in Fabric Interconnect, or do we need to fork out for a Fabric Extender?
TIA
Don
Hi Don, no you do not stack the chassis, the way you scale UCS is just add another Chassis including the FEX’s and cable to the Fabric Interconnect. (Hub and Spoke type setup) the Beauty with this method is there is zero config required on the Chassis, just configure your FI port as a server port and your done.
That said for smaller environments (15 servers or less) You could go for the new 6324 FI, which is the chassis integrated Fabric Interconnect, in that instance you will be able to connect a 2nd Chassis to it (in effect daisy chain 2 chassis).
1st release of the 6324 code will not support the 2nd Chassis but will be added to a later code drop.
Regards
Colin
Hi colin,
I have a doubt Can we connect the ucs rack server in FI,….?Or we required to connect through nexus switch ….?
I Vanish
Yes you can absolutely connect the Rackmount (C-Series) directly into the Fabric Interconnect (if you only have a few) or into a 2232PP Fabric Extender connected to the FI (If you have a lot of Rack Mounts)
http://www.cisco.com/c/en/us/td/docs/unified_computing/ucs/c-series_integration/ucsm2-2/b_C-Series-Integration_UCSM2-2.html
Regards
Colin
Thanks for quick reply…….My doubt is clear now…
Hi,
Help Help!!!!!!!!!
for connectivity check we power off the primary FI,all server is goes down even we have secondary FI is up both are in cluster also,I think its not switch over to secondary FI….what is the issuse…?
I would suggest either your FI Cluster was not in a operational HA state, or all of your Networking was using Fabric A with no Failover or Fabric redundancy configured.
Colin
how to configure HA state..?
Hi Colin,
Can explain how I can connect my MDS9148 switches to the Nexus 5K instead to the FI? Is there any down side on it? Also, do you have any documentation of which type of connection to use to connect between the chassis to FI and FI to N5K?
Thanks
John
Hi John
The MD9148 being a native FC switch, you would just connect it to a native FC port on the N5K and configure both ends a E Ports (or TE Ports if carrying multiple VSANs) you also have the option of Using SAN port channels.
You could also put your MDS9148 in NPV mode, in which case it would behave just like the Fabric Interconnect (i.e act like a host with a shed loads of WWPN’s)
Between the Chassis and FI is mandatory FCoE but all configuration is transparent and handled by UCS Manager for you. You can choose the physical medium i.e. fibre or copper but most time you just use the cheap copper Twinax.
FI to 5K you can use either a unified uplink (FCoE) or native Fibre Channel. depends how and if you want to mix your Ethernet and FC traffic. (see my post on FCoE Demystified for pros/cons)
Thanks for the comment.
Colin
Thanks for a quick reply. I actually posted this early but it was still waiting for moderation.
We just purchased the following:
2 x Chassis
2 x 6248 IC
2 x 5548UP
2 x MDS9148
Hitachi HUS-VM SAN
Here is how I would like to connect them together.
Chassis1&2 —> 6248(A) —> 5548UP(A) —> MDS9148(A) —> HUS-VM
—> 6248(B) —> 5548UP(B) —> MDS9148(B) —> HUS-VM
—> 6248(A) —> 5548UP(A) —> MDS9148(A) —> HUS-VM
—> 6248(B) —> 5548UP(B) —> MDS9148(B) —> HUS-VM
What do you think of my design? Also, do you have any step-by-step instructions of setting this up?
Thanks
John
Hi John
Firstly apologies if I have not got around to your question first time round, I get so many questions and much of my time these days is taken up with CCIE DC study.
But I do try and have a purge every now and then, so you may find I answer this question again in a week or so 🙂
Several Options with your kit, depending of your FC Port density, you could just configure some native FC ports in your 5548’s and not use your MDS.
if you need or want to use your MDS then I would generally create a vPC from the FI to each upstream Nexus.
Then as you say just uplink FIA to MDSA and FIB to MDS B
As its a Cisco to Cisco connection you can also use VSAN Trunking and SAN Port-Channels
Regards
Colin
Colin,
firstly, you don’t need to apologized for not answering my question. I really appreciate that you take you time to answer my questions. As for my kit, FC port density is definitely not a problem. I was suggested that I connect my MDS switches to the 5548 to save port on the FI for future chassis expansion. I was also told FI is normally license for 16 ports and I will need to pay for licensing if I need more port.
John
Hi,
I am new to the Unified Computing System (UCS) along with the FIP and VDX that are used in the solution. We purchased 2 – UCS B-series, 4 – UCS 6248 FIPs and 4 – Brocade VDX 6730 to upgrade our current infrastructure. We have two sites so 1 UCS, 2 – UCS 6248 FIPs and 2 – Brocade VDX 6730s in one building and the same in another building. So, let me give you a quick description of the current infrastructure and the issue we have run into with the new environment.
Current: 2 – HP EVA 8400/6400 Storage Area Networks (SANs) that have “NATIVE FIBER CHANNEL (FC)” ports only. 4 – Nexus 5020, 2 – Cisco 6509 switches. Currently, the SAN FC ports plug into the “NATIVE FC” ports on the Nexus 5020. The Cisco 6509 plugs into the FCoE ports on the Nexus 5020. There are glass paths that go directly from one Nexus 5020 to the other in the 2nd building. Also, there are glass paths that go from the Cisco 6509 switch from one building to the other.
NOTE: So, the NEXUS 5020 takes the “NATIVE FC” traffic from the SANs and converts it into “FCoE” traffic which then is passed down to our current IBM blade solution. I assume it does this via FIP snooping? If that is not correct please inform.
We purchase the UCS B-series, UCS 6248 FIP and Brocade VDX 6730 based on the fact it claims “UNIFIED FABRIC” meaning it can do “NATIVE FC and FCoE” just as the Nexus 5020 can. We have found out this is not the case. The VDX has “FLEX” ports which handle regular “FIBER” and not “NATIVE FC” per the vendor. I was unaware there is a difference. Our “FC” ports on the EVA 8400/6400 SANs show up as “E ports” which the VDX only knows “F ports”.
