If “Software Defined X” has been the hot topic over the last couple of years then “Hyperconvergence” is certainly set to be one of the hottest topics of 2016, like most buzzwords it’s a very overused term, the word even has “hype” in the name, hell, even as I type this post auto complete finished off the word after only 2 characters.
This market has been so confusing with so many overlapping offerings and players coming and going, alliances forged and broken and like all intensely competitive markets there has been a long line of casualties along the way, but from all this competition hopefully it should be the consumer that emerges the real winner. I did think about doing an elaborate “Game of Thrones” esque opening credits video showing all the key players, but my CGI skills aren’t up to much so just pretend I did it.
So before we get stuck in, what is Hyperconvergence?
Well traditionally a hyper-converged infrastructure (HCI) is modular compute building blocks with internal storage, plus a magical hyperconverged software layer than manages the compute and storage elements, abstracts them, and presents them to the Application as virtual pools of shared resources. This facilitates and maximizes resource utilization at the same time minimizing wastage and inefficiency. And it is this magical hyperconverged software layer that is generally the differentiating factor in the plethora of offerings out there. I say “traditionally” as you may notice there is a critical element missing from the above definition. Which I will cover later in this post.
The rise in popularity of hyperconverged offerings, is also due, in part to the ability to scale from small to very large deployments as well as negating the requirement for a complex enterprise shared storage array, thus minimizing the initial upfront Capex costs and allowing a “Pay as you Grow” cost model, which actually increases in efficiency and performance the larger it scales due to its distributed nature.
While Cisco are well established in the integrated Systems markets, contributing network and compute to the converged Infrastructure offering of Vblock, VxBlock and Integrated Systems like FlexPod, there has always been a bit of a gap in their hyperconverged portfolio, sure there is the OmniStack partnership with SimpliVity, but nothing as far as a complete Cisco HCI offering goes.
Introducing The Cisco HyperFlex System

Today Cisco announced their new hyperconverged offering in the form of the Cisco HyperFlex System, a complete hyperconverged solution combining, next generation Software Defined Compute, Storage and Networking, thus providing a complete end-to-end software-defined infrastructure, all in one tightly integrated system built for today’s workloads and emerging applications.
I say complete hyperconverged offering as the Cisco HyperFlex System, also comes with full network fabric integration. One of the significant competitive advantages the Cisco HyperFlex System has over other HCI offerings that do not integrate or even include the network element. In fact if the fabric isn’t part of the solution, is the solution really even hyperconverged?
HyperFlex is built from the ground up for hyperconvergence, leveraging the Cisco UCS platform, along with software provided by Springpath, a start-up founded in 2012 by VMware veterans. This hyperconverged software is fully API enabled and has been branded the HX Data Platform
If being a bit late to the hyperconverged party has had one advantage, it’s that Cisco have had time to listen to customers about what they felt is lacking in the current generation of hyperconverged offerings and to properly address the architectural shortcuts and design trade offs made by some other Vendors in order to get to market quickly.
And with HyperFlex, Cisco feels they have leap-frogged any other HCI offering out there by some 2 – 4 years!
Key features of the Cisco HyperFlex System
There are so many features covered in the announcement today, each worthy of a blog post in their own right, which I will no doubt cover here, once more details are released and I can actually get my hands on one to play with. But until then, here is the list of the HyperFlex features that most caught my eye.
- Simplicity And Easy Independent Scaling.
Cache and Capacity can be scaled up within nodes, or additional nodes can be added, thus allowing compute and capacity to be completely independently scaled up and out as required. Whereas traditional hyper converged solutions only scale in a linear form i.e. you are forced to add both compute and storage in fixed ratios, even if you only need to scale one of them.