So, long story short we purchased all this equipment with the belief that we would be able to connect “NATIVE FC” into the VDX and it would be able to convert to “FCoE” and pass it down to the UCS blades. This is not happening. According to the vendor, the VDX 6730 doesn’t know how to translate “NATIVE FC”.
Do you have any ideas on this issue? The reason we are going away from the Nexus 5020s is because of a distance limitation.
Thank you for any help.
Eric
Hi Eric
I have setup Brocade VDX switches, but only as VCS Ethernet Fabric switches. (see my post a while back on UCS / VCS a great combo)
But looking at the spec sheets the VDX 6730 does support native FC and FCoE. (Altough would have thought your logical upgrade to the 5020 would have been a Nexus 5500/5600 ;-).
But anyway, I would have thought your EVA ports would be “N ports” and as such would plug into the “F Port” of the Brocade just fine.
“E ports” are for connecting 2 FC switches together. So it maybe you have a FC switch in your EVA cabinet that is connecting to the E port on the Nexus 5020.
The 6248UPs can indeed support FCoE and Native FC and can also support direct FC and FCoE attached storage if you put the FI into FC switch mode.
Either may sounds like you have some options to consider.
Regards
Colin
Hello Colin,
My question is if I enable fabric failover on one vNIC for specific single VLAN and primary FI selected is A. Now if Fabric interconnect A goes down, the fabric failover will use fabric interconnect B for the traffic. Now let us if fabric interconnect comes online again, will the traffic fall back to FI-A OR if fabric interconnect B goes down, what will happen to traffic, will it still fallback. Remember I have only one vNIC in this scenario.
Regards,
Hi Salman
Yes the vNIC will failback once the uplink to Fabric A comes back online, failback is sub-second and I would be surprised if you lost a single PING.
Nothing you need to configure, this is default behaviour and cannot be altered.
FI A will issue a Gratuitous ARP to inform the upstream switch(es) that the MAC Address has moved back to Fabric A.
Colin
Thanks Colin for the prompt reply. Can you please share some link on cisco website mentioning the same? Regards,
Hello Colin,
is there an easy way to move disks (entire OS) out of one of the blades in one UCS system (FI+Blade Chassis) to totally different UCS System (different FI+Blade Chassis) and have UCSM not destroy the RAID setup or scrub the disks assuming I would make identical Service Profile (same number of vNIC and vHBA, same boot options, same local disk policy, etc…).
The goal is to have the OS boot up as usual and work as if nothing happened.
Thank you in advance
Best Regards,
Adi
Hello Colin,
Do we need to follow the traditional approach of dedicated vHBAs for SAN boot and SAN Data access for VIC 1240 card ?
Jay
Hi Jay
I usually don’t. Keep things nice and simple and just have 2 vHBAs. 1 Fabric A, 1 Fabric B. And use for both Boot and Data.
Colin
Hi Colin
How can I allocate service profiles from a template to a pool of blades in the reverse order to what Cisco does automatically which seems to be from bottom blade upwards in a chassis ?
Nimal
Hi Nimal
As far as I know there is now way to alter the order in which Blades are consumed from a pool.
If you need to specify a particular blade the only way to do it would be to assign the SP to the Blade manually.
Colin
Hi I was wondering if you could shine some light on the below :
I am looking to set up a LAB environment for a few teams and would like to use a cisco UCS Blade Is it possible to Nest VMware running on a Cisco UCS Blade Environment for Lab Testing purposes ONLY.
Tony
Hi Tony
Yes, Absolutley I teach a Nexus 1000v course for 10 students at a time and give each student 2 x Virtual ESXi servers to add to their Nexus 1000v instance.
The whole environment runs on a pair of physical ESXi UCS B250 servers.
Just make sure you follow all the standard tasks for running a nested environment like,
On your Physical host:
echo ‘vhv.allow = “TRUE” ‘ >> /etc/vmware/config
and set Promiscuous mode to “accept” on your physical hosts vSwitch.
There are loads of post out there on how to set up a nested lab.
Regards
Colin
Thankyou for the reply I’ll have a look at a Lab Guide to set up and configure the environment to run on a single UCS Bm3 blade with all the storage on VNX
HI,
How to check FI port connectivity in CLI mode…?i want see the whole connectivity of FI Port in CLI mode…
Hi Isaac
Easiest way would be to connect to NX-OS mode of each FI, and do a sh interface brief / sh interface status
Regards
Colin
Thanks for Your reply
Hello Colin
I have the following config
1x 5108 with 2204xp
1x 5108 with 2208xp
2x 6248 FC-switch mode, ethernet – EHM
2x B420 m3 with 2x VIC1280 located in (1x 5108 with 2208xp)
4x B440 M2 with 2x VIC1280located in (1x 5108 with 2208xp and 1x 5108 with 2204xp)
2x block VNX arrays connected using FC
2x Nexus 3k – in vpc mode with 2 link port channel from each FI6248
Each FI connected with corresponding IOM using 2x 10G port channel
I have the issues which I would like to get comments from you.
Each b440 m2 has been configured with 4 vnics and 2 fc HBA.
After the service profile has been associated with any of b440 m2 server I have FC connections unpinned and Link state is up. I can see the pwwns in flogi database of corresponding VSAN
At the same time vnics are unpinned and their link state is “unknown” as well as adapter host interface is down as well
What might be the root cause of the issue
Thank you in advance
Hi Dzmitryj
Sounds like the issue is the system does not think there is a viable uplink port available to which to pin your vHBA’s and vNICs to.
If the same Service profiles work fine on the B420’s this would tend to discount misconfigured uplink ports.
My first thought is your issue may be due to having 2 Mez cards and is perhaps down to an incorrect an placement policy. Having 2 Mez cards means that by default your vNICs and vHBAs will be split across them.
Your Mez in slot 1 will be represented as vCon1 in the placement details/policy and your Mez in Slot 2 will be represented as vCon2.
May be worth placing all your vNICs and vHBA’s on the same vCon, just to see if this brings everything up, once confirmed you can then sensibly move 2 of the vNICs and 1 vHBA to the other vCon, via a placement policy and confirm all still works.
Regards
Colin
Changing of FI Management IP , Cluster IP & KVM’s IP
Dear Colin,
I have two fabric interconnect in a HA mode , due to lack of IP’s we are not able to enhance the management pools for the KVM , so we have planned introduced a new Vlan which we will use for fabric management & KVM , since we cannot use different vlan for KVM , it has to be in same management VLAN .
Since all the ESXI are into production , if we will be going to change the management & cluster IP of FI & KVM , will it impact any thing on the ESXi
Will reboot of the FI required after changing the IP’s
Can you please help me what all prevention measures we should take since the environment is in production
Thanks & Regards,
Nitin
Hi Nitin
I have changed the IP addresses for FI’s on the fly several times and have never had an issue.
And no the FI’s do not require a reboot.
Just do all addresses at the same time in the Admin>Management Interfaces tab (FI A, FI B and Cluster address, Plus Default Gateway)
Treble check your addresses before you apply, especially the default gateway so you don’t lock yourself out of the FI’s.
Things to be aware of though are if you have any firewall rules that may contain the IP addresses of the FI’s etc..
Good luck
Colin
Thanks A lot Colin for your time 🙂
Hi,
Am unable to install windows 2008 in cisco b200m3 on san boot device error windows cannot be installed to this disk this computers hardware may not supporting booting to this disk
Hi Raj
I have seen this issue if you also have local disks in the UCS Blades with valid partitions on. if you have try taking them out to see if thats the issue.
Also for the OS installation insure you only have a single active path to your Boot LUN across the fabric, you can do this by only specifing a single WWPN target on one path in your boot policy, or get the SAN admins to only zone you to a single target.
Once done you should be all sorted.
Regards
Colin
I just installed two brand new out of the box Cisco UCS blades. I had 4 currently in production on a VMware vCenter infrastructure. As soon as i pushed the two blades in 1 of the production blades networking went out. I could not ping it. i could however console into it. All the VM’s came up on another host and i power cycled the host. It came back up after a power cycle. Why would my host loose networking when inserting two brand new blades? Any help woul dbe awsome
Have never seen that before Joshua.
I would want to look into whether networking on both Fabrics went out, or just one.
Also what state the vNICs were in, once failed. i.e. was an uplink not available etc..
Appreciate you had to just get them back online ASAP , but difficult to say without the seeing the issue.
I would definatley rasie a P4 Service request, and see what TAC have to say. (get a dump of your System Event Logs (SEL) if the errors are still present in them.
Good luck
Colin
Hi Colin, I have a question about chassis discovery policy. I have 4 server port links in port-channel and chassis discovery policy is “4 links”. What will happen if one of the server port link goes down, will it decommission the chassis?
No, it will not decommission the chassis. Chassis discovery protocol is used only while discovering the chassis for the first time.
Hi ,
Just want to know the recommended steps to remove the chassis from UCS permanently.
Proceedure is detailed here:
http://www.cisco.com/c/en/us/td/docs/unified_computing/ucs/sw/gui/config/guide/2-0/b_UCSM_GUI_Configuration_Guide_2_0/b_UCSM_GUI_Configuration_Guide_2_0_chapter_0100010.html#task_47DBF8DFD93D458AAFF2C0B3C61E9FE9
Regards
Colin
Hi Guru, any experience related to stuck ucs server with configuring and testing memory, and
after that nothing. Server can’t boot. This is situation after unsuccessful firmware upgrade from 1.5.3 to 2.0.1b. Recovery jumper not work. CIMS is active and we tried upgrade cims and bios firmware from gui and cli, no luck. CIMS is upgraded and activated but bios not, and all of
time show same version 1.5.3 even if successfully transferred and written bios image to flash . TAC case is opened several days no answer from them. Any suggestion . For me looks like server can’t activate upgraded bios for some reason, probably that is reason why upgrade is unsuccessful .
As far as I know the versions of bios and cims must be same to sucesfully boot server. This is ucs 220 m3.
Hi Slavko
All I can suggest is that you have a go at doing a Server re-seat then after the disovery (if it discovers) use the “Recover Server” option and select “Recover Corrupt BIOS”
If that fails, sounds like you’ll need a replacement, but TAC will advise. Give them a chase if its holding you up.
Good Luck
Colin
Hi Colin,
I have a query regarding the Addition of New VLAN’s to the UCS .
1. If I am adding the new VLAN to the VNIC template and that VNIC template used by many service profile will the server reboot requires ?
2. if i Add the VLAN to the Vnic on the service profile directly if the service profile does not use the VNIC template , then do i need to reset the adapter to access the new VLAN on the server?
3. can i add the VLAN to the vnic of the service profile if the service profile using the VNIC template ?
I don’t have the test bed its a production so on safer side before doing any changes i want to clarified with possible impact , please help.
Hi Colin,
I have encountered with an fault on one server saying that local disk 1 & local disk 2 are missing .
overall status of the server is ok and the server is UP , ESXi is running on the server .
can you please help me how to resolve this error from the UCS , since the ESX is working fine then no idea why it is posting this error.
Local Disk:
ID: 1
Block Size: Unknown
Blocks: Unknown
Size (MB): Unknown
Operability: N/A
Presence: Missing
ID: 2
Block Size: Unknown
Blocks: Unknown
Size (MB): Unknown
Operability: N/A
Presence: Missing
Hi Colin,
Can I enable VMQ policy on all Hyper-V server adapters, not only VMs adapters ?
I mean, Management, iSCSI adapters. Will be there benefits ?
UCS 2.2(1c).
Thanks
We have some load on host=server vNICs: iSCSI adapters (2 paths) + MGMT.
MGMT for backup and deploy VMs.
Should I enable VMQ on these host adapters for less load on default CPU ?
Hi Colin ,
My boss is actually contemplating hearing what Dell has to offer . It all started with a free lunch and dinner . Talk about a cheap date LOL. Can you do a comparison of UCS vs Dell Blades and Chassis. I do need some ammunition when we start having conference calls . Can Dell move a workload to a different Dell blade like UCS can with Service profiles ? Stuff like that .