New cluster nodes are automatically recognized and are added to the cluster with a few mouse clicks.
Cisco claim that is possible to stand up a Cisco HyperFlex System, including all the networking in under 1 hour, well I’ll certainly look forward to testing that claim out.
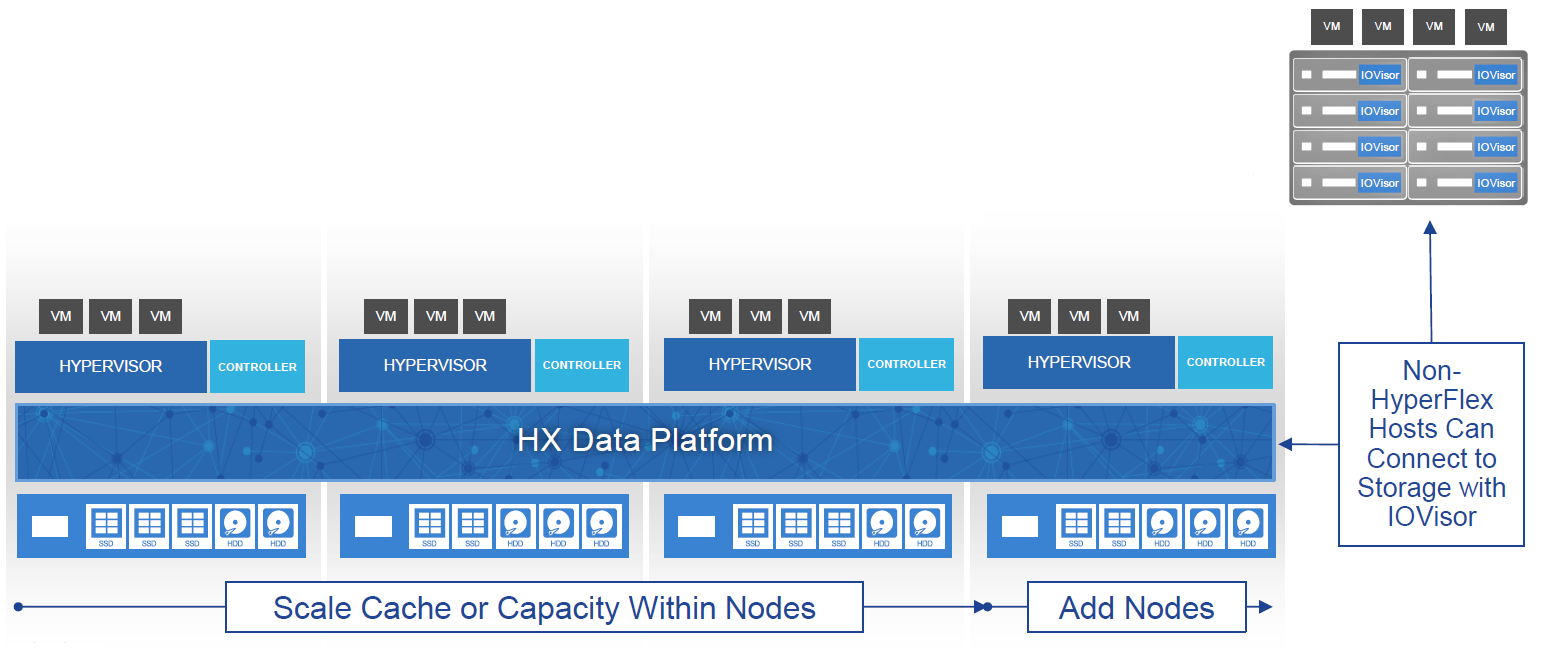
The HX Data Platform is implemented using a Cisco HyperFlex HX Data Platform controller which runs as a VM on each cluster node, this controller implements the distributed file system and intercepts and handles all I/O from guest virtual machines.

HX Data Platform Controller
The HX nodes connect to the hyperconverged presented storage via 2 vSphere Installation Bundles (VIB) IO Visor & VAAI, within the hypervisor that provides a network file system (NFS) mount point to the distributed storage.
The IO Visor VIB can also be loaded on a non HyperFlex node to provide access to the Hyperconverged storage to add additional compute power in a Hybrid solution.