Hi Colin,
I wonder if UCS 6248 Fabric InterConnect can be connected directly to the SAN storage. And what interoperability it’d have, like it’s not compatible with IBM V7000, for example.
Hi Tolz
Last time I checked the only storage that was officially supported for direct connect was EMC and NetApp, and I think Invicta now.
I’ll see if I can find the latest direct connect compatability matrix.
Obviously if this is a lab/dev/test environment I’m sure you already know that any FC Storage will infact work.
Regards
Colin
Hello Colin,
Can UCS in EHM connect to a Nexus 5k in NPV mode?
Hi Niyi
No it is not possible to uplink an FI in FC NPV Mode to an Upstream switch also in NPV mode.
You are allowed to daisy chain two NPV devices together (Nested NPV) but the UCS Platform is already making use of this nested feature.
Regards
Colin
I am planning to do Linux cluster on ucs bare metal blades. I wonder How can I do equivalent of cluster interconnect between the bare metal servers. There are no physical ports for direct connections between the servers. Moreover Linux uses multicast for cluster traffic between the cluster nodes.
Hi Just use a dedicated vNIC for the Heartbeat and a dedicated VLAN trunked down to it.
You may have to enable IGMP Snooping on the upstream physical switch.
Regards
Colin
Is there a way using PowerShell / UCS PowerTool to query all blades in a UCS domain to verify that an ESXi HyperVisor has been installed — short of going to every KVM and verifying. I know I can look at it in vCenter, but hoping there is a quick way to do it scripted.
Where can I find cabling instructions for the 5108 to 6248, N5K, I having been tasked to setup this equipment and configure, and have no idea of what I am doing!! I was told to configure for maximum redundancy and this includes a EMC SAN. Can anyone HELP?
Hi Chris, there is only really one way to correctly cable a UCS Chassis into its fabric interconnect, so you cant go too far wrong 🙂 (see below diagram)
You only thing you really need to think about is how much bandwidth you need to give the chassis, 10Gb to 160Gb depending on the HW you have.
I would also configure the links between the FI and IOM in the Chassis to be a port-channel that way you get maximum bandwidth for your blades and minimise the impact of any link failure between the FI and the chassis.
Regards
Colin
Hello, I am running into a situation where I am wanting to use and inband pool of IP addresses for CIMC/KVM connectivity, and in my SP I have specifically told it to use ‘none’ for outband, and my created pool for inband, but when the blade comes up it’s pulling two IP addresses out of the inband pool, one for ‘inband’ and a second for ‘outband’. Is there a way to stop the assignment of the ‘outband’ as this is eating up two addresses where I only need one.
Thoughts all?…thanks
Hi… yesterday a saw an old presentation and it shows up how to integrate a Cisco UCS C-series rack mount server into UCS Manager. They used two 6120 FIs, extendended the management planed with a 2248 FEX and connected the rack servers VIC ports directly to the FIs and two onboard 1Gbits/s port to the 2248 FEX (management plane). Can I do the same with a 2148 FEX ? And is this possible with a P81E VIC ? I’m building a UCS ecosystem in my homelab, currently. And the integration of a Cisco rack server would be very cool !!! Thx.
Hi Dorde
C Series integration has certainly chopped and changed several times over the years and versions.
Nowadays you can just directly connect your C-Series to the FI’s via VIC1225/VIC1227, and there is even a reduced cost port license for doing so. Alternatively if you have several C-Series you need to integrate you can still use a 2232PP FEX to aggregate them.
The 2248T You mention was dropped from version 2.0.2, so if you wanted to use your P81E with the 2248T you would need to run a UCSM version of 2.0.1 or earlier.
Don’t think the 2148 was ever supported.
Sounds like your best bet would be to just try and pick up a VIC 1225 if your C-Series supports it.
Regards
Colin
Hello, We have a 6248UP that after the firmware update via CLI no longer boots. There is power but we cannot get a connection via console any more. Is there a way to fix this or is it fried?
Hi Matthew
All my recovery techniques require at least console access, if you have no console access, it sounds pretty terminal. I would open a TAC case if you qualify for a replacement.
Colin
Hi Colin
First of all let me convey my sincere Thanks for your knowledge sharing about UCS in detail.
My query is about VM-FEX technology .. Is it possible to migrate a VM (vmotion) from one host to another which is attached with a LUN (RDM) in Physical compatibility mode using VM-FEX technology either in emulated mode or in VM-Direct path mode.
Cisco Blade Model : B230M2 with M81KR vic ; Firmware version : 2.1.(3g)
UCS Manager Version : 2.1.(3g)
Fabric Interconnect : 6248UP
ESXi Version : 5.5 U1
vCenter Server version : 5.5
Source and destination hosts are part of a EMC storage group, hence the LUN will be visible to both hosts.
Please share with links and relevant information
Thanks in advance
Anand
Yes, you can. Also you can attach iSCSI disks inside guest.
Vmotion will work. But you will have an issue with backup of the system disk if you need to use native snapshots or your storage uses native VMware snapshots.
VMware officially is not supporting a consistent snapshot of the system disk, if you have RDM disks, attached to this VM. Ooopps.
Hi colin,
Can i upgrade UCS Firmware from 2.2(1d) to current version firmware.
If i upgrade,then downtime required for the FI and Blade server END…?
Please help!!!!!!!!!!!!!!!!!!!!!!!!!!!!!Awaiting for your response….
Hi Colin, I am using UCS FI 6248 UP with 5108 ucs chasis and B200 M3 servers and for network nexus 5k. I wanted to install windows 2012 R2 on 2 UCS server with SQL 2014 Cluster. How can i assign private nic to this 2 servers for SQL cluster heart beat. Kindly help me.
Just create a seperate vNIC for heartbeat and call it heartbeat or something logical and map it to an isolated VLAN then just ensure that VLAN is trunked down to the vNICs you have created. #Simples 🙂
Colin
Please allow the config to N5k and select the isolated vlan as native vlan while assinging to the extra vnic.
Hello,
I got some weird trouble. When I have both FIs working, I get very slow network performance of my VMs. After I take one of FIs offline ( either A or B) everything works perfect. Checked my configs very carefully but can’t find nothing out of the ordinary. Any input?
It sounds to me like you may be using a sub-optimal hashing algorithm, which may be causing MAC addresses to flap between fabrics.
Recommendation is to use PortID Hashing for a hypervisor workload, that way guests are load balanced across the fabrics, but each individual guest remains within a single fabric so upstream switches do not get confused.
I would start by mapping a single vNIC to one fabric (with both FI’s active) confirm performance is fine, then, re-introduce fabric load balancing with a supported Hash (if that’s what you are doing) and confirm that works.
Hi Colin,
What is the best practice of using FC data store. Do we need 2 separte vHBA(s) for data store or the vHBA(s) for boot from SAN can be used for FC data store.
Please suggest.
My view, is no just use the same vHBA’s for boot LUNs and Datastores.
There maybe a internal standard or policy within your company that requires this, and if so it may be worth revisiting that policy to see why it was created in the first place, as it may not be relevant in a Virtualised IO world.
If you think, there are 2 reasons to use separate Adapters.
1) Additional Throughput/Fault tolerance that multiple adapters provide
2) Traffic Isolation
As vHBA’s within the VIC are visualized, throughput is determined by the bandwidth available to the parent adapter, not by the number of vHBA’s created. I have benchmarked this and adding in additional vHBA’s/vNICs does increase throughput but not by a factor of 2 for each additional virtual adapter and this increase really dropped off after adding a 3rd adapter.
The other reason traffic Isolation may still be relevant, but in most cases logical seperation is fine i.e using multiple VSANs on the same Adapter. I would use a VSAN for Server Disk IO (Boot and Datastore) then perhaps a 2nd VSAN for Backup/Replication/Tape etc..
Regards
Colin
Hello.
Is it possible to connect 3rd party servers to Fabric interconnects using fc hba in FI fc switch mode?
Is it supported by cisco?
Thank you
Hi Dzmitryj
Does it work? Yes
Is it supported? Depends
I would think Cisco would not support issues with your 3rd party server connecting into the Fabric, but would support the directly attached Array (As long as it was on the HW compatibility Matrix)
3rd Party Ethernet servers attaching to Appliance ports on the other hand is potentially a different story. With the release of the C3160 Storage Server, It is obvious that this Server could in fact be any Ethernet host. So while I doubt Cisco would broadcast and fully support the fact that you can plug any Ethernet based server into an appliance port, I would expect Cisco to at least agree that they would support network connectivity to a 3rd party server.
Watch this space..
Colin
Hi UCS Guru,
What is the best practice way to configure VNICs with vSphere. I’ve seen it recommended to use Fabric Failover with just one VNIC or two VNICs to a vSwitch. I’ve also seen configs showing fabric failover disabled.
Thanks
Hi Brian
Have a search back through previous questions, as I did a very long concise answer to this question a while back.
But in essence only use Fabric Fail over or operating systems that to not inherently support NIC Teaming.
It is far better to use 2 vNICs (A&B) in either and Active/Active or Active/Standby configuration.
Most operating systems and vSwitches (vDS, N1KV etc..) have provision for multiple uplinks and can cope with an uplink failure. And importantly will notify the Host / VMware admin that a failure has occurred.
If you use Fabric Failover any failure of the vNIC or path will be transparent to the OS and will just be failed over behind the scenes. I’m of the view that if there is an failure somewhere the Host admin would generally want to know about it.
The only exception to the above rule, is when you wish to localize intra subnet traffic within a Fabric Interconnect, but still protect the service.
A good example would be vMotion where you want to minimize traffic exiting the FI to be switched between fabrics upstream.
Instead create a single vMotion vNIC for each host, and map them all to the same fabric, this way all vMotion traffic will hairpin within the FI. You would then protect all the vMotion vNICs with Fabric Failover, in which case in the event of a fabric failure, all vMotion vNICs will just failover to the other fabric.
That said, many customers don’t really mind if their vMotion traffic takes an extra layer 2 hops, but same use case can be applied to any time sensitive application.
Regards
Colin
hy guru!
when i try to log in the ucsm, i gave login config/config. But i got a message every time in the login option:
login error
failed login info: UCSM is not available on secondary node
please tell me how to solve this problem.
Hi Zahid
That’s not a problem, you are trying to login into UCS Manager on the subordinate Fabric Interconnect, login to the cluster address and you will be fine.
You can of course login to the subordinate FI via CLI for troubleshooting purposes.
Regards
Colin
I have a question. I want to create an L3 interface between my switch 4500 and switch 6248 UP which is inturn connected to UCS-B Server. Iam trying to make my network a pure L3 switched network. how to do it.
Hi not currently possible, Cisco UCS FI uplinks can only be layer 2
Regards
Colin
Hi colin,
We are facing a problem in ucs B200 M4 series blade server, After installation of Windows OS 2012 R2 in that server Os getting crash after installation completion
Can you please on this issues….?
Hi
Iam configuring linux clients on UCS-B200-M3 blades and I see the below issue. Please kindly help out.
When VQE software residing on a linux device (VM created on UCS-B200-M3) issues a multicast join to the multicast source, there is a heavy delay (around 800ms) seen in doing multicast join.
I see this delay on all the 3 VMs created on UCS-B200-M3 Blades. There is no delay seen on a normal linux Client (not a VM). I suspect this to be a VM setting or UCS-FI-6248-UP (Fabric interconnect) settings. I have debugged the issue on the edge router and there is no issue in it.
Network Topology
Multicast Source(IO3 Port3 : 5.1.8.2) –> (Gi1/8 : 5.1.8.1) cat 4948 (Gi1/49 : 7.2.7.2) –> (Te2/7 : 7.2.7.1) cat 4500 (Po2 : Te2/1 & Te2/2 Trunk) –> (Po1 Eth1/31 & Eth1/32) UCS-FI-6248-UP (Blade-3 vNIC2 & vNIC3 Vlan9) –> (vmnic1 & vmnic2 Vlan9) VM (Linux host eth1 Vlan9)
—
Regards
Niranjan
Hi UCS Guru. kindly request you to give me an answer. iam waiting for your reply. my entire work is blocked because of this issue. kindly respond.