- Superior Flash Endurance.
Built upon a Log-structured file system, enables superior flash endurance by significantly optimizing writes and reducing program/erase cycles.
- Dynamic Data Distribution
Unlike systems built on conventional file systems which first need to write locally then replicate, creating hot spots, the HX Data Platform stripes data across all nodes simultaneously. It does this by first writing to the local SSD cache, the replicas are then written to the remote SSD drives in parallel before the write is acknowledged.
For reads if the data happens to be local it will usually be read locally otherwise the data will be retrieved from the SSD of a remote node, thus allowing all SSD drives to be utilised for reads eliminating I/O bottlenecks.
- Continuous Data Optimization.
The always-on inline deduplication provides up to 30% space saving followed by inline compression which provides up to an additional 50% space saving and all with little to no performance impact. And did I mention it’s always-on? Nothing to turn on or configure.
And these figures do not even include the additional space savings achieved by using native optimized clones and snapshots, if it did the overall space saving would be circa 90% or more.
This combined with thin provisioning gives the most efficient use of the storage you have, so you only need buy new storage as you need it.
- High reliance and fast recovery
Depending on the chosen type of replication mode, based on maximizing availability (Replica Mode 3) or capacity (Replica Mode 2 ) the platform can withstand the loss of 2 HX nodes without data loss. Virtual machines on failed nodes simply redistribute to other nodes via the usual vSphere methods, with no data movement required. Then with the combined functionality of stateless service profiles and the built in self-healing within the HX Data Platform the replacement node is simply and dynamically replicated back in, again with no data movement required which eliminates the issue of sessions pausing/timing out in solutions which rely on data locality, which attempts to locate the data on to the hosts that are using it.
100% Administered via the Cisco HyperFlex HX Data Platform Administration Plug-in for vCenter. This plugin provides full management and monitoring of the data platform health as well as providing data which can be used to determine when the cluster needs to be scaled.
The initial UCS Manager elements can also be managed via the often forgotten UCS Manager Plugin for vCenter.
There will also be a UCS Manger wizard, to guide the user through the initial UCS Manager configuration of pool address population and Service Profile creation, something I’m sure we will see in UCS Classic not long after.
At FCS vSphere with File based storage will be supported on the Cisco HyperFlex System, with Block and Object based storage planned for the future, along with Hyper-V, Bare Metal and Container support.
- Built on industry leading Cisco UCS Technology
Cisco UCS now tried, tested and trusted by over 50,000 customers worldwide
The Cisco HyperFlex System will come with Gen 2 6248UP or 6296UP Fabric Interconnects (FW 2.2(6f)), with the Gen 3 Fabric Interconnects already released and waiting to provide 40-Gbs connectivity to the Cisco UCS as and when data throughput demand increases within the HyperFlex system.
While the network with many HCI offerings is at best an afterthought, or at worst not even included, with the Cisco HyperFlex System, the network is fully integrated and optimized for the large amount of east/west traffic required in a hyperconverged system. With every HyperFlex node just a single hop away providing deterministic and consistent performance.
Having Cisco UCS as the solid foundation for the platform also provides a single central management system for both integrated and hyperconverged infrastructure as well as offering integration with Cisco UCS Director and UCS Central.

As can be seen from the above diagram there are 2 models of HyperFlex rack mount nodes each requiring a minimum cluster size of 3 nodes. The 1U HX220c ideal for VDI and ROBO use cases, and the 2U HX240c for Capacity heavy use cases, with a third hybrid option for combining Blade and Rack mounts for compute heavy workloads.
HX220c M4

HX220c M4
Each HX220c Node contains:
2 x Intel Xeon E5-2600 v3 Processors (up to 16 Cores per socket)
Up to 768 GB DDR4 RAM
1 x 480GB 2.5inch SSD Enterprise Performance (EP) for Caching
1 x 120GB 2.5 SSD Enterprise Value (EV) for logging.
2 FlexFlash SD cards for boot drives and ESXi 6.0 hypervisor (ESXi 5.5 also supported)
Up to 6 x 1.2TB SFF SAS Drives contributing up to 7.2 TB to the cluster.
1 Cisco UCS Virtual Interface Card (VIC 1227)
HX240c M4