Hi UCS Guru. kindly request you to respond to my question. Your help is kindly appreciated. Iam eagerly waiting for your reply.
Just found this site, Great work! I’ve got an easy one for you 🙂
I am noticing these errors in my UCS domains, they seem to be common across sites, emc, hitachi, vmware, hyperv, vblock, certified and validated environments. I’m wondering if anyone else is getting these? Im trying to check a few other environments to make sure its not a fluke.
I have cases open with Cisco, Hitachi, Microsoft, etc. All have come back with the ol, its not me, its someone else.
I start by doing a techsupport files dump on chassis (defaults)
Open the logs, pick a MEZZXX card. Open obfl and view the syslog file.
We are seeing a LOT of these errors across all mezz cards across mutiple firmware versions 2.2(1d) and greater across 8 separate domains
ecom.ecom_main emcom(4:1): abort called for exch XXXX status 3 rx_ ……
ecom.ecom_main emcom(4:1): abort called for exch XXXX status 3 rx_ ……
ecom.ecom_main emcom(4:1): abort called for exch XXXX status 3 rx_ ……
ecom.ecom_main emcom(4:1): abort called for exch XXXX status 3 rx_ ……
etc, flooding logs in some cases
We are not seeing any symptoms, issues, performance or anything negative but errors are making people nervous.
Im not after a fix, but im curious if others are getting these errors also across different environments?
This outlines this, all my firmware versions are above this.
https://tools.cisco.com/bugsearch/bug/CSCum10869/?referring_site=bugquickviewredir
What are your thoughts on this? Should I be worried? If i can validate that others with completely different environments are getting these errors, this would allievate any stress by boss has. Im cool tho (untill something breaks).
Interestingly, I have one chassis out of the 8 that has ZERO of these errors across the entire infrastructure.
Your thoughts on this would be great, ta
Hi Scott
In my experience “aborts” are usually dodgy optics(sfps) or cables.
I would pick one host where you are seeing aborts and isolate it to a single fabric and path by disabling all the other paths in the service profile and re-check the tail of the adapter log file for aborts.
e.g
ucsfi-A# con adapter 1/1/1
adapter 1/1/1 # connect
adapter 1/1/1 (top):1# show-log 50
Then try the additional paths one by one.
You should also connect NXOS into both FI’s and do a “show interface counters errors” and confirm all are “0” (you can do a clear counters first)
Also run the above command on the upstream switch(es) to check for drops.
Regards
Colin
Hi,
I have created service profile with 4vHBA, when I attached to CISCO UCS M200 blade, it throwing config error, stating that HBA not available, but if I remove the 2HBA then I am able to attach, why?
Hi Siva
I would check you have enough WWPN’s available in you pool.
I assume it is a Cisco VIC card you have and not one of the 3rd Party compatible cards which only support 2 x vHBA’s
Regards
Colin
Hi Colin,
I am very new to this Cisco UCS and fully confused with WWN,WWNN,WWPN,vNic,vHba etc.
will you please help me to understand??
Thanks in advance
Regards,
Firoz
Hi Firoz
Simply put the WWNN (World Wide Node Name) is the Host (Blade) identity (1 per Blade assigned)
WWPN (World Wide Port Name) is assigned to each port (1 per vHBA assigned, and these are the identities you include in your zoning.
The vNIC and vHBA are simply virtual LAN and SAN Adapters created on the Virtual Interface Card (VIC) within the UCS Server.
vNICS are assigned a MAC Address
vHBA’s are assigned a WWPN Address.
Loads of info on this in the questions section, grab a cuppa and have a sift through.
Colin
Dear UCS Guru
I’ve spoken to numerous Cisco TAC engineers and I cannot get a straight answer on Qualification Policies.
If you plugged in new hardware that satisfied multiple policies, would you see the blade associated with multiple pools?
Say in this simple example,
Server Pool #1 qualification policy – any blade with at least 64GB RAM
Server Pool #2 qualification policy – any blade with at least 128GB RAM
and I plugged in a new 256GB blade/standalone server. What will be the result?
Hi Don
Well please allow me to put your mind to rest.
The answer is Yes, if a server meets multiple qualification polices, then that server will be listed in each pool is qualifies for.
Regards
Colin
Colin
is there any way to change the STP Port Type in use between the nexus 5548 and the fabric interconnects in the VPC
I have a customer wanting to disable BDPU filter from the VPC however in the standard stp mode type edge trunk port for the vpc between the two switches disabling this fails the port channel
Can we disable the BDPU filter for the VPC etc
Michael
Hi Michael
In End Host Mode, the FI’s do not send BPDU’s or participate in STP.
As such the Nexus ports should be configured as Edge Trunk ports.
Unless your FI’s are in Switch mode, which is not recommended and doesn’t really have a use case anymore so I won’t go into it here.
Fire back if you need more info.
Regards
Colin
I have a question regarding FI upgrade. Currently its running 2.1.1f. When I upgrade to 2.1.3j, will the nx-os component (currently 5.0(3)N2(2.1f) will also get upgraded or do I need to do it separately?
Hi Jeejish
Any underlying NXOS updates ate part of the FI firmware, you never need to upgrade the NXOS separately.
Regards
Colin
I was wondering how most people go about monitoring their standalone c240’s for hardware alerts such as disk failures, bad power supplies, etc? I see the option in cimc for sending to a remote syslog server. Other hardware platforms have free products (Dell OpenManage, HP Systems Insight Manager-OneView). I have not however found a comparable product that is offered by Cisco.
Hi Colin,
I have this error while trying to install win 2008 on boot LUN on B200M4
I can see the LUN after loading driver
I’m using one path to SAN
but when trying to install I got error
windows cannot be installed to this disk. This computer’s hardware may not support booting to this disk. Ensure that the disk’s controller is enabled in the computer’s BIOS menu.
Is something is needed on storage side ?
Thanks
Hi
Yes have seen this issue before.
If you have local disks in the blade pull them out for the install, ensure you only have a single path to the LUN, and then make sure you hit “Refresh” in the Windows installer, after remapping the Windows intsaller ISO and Cisco driver ISO.
Regards
Colin.
I have a question regarding moving the LAN uplinks in a production environment. Currently the FI are connected to a pair of Nexus 5010 in vPC peer configuration. The 5010’s are the connected to a pair of Nexus 7010, also in vPC peer configuration. We wish to move the UCS environment directly to the Nexus 7010s, if possible, without network interruption. I’ve seen instructions for how you can do a UCS hardware upgrade and thought they could be modified to allow for the move to the 7010 cores.
Steps in short:
1 – power off subordinate FI
2 – Move uplinks to from 5010s to 7010s – FI ports remain the same. 7010 ports configured the same as 5010 uplink ports (maybe with different vPC number).
3 – Power own subordinate FI. (Not sure how best to test)
4 – Force a fail-over to the subordinate FI. Verify functionality
5 – Repeat step 2 and power back on.
Thanks in advance for any help you can provide.
Hello,
What are the possible causes on why my CIMC does not show any inventory information on the CPUs nor memories option, is showing all blank.
Sounds like you may need to Re-acknowledge the server to force a rediscovery.
Regards
Colin
Neat little UCS mini package?
I have a ucs mini setup with a c240 M3 connected to the UCSM as server ports to the 6324 mini FI switches (both a and b).
My question is can the 8 b200m1 servers in the chassis use the C240 M3 4.5 Terabytes of raid 10 disk as boot storage etc? I was hoping this would work as the C240 M3 could subsitute for a separate SAN device? No?
It’s certainly not a recommended setup, but if the OS on the C240M3 supports presenting the storage as iSCSI targets, then I can’t see what that wouldn’t work. Perhaps give it a test with an OS like OpenFiler or somthing.
Regards
Colin
Hi,
We have FI 6332 and only C series rackmounts c240M4SX connected to it.
we have installed the C port licenses. 16 in total. But the ports in FI, instead of consuming these licenses, they are using the default eth package license supplied by cisco. because of this we are running into graceperiod.
can you help out please?
Hi Nithin.
Not an issue I’ve run into yet, so one for TAC.
Regards
Colin
Hi again Colin,
Can you please help me, I cant seem to sort out an issue I’m having.
Trying to associate a service profile to a B200-M3 blade with a ViC 1240 adapter.
it is failing at 25%
Remote Invocation Result: End Point Unavailable
Remote Invocation Error Code: 869
Remote Invocation Description: Adapter:unconfigAllNic failed
seems the DCE is not seeing the B-Side of the chassis
please help!
Hi,
Need your expertise to understand how exactly VCON policy works in UCSM and is it possible to use it for failover purpose?
Regards,
Ankush Khanna
I discuss the use of vCons in my blog post:
Real World Cisco UCS Adapter Placement https://virtuallymikebrown.com/2014/10/29/real-world-cisco-ucs-adapter-placement/
Hi,
Our new environment has UCS servers, which will boot from local disk. Also we have external storage system(SAN) for data.
We haven’t Installed OS yet on the hosts, up on powering up hosts without OS it doesn’t shows Flogi’s on SAN switch. does it requires to have OS installed before, so HBA’s pops up on SAN switch?
Hi Abdul
No as you can boot from SAN, you should see the Flogis on the SAN switch when the UCS initialises the vHBA as part of the POST.
You will also see the LUN it finds if you have already zoned and presented the storage to the UCS WWPN.
I would first check you see your WWPN in the FI with the “show npv flogi table”
The FI will then use your configured FC SAN links for the relevant VSAN to flofi into the upstream SAN switch.
Good Luck
Colin
I have two vnic templates (updating) but both are pointed to FI-A. I want to change the second vnic template to point to FI-B. Both have failover enabled. If I swap the second vnic template to FI-B will this cause a network outage in my VMware infrastructure?
Hi Jeff, yes changing the fabric of a vNIC (even via a template, which could effect multiple servers) will require a server reboot. If your maintenance policy is set to user ACK you can change the setting and then vacate any VMs (maint mode) each host in turn and then acknowledge the reboot on server at a time via UCSM.
Regards
Colin
Hi Jeff,
It will be disruptive as you are moving vnic template to second FI. It will be doing vnic pinning on second FI. If you got your failover configured over OS or uplink to UCS it may not be disruptive but your failover is configured on UCS itself so modifying vnic binding will result in traffic disruption.
Please check if failover is configured for vnic in your service profiles or not.
Vnics are placed globally or not.
There is a way to modify vnic placement without disruption but it got some requirements as well.
Thanks and Regards.
Neeraj Sharma
Cisco TAC
Can you help me get passed this failed verification during HX Create Validation — “Verify Storage VLAN and MTU is configured correctly on upstream switch. If not configured, cluster will lose connectivity during any network failover event.”
The network admin added the VLAN and I assume the MTU but it still fails. I thought the storage vlan was supposed to be private and would not traverse out the FI’s anyway?
I’ve been reading about iSCSI TLV technology and I was wondering if it does matter if the server has to understand that protocol and if cisco UCS supports it, how we can enable and manage it?
Thanks
Is there any solutions if all fan on cisco server UCS C220 M4 are not working but system running?
Similar issue for us, the system works for a while until the temperature passes threshold. All the fans on 2 servers failed at the same time, I am trying to reach Cisco, but could this be related to some firmware issue instead of a hardware?
I have installed ESXi 6.5 U2 (the special Cisco version) on our Cisco UCS S240-M3 server.
We can not connect to any network through the on board Ethernet adapters (LOM).
I have link lights but, no communication at all. Will the Vmware ESXi work with the on board NICs or do we need to install a different type of NIC in the server. This server will be used for disaster recovery.
Hi,
Do we need set any specific settings for adapter policy of the overlay nics for iSCSI? or for example if the host is vmware selecting vmware will suffice?
Thanks,
Hello. Can i create cluster from cisco ucs 6296 UP and ucs 6248 UP or they must be both the same models?