HX240c M4
Each HX240c M4 Node contains:
1 or 2 x Intel Xeon E5-2600 v3 Processors (up to 16 Cores per socket)
Up to 768 GB DDR4 RAM
1 x 1.6TB 2.5inch SSD Enterprise Performance (EP) for Caching
1 x 120GB 2.5 SSD Enterprise Value (EV) for logging.
2 FlexFlash SD cards for boot drives and ESXi 6.0 hypervisor (ESXi 5.5 also supported)
Up to 23 x 1.2TB SFF SAS Drives contributing up to 27.6 TB to the cluster.
1 Cisco UCS Virtual Interface Card (VIC 1227)
Common Use Cases
Looking at what the Early Access Customers, are doing with HyperFlex by far the main use case looks to be VDI. The low up front cost, consistent performance and user experience along with Predictable Scaling certainly make HyperFlex an ideal solution for VDI.
Also high on the list was Test/Dev environments, features like Agile Provisioning, instant native cloning and native Snapshots make a compelling case for entrusting your Test/Dev environment to HyperFlex.
And while the above are two compelling use cases and sweet spots for HyperFlex I’m sure as customers experience the ease, flexibility and scalability of the HyperFlex System we will see it used more and more for mixed workload general VM deployments as the resilience and performance is certainly there for critical applications.
Remote Office Branch Office (ROBO) also was mentioned all though I would think this would likely be a larger remote office , as any use case requiring only 2 or 3 servers, would likely be more cost effectively served with the current UCS C Series in conjunction with StorMagic SvSAN
Pricing:
With an initial bundle price for 3 x HX220c nodes, including a pair of Fabric Interconnects expected to be circa $59,000 which also includes the first year’s software subscription, Cisco are obviously dead set on making this a compelling solution based not only on outstanding Next Gen functionality, performance and agility but also on cost.
Other Questions you may be thinking about
Now as with all new products, a line has to be drawn somewhere, for that First Customer Ship date. Only so much validation, testing of various hardware combinations, features and scale limits can be conducted.
Now I’m a curious chap, and I like to ask a lot of questions, particularly the questions I know my readers would like the answers to.
The running theme in the answers from Cisco to most of my “Could I” questions was that they wanted to get it right, and ensure that the product was as optimized as possible and that Cisco were not prepared to make any compromises to user experience, performance or stability by casting the net too wide from day 1.
All answers are paraphrased.
Q) Will HX Data Platform be available as a software only option?
A) No HX Data Platform will only be offered preinstalled on the badged HyperFlex HX nodes.
Q) Can I just load the HX Data Platform on my existing UCS Servers if I use the exact spec of the HyperFlex branded ones?
A) No (see above answer)
Q) Are there any hardware differences in the HX nodes and there equivalent C Series counter parts?
A) No, but the specification and settings are highly tuned in conjunction with the HX Data Platform
Q) Will I be able to mix HX220c and HX240c in the same HyperFlex Cluster?
A) Not at FCS, all nodes within the same cluster need to be identical in model & spec.
However each Cisco UCS Domain supports up to 4 separate clusters, and each of those clusters could be optimised for a particular use case or application. for example:
Cluster 1: Replica Mode 2 on HX220c to support Test/Dev workloads
Cluster 2: Replica Mode 3 on HX240c to support Capacity heavy workloads
Cluster 3: Replica Mode 3 on HX240c and B200M4 to support Compute heavy workloads
Q) Why is the maximum HX cluster size 8?
A) 8 seemed a reasonable number to start with, but will certainly increase with additional validation testing. While the initial Cluster size is limited to 8 HX nodes per cluster, with the Hybrid option an additional 4 classic B200M4 Blades can be added for additional compute power, giving a total number of servers in a Hybrid cluster of 12. In the Hybrid solution the B200M4 local storage is not utilized by the Cisco HyperFlex System..
Q) Will I be able to have a mixed HyperFlex and non HyperFlex node UCS Domain?
A) Not at FCS, HX Nodes will require a separate UCS Domain, except for the 4 supported blades in the hybrid model
Q) Are FEX’s supported to connect in HyperFlex nodes to the FI’s?
A) Not at FCS, but no Technical reason why not, once validated, but oversubscription of FEX uplinks needs to be considered.
Q) Will the 3000 Series Storage Optimized Rack Mount servers (Colusa) like the 3260 be available as HyperFlex nodes.
A) Not at FCS, These Servers are more suited to lower performance, high capacity use cases like archiving, and cold storage. Plus that the 3000 series servers are managed via CIMC and not UCSM.
Q) Can I setup a Cisco Hybrid HyperFlex System by directly connecting the HX nodes to my UCS Mini?
A) Not at FCS
Closing thoughts
Both the Converged and Hyperconverged markets continue to grow and will co-exist, but with HyperFlex Cisco have certainly strengthened what was the only chink in their armour, meaning that there is now a truly optimized solution based on a single platform under a single management model for all requirements and use cases. Providing many HCI features not available until now.

One thing is clear the Hyperconverged game changes today!
Until next time.
Colin
Keep up to date with further HyperFlex announcements on social media by following the hashtag #CiscoHX