Thanks
It does work, but running a mixed cluster is only supported for a short period while migrating.
Colin
Thanks a lot
Do you have any experience using an SD card larger than 32GB in a B200 M3? We’re looking to use 128GB cards, but wanted to confirm there would be no issues before ordering them. They would obviously be 3rd party cards. The part ID is SDCS/128GB and they would come with the adapters needed to fit the MicroSD card in to the SD card slots in the server.
I have only ever used Cisco SD Cards, obviously it’s just a standard SD card slot so 3rd party and larger cards will likely work, obviously you have no support from Cisco if you run into issues with them though.
Colin
I am unable to get my UCS C220 M4 server CIMC IP, how can i capture the IP details while rebooting the serve?
Press F8 when booting the server, will take you into the CIMC settings.
Colin
Let me correct the above as it was type in a rush:
What happens when too many failed login attempts are experienced by a UCS M4 node, does it lock itself or disconnect from network? Had an incident where my host was taking forever to respond when i attempted to login and servers hosted on it were not accessible at all. When i checked the physical box it was alarming on network, i rebooted the unit and everything came back online. But i lost events on the box for me to see the cause of that issue.
trying to figure out what could have caused this – network light was flashing amber and network team claim all was well!
Hi
We have UCS 260 M2 CISCO device and i have edited the mdadm.conf file by commenting out Array md3 lines and after rebooting the server i get the error message saying
The following VDs are missing: 04
If you proceed (or load the configuration utility), these VDs will be removed from your configuration.If you wish to use them a later time, they will have to be imported. If you believe these VDs should be present, please power off your system and check your cables to ensure all disks are present. Press any key to continue, or ‘C’ to load the configuration utility.
And we have one failed hard disk on the machine. Before commenting out the lines i was able to get to a point with “repair fail system:” because of the failed drive. After commenting out the md3 lines for vi /etc/mdadm.conf i get the above error & i am not able to get to “repairfilesystem:” to revert my changes by uncommenting the md3 lines from the mdadm.conf file.
What should i to revert uncommented lines in mdadm.conf file ? Please advise.
Thanks
Hello,
I am a network trainer. I have purchased two FI6120XP that are currently running under UCS Manager 2.2 (1c) unless I am mistaken. Is it possible to update it to version 3?
Thank you.
Afraid not the last supported code for Gen 1 HW is 2.2(8l)
Starting with Cisco UCS Manager Release 3.1(1e), Cisco UCS Manager does not support the hardware listed in the following table:
Fabric Interconnects
UCS 6120 (N10-S6100)
UCS 6140 (N10-S6200)
Regards
Colin
Hi UCSGuru, I’m adding a Mini UCS 6324 to an existing 6248UP. is there a way to manage both. I want the new chassis to be part of the existing UCS management so I can share the same profiles and configs?
Thanks,
The UCS Mini has separate FI’s (6324) so you can’t connect it to a 6248UP. What you would need to do is connect them both to your Top of Rack switches or Network and then use UCS Central or Intersight to manage both UCS Domains and share service profiles between them.
Regards
Colin
Hi,
i want to ask if it’s posibble to move, relocate two ucs5108 chassis one by one to another floor?
i have two ports connected to each of Io module like :
fabric A port 1 connected to io module left port 1
fabric B port 1 connected to io module left port 2
fabric A port 2 connected to io module right port 1
fabric B port 2 connected to io module right port 2
and the chassis 2 the same port 3 and 4 from fabric interconnect.
Also i have 2 mds switches connected to both fabrics
SW1 to fabric A and B and SW2 to fabric A and B
What i want to ask is if i migrate all vms to chassis 1 and i power off the chassis 2
and i power off the secondary fabric interconnect and the secondary mds move them to another rack and then connect the chassis to fabric interconnect the sync link between fabric interconect if will be a long cable distance will work? because it’s like 50 Meters between racks.
And if the connections from io module of chassis2 to fabric A will transport them over fiber at the same distance (50 m) will work to power up and migrate all to chassis 2 ?
After migrate do the same with fabric A and UCS chassis 1, move it to relocation rack ?
Thanks,
Hi Florin
Yes that could work if you really can’t find a maintenance window to just move all the kit in one go.
You are subject to the normal cable lengths limits for your particular media, 50M copper is fine.
Regards
Colin
Hi..
Going through some trouble with hx systems one node was switched off. Once rebooted it is not able to access datastore. It is an hx 220c m5 with win 2016 and is a hyperv failover cluster.
Hello and what a great resource site. I have built and administered a few UCS environments all with FI’s.
I am about to do my first Hyperflex Edge environment with Nexus 3k Stacked switches. I have read the best practices and build documents, but would it be possible to get a Switch config template for a baseline for me. The servers will be 220 M5 all flash, 3 of them. The switches are Nexus 3524 and we will be using a 10 G quad port card in each server. I plan on having CIMC and Management share the same VLAN and statically assign for the CIMC.
thank you in advance
Dear UCS guru,
I have a question regarding the upgrading ESXi drivers on my UCS C220 M4S. I had issues with SAS Raid Controller and I opened a TAC case. TAC engineer answered me that a need to upgrade lsi_mr3 driver to a newer version and he sent me a download link for ISO file with all drivers. My question is: In which way a can do that upgrade? Can I mount that ISO file via KVM console and perform a reboot, F6 for boot menu, … or there is another way? This is my production environment so, I cannot afford mistakes.
Thank you very much for your time and answer!
PS. Sorry for my English
Nice regards,
Drago
Hi,
Could you help to find root cause of the failure:
A: UP, PRIMARY
B: DOWN, INAPPLICABLE
A: memb state UP, lead state PRIMARY, mgmt services state: UP
B: memb state DOWN, lead state INAPPLICABLE, mgmt services state: DOWN heartbeat state SECONDARY_FAILED
INTERNAL NETWORK INTERFACES:
eth1, UP
eth2, UP
HA NOT READY
Peer Fabric Interconnect is down
Detailed state of the device selected for HA storage:
Chassis 1, serial: xxxxx, state: active UCS01-UA-A(local-mgmt)